Java 8 特性
Java 8 特性
文章目录
- Java 8 特性
- 函数式编程
- 函数式编程让代码更灵活
- 1、初始需求:筛选出绿苹果
- 2、 变更需求:根据颜色筛选苹果----->修改初版方法
- 3、追加需求:根据重量筛选苹果----->追加方法
- 4、追加需求:根据颜色和重量筛选苹果----->追加方法
- 5、使用接口抽象筛选行为
- 6、使用匿名类
- 7、使用Lambda表达式
- 8、将 List 类型抽象化
- Lambda 表达式
- 简洁地表示可传递的匿名函数的一种方式
- 在哪里以及如何使用 Lambda
- 函数式接口
- 把 Lambda 付诸实践:环绕执行模式
- 1、行为参数化
- 2、使用函数式接口来传递行为
- 3、执行一个行为
- 4、传递 Lambda
- java8中常见的函数式接口
- 原始类型特化
- 异常、Lambda,还有函数式接口又是怎么回事
- 类型检查、类型推断以及限制
- 类型检查
- 同样的 Lambda,不同的函数式接口
- 类型推断
- 使用局部变量
- 对局部变量的限制
- 方法引用
- 如何构建方法引用
- Lambda 和方法引用实战
- 第 1 步:传递代码
- 第 2 步:使用匿名类
- 第 3 步:使用 Lambda 表达式
- 第 4 步:使用方法引用
- 复合 Lambda 表达式的有用方法
- 比较器复合
- 谓词复合
- 函数复合
- Steam 流
- Stream本质
- Steam 和 for循环
- 流操作
- 中间操作
- 终结操作
- 使用流
- 筛选和切片
- 映射
- 查找和匹配
- 归约(reduce)
- 无状态和有状态
- 流操作
- 数值流
- 原始类型流特化
- 数值范围
- 构建流
- 用流收集数据
- 收集器
- 归约和汇总
- 分组
- 分区
- Collectors 类的静态工厂方法
- Collector 接口
- 并行数据处理与性能
- 接口中的默认方法
- Optinal 取代 null
- CompletableFuture
- 日期时间API
函数式编程
- 函数式编程中:函数式一等公民,即函数可以作为方法的参数或者返回值
- java中值是一等公民,(基础类型和对象的引用)
- java中一切皆对象的理念,为了传递函数,所以使用函数式接口来描述函数
函数式编程让代码更灵活
举一个从库存中筛选苹果的例子
1、初始需求:筛选出绿苹果
public static List<Apple> filterGreenApples(List<Apple> inventory) {List<Apple> result = new ArrayList<Apple>();for (Apple apple : inventory) {if ("green".equals(apple.getColor()) {result.add(apple);}}return result;}
2、 变更需求:根据颜色筛选苹果----->修改初版方法
public static List<Apple> filterApplesByColor(List<Apple> inventory,String color) {List<Apple> result = new ArrayList<Apple>();for (Apple apple : inventory) {if (apple.getColor().equals(color)) {result.add(apple);}}return result;}
3、追加需求:根据重量筛选苹果----->追加方法
public static List<Apple> filterApplesByWeight(List<Apple> inventory,int weight) {List<Apple> result = new ArrayList<Apple>();For (Apple apple: inventory){if ( apple.getWeight() > weight ){result.add(apple);}}return result;}
4、追加需求:根据颜色和重量筛选苹果----->追加方法
public static List<Apple> filterApples(List<Apple> inventory, String color,int weight, boolean flag) {List<Apple> result = new ArrayList<Apple>();for (Apple apple: inventory){if ( (flag && apple.getColor().equals(color)) ||(!flag && apple.getWeight() > weight) ){result.add(apple);}}return result;}
随着需求增加和变更,维护难度增加,使用抽象来优化
5、使用接口抽象筛选行为
//定义一个接口来对选择标准建模
public interface ApplePredicate{boolean test (Apple apple);
}
//仅仅选出重的苹果
public class AppleHeavyWeightPredicate implements ApplePredicate{public boolean test(Apple apple){return apple.getWeight() > 150;}
}
//仅仅选出绿苹果
public class AppleGreenColorPredicate implements ApplePredicate{public boolean test(Apple apple){return "green".equals(apple.getColor());}
}//根据抽象条件筛选
public static List<Apple> filterApples(List<Apple> inventory,ApplePredicate p){List<Apple> result = new ArrayList<>();for(Apple apple: inventory){if(p.test(apple)){result.add(apple);}}return result;
}
使用抽象后,每种筛选都需要一个实现类,太啰嗦
6、使用匿名类
List<Apple> redApples = filterApples(inventory, new ApplePredicate() {public boolean test(Apple apple){return "red".equals(apple.getColor());}
})
匿名类仍能令人不满意,只需要传递一个方法,却创造了一个类
7、使用Lambda表达式
List<Apple> result =
filterApples(inventory, (Apple apple) -> "red".equals(apple.getColor()));
8、将 List 类型抽象化
public interface Predicate<T>{boolean test(T t);
}
public static <T> List<T> filter(List<T> list, Predicate<T> p){List<T> result = new ArrayList<>();for(T e: list){if(p.test(e)){result.add(e);}}return result;
}List<Apple> redApples =
filter(inventory, (Apple apple) -> "red".equals(apple.getColor()));
传递代码,就是将新行为作为参数传递给方法
Lambda 表达式
-
Lambda表达式:可以让你很简洁地表示一个行为或传递代码。可以把Lambda表达式看作匿名功能,它基本上就是没有声明名称的方法,但和匿名类一样,它也可以作为参数传递给一个方法。
-
在Java中传递代码十分繁琐和冗长。Lambda:它可以让你十分简明地传递代码
-
只有在接受函数式接口的地方才可以使用 Lambda 表达式
-
Lambda 表达式所需要代表的类型称为目标类型
简洁地表示可传递的匿名函数的一种方式
-
匿名
- 它不像普通的方法那样有一个明确的名称
-
函数
- Lambda函数不像方法那样属于某个特定的类。但和方法一样,Lambda有参数列表、函数主体、返回类型,还可能有可以抛出的异常列表
-
传递
- Lambda表达式可以作为参数传递给方法或存储在变量中
-
简洁
- 无需像匿名类那样写很多模板代码

- 使用 Lambda 前
Comparator<Apple> byWeight = new Comparator<Apple>() {public int compare(Apple a1, Apple a2){return a1.getWeight().compareTo(a2.getWeight());}
};
- 使用 Lambda 后
Comparator<Apple> byWeight =(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
- Lambda表达式有三个部分
- 参数列表——这里它采用了 Comparator 中 compare 方法的参数,两个 Apple
- 箭头——箭头 -> 把参数列表与Lambda主体分隔开
- Lambda主体——比较两个 Apple 的重量。表达式就是Lambda的返回值了。
- Lambda示例
| 使用案例 | Lambda示例 | 对应的函数式接口 |
|---|---|---|
| 布尔表达式 | (List<String> list) -> list.isEmpty() | Predicate<List<String>> |
| 创建对象 | () -> new Apple(10) | Supplier<Apple> |
| 消费一个对象 | (Apple a) -> {System.out.println(a.getWeight());} | Consumer<Apple> |
| 从一个对象中选择/抽取 | (String s) -> s.length() | Function<String, Integer> 或ToIntFunction<String> |
| 组合两个值 | (int a, int b) -> a * b | IntBinaryOperator |
| 比较两个对象 | (Apple a1, Apple a2) ->a1.getWeight().compareTo(a2.getWeight()) | Comparator<Apple> 或``BiFunction<Apple, Apple, Integer> <br/>或 ToIntBiFunction<Apple, Apple>` |
在哪里以及如何使用 Lambda
- 可以在函数式接口上使用Lambda表达式。
函数式接口
- 函数式接口就是有且仅有一个抽象方法的接口
- 使用
@FunctionalInterface注解标注(不是必须的,作用与@Override类似) - Lambda表达式允许你直接以内联的形式为函数式接口的抽象方法提供实现,并把整个表达式作为函数式接口的实例
//java.util.Comparator
public interface Comparator<T> {int compare(T o1, T o2);
}
//java.lang.Runnable
public interface Runnable{void run();
}
//java.awt.event.ActionListener
public interface ActionListener extends EventListener{void actionPerformed(ActionEvent e);
}
//java.util.concurrent.Callable
public interface Callable<V>{V call();
}
//java.security.PrivilegedAction
public interface PrivilegedAction<V>{V run();
}
- 函数式接口的抽象方法的签名基本上就是Lambda表达式的签名,这种抽象方法叫作
函数描述符 - Lambda表达式可以被赋给一个变量,或传递给一个接受函数式接口作为参数的方法,当然这个Lambda表达式的签名要和函数式接口的抽象方法一样
把 Lambda 付诸实践:环绕执行模式
如何利用Lambda和行为参数化来让代码更为灵活,更为简洁。资源处理(例如处理文件或数据库)时一个常见的模式就是打开一个资源,做一些处理,然后关闭资源。这个设置和清理阶段总是很类似,并且会围绕着执行处理的那些重要代码。这就是所谓的环绕执行(execute around)模式
public static String processFile() throws IOException {try (BufferedReader br =new BufferedReader(new FileReader("data.txt"))) {//做有用工作的代码return br.readLine();}
}
1、行为参数化
现在这段代码是有局限的。你只能读文件的第一行。如果你想要返回头两行,甚至是返回使用最频繁的词,该怎么办呢?在理想的情况下,你要重用执行设置和清理的代码,并告诉processFile 方法对文件执行不同的操作,你需要把processFile 的行为参数化。你需要一种方法把行为传递给 processFile ,以便它可以利用BufferedReader 执行不同的行为。
传递行为正是Lambda的拿手好戏。那要是想一次读两行,这个新的 processFile 方法看起来又该是什么样的呢?基本上,你需要一个接收 BufferedReader 并返回 String 的Lambda。例如,下面就是从 BufferedReader 中打印两行的写法:
String result = processFile((BufferedReader br) ->br.readLine() + br.readLine());
2、使用函数式接口来传递行为
Lambda仅可用于上下文是函数式接口的情况
需要创建一个能匹配BufferedReader -> String ,还可以抛出 IOException 异常的接口。
@FunctionalInterface
public interface BufferedReaderProcessor {String process(BufferedReader b) throws IOException;
}//现在可以把这个接口作为新的 processFile 方法的参数了
public static String processFile(BufferedReaderProcessor p) throws
IOException {…
}
3、执行一个行为
任何 BufferedReader -> String 形式的Lambda都可以作为参数来传递,因为它们符合BufferedReaderProcessor 接口中定义的 process 方法的签名。现在你只需要一种方法在processFile 主体内执行Lambda所代表的代码。请记住,Lambda表达式允许你直接内联,为函数式接口的抽象方法提供实现,并且将整个表达式作为函数式接口的一个实例。因此,你可以在processFile 主体内,对得到的 BufferedReaderProcessor 对象调用 process 方法执行处理:
public static String processFile(BufferedReaderProcessor p) throws
IOException {try (BufferedReader br =new BufferedReader(new FileReader("data.txt"))) {//处理 BufferedReader对象return p.process(br);}
}
4、传递 Lambda
通过传递不同的Lambda重用 processFile 方法,并以不同的方式处理文件了。
//处理一行
String oneLine =processFile((BufferedReader br) -> br.readLine());
//处理两行
String twoLines =processFile((BufferedReader br) -> br.readLine() + br.readLine());

java8中常见的函数式接口
Predicate
//java.util.function.Predicate<T>
//接口定义了一个名叫 test 的抽象方法,它接受泛型 T 对象,并返回一个 boolean 。
@FunctionalInterface
public interface Predicate<T>{boolean test(T t);
}
public static <T> List<T> filter(List<T> list, Predicate<T> p) {List<T> results = new ArrayList<>();for(T s: list){if(p.test(s)){results.add(s);}}return results;
}Predicate<String> nonEmptyStringPredicate = (String s) -> !s.isEmpty();
List<String> nonEmpty = filter(listOfStrings, nonEmptyStringPredicate);
Consumer
// java.util.function.Consumer<T>
//定义了一个名叫 accept 的抽象方法,它接受泛型 T 的对象,没有返回( void )。
//你如果需要访问类型 T 的对象,并对其执行某些操作,就可以使用这个接口。
@FunctionalInterface
public interface Consumer<T>{void accept(T t);
}
public static <T> void forEach(List<T> list, Consumer<T> c){for(T i: list){c.accept(i);}
}forEach(Arrays.asList(1,2,3,4,5),(Integer i) -> System.out.println(i));
Function
//java.util.function.Function<T, R>
//接口定义了一个叫作 apply 的方法,它接受一个泛型 T 的对象,并返回一个泛型 R 的对象。
//如果你需要定义一个Lambda,将输入对象的信息映射到输出,就可以使用这个接口@FunctionalInterface
public interface Function<T, R>{R apply(T t);
}
public static <T, R> List<R> map(List<T> list,Function<T, R> f) {List<R> result = new ArrayList<>();for(T s: list){result.add(f.apply(s));}return result;
}
// [7, 2, 6]
List<Integer> l = map(Arrays.asList("lambdas","in","action"),(String s) -> s.length());
原始类型特化
Java类型要么是引用类型(比如 Byte 、 Integer 、 Object 、 List ),要么是原始类型(比如 int 、 double 、 byte 、 char )。但是泛型(比如 Consumer 中的 T )只能绑定到引用类型。这是由泛型内部的实现方式造成的。因此,在Java里有一个将原始类型转换为对应的引用类型的机制。这个机制叫作装箱(boxing)。相反的操作,也就是将引用类型转换为对应的原始类型,叫作拆箱(unboxing)。Java还有一个自动装箱机制来帮助程序员执行这一任务:装箱和拆箱操作是自动完成的。
但这在性能方面是要付出代价的。装箱后的值本质上就是把原始类型包裹起来,并保存在堆里。因此,装箱后的值需要更多的内存,并需要额外的内存搜索来获取被包裹的原始值。
Java 8为我们前面所说的函数式接口带来了一个专门的版本,以便在输入和输出都是原始类
型时避免自动装箱的操作
public interface IntPredicate{boolean test(int t);
}
// 无装箱
IntPredicate evenNumbers = (int i) -> i % 2 == 0;
evenNumbers.test(1000);
//装箱
Predicate<Integer> oddNumbers = (Integer i) -> i % 2 == 1;
oddNumbers.test(1000);
一般来说,针对专门的输入参数类型的函数式接口的名称都要加上对应的原始类型前缀,比如 DoublePredicate 、 IntConsumer 、 LongBinaryOperator 、 IntFunction 等。 Function接口还有针对输出参数类型的变种: ToIntFunction 、 IntToDoubleFunction 等。
| 函数式接口 | 函数描述符 | 原始类型特化 |
|---|---|---|
Predicate<T> | T->boolean | IntPredicate,LongPredicate, DoublePredicate |
Consumer<T> | T->void | IntConsumer,LongConsumer, DoubleConsumer |
Function<T,R> | T->R | IntFunction<R>,IntToDoubleFunction,IntToLongFunction,LongFunction<R>,LongToDoubleFunction,LongToIntFunction,DoubleFunction<R>,ToIntFunction<T>,ToDoubleFunction<T>,ToLongFunction<T> |
Supplier<T> | ()->T | BooleanSupplier,IntSupplier, LongSupplier,DoubleSupplier |
UnaryOperator<T> | T->T | IntUnaryOperator,LongUnaryOperator,DoubleUnaryOperator |
BinaryOperator<T> | (T,T)->T | IntBinaryOperator,LongBinaryOperator,DoubleBinaryOperator |
BiPredicate<L,R> | (L,R)->boolean | |
BiConsumer<T,U> | (T,U)->void | ObjIntConsumer<T>,ObjLongConsumer<T>,ObjDoubleConsumer<T> |
BiFunction<T,U,R> | (T,U)->R | ToIntBiFunction<T,U>,ToLongBiFunction<T,U>,ToDoubleBiFunction<T,U> |
异常、Lambda,还有函数式接口又是怎么回事
任何函数式接口都不允许抛出受检异常(checked exception)。如果你需要Lambda表达式来抛出异常,有两种办法:定义一个自己的函数式接口,并声明受检异常,或者把Lambda包在一个 try/catch 块中。
//函数式接口 BufferedReaderProcessor ,它显式声明了一个 IOException
@FunctionalInterface
public interface BufferedReaderProcessor {String process(BufferedReader b) throws IOException;
}
BufferedReaderProcessor p = (BufferedReader br) -> br.readLine();
//但是你可能是在使用一个接受函数式接口的API,比如 Function<T, R> ,没有办法自己创建一个.这种情况下,你可以显式捕捉受检异常:
Function<BufferedReader, String> f = (BufferedReader b) -> {try {return b.readLine();}catch(IOException e) {throw new RuntimeException(e);}
};
类型检查、类型推断以及限制
Lambda表达式时,说它可以为函数式接口生成一个实例。然而,Lambda表达式本身并不包含它在实现哪个函数式接口的信息。为了全面了解Lambda表达式,你应该知道Lambda的实际类型是什么。
类型检查
Lambda的类型是从使用Lambda的上下文推断出来的。上下文(比如,接受它传递的方法的参数,或接受它的值的局部变量)中Lambda表达式需要的类型称为目标类型。
List<Apple> heavierThan150g =filter(inventory, (Apple a) -> a.getWeight() > 150);
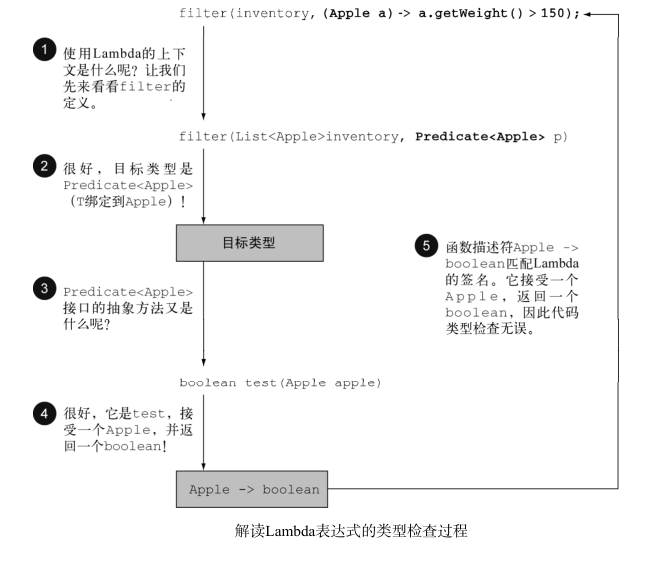
类型检查过程可以分解为如下所示:
- 首先,你要找出 filter 方法的声明
- 第二,要求它是
Predicate<Apple>(目标类型)对象的第二个正式参数。 - 第三,
Predicate<Apple>是一个函数式接口,定义了一个叫作 test 的抽象方法。 - 第四, test 方法描述了一个函数描述符,它可以接受一个 Apple ,并返回一个 boolean 。
- 最后, filter 的任何实际参数都必须匹配这个要求
这段代码是有效的,因为我们所传递的Lambda表达式也同样接受 Apple 为参数,并返回一个
boolean 。请注意,如果Lambda表达式抛出一个异常,那么抽象方法所声明的 throws 语句也必须与之匹配。
同样的 Lambda,不同的函数式接口
有了目标类型的概念,同一个Lambda表达式就可以与不同的函数式接口联系起来,只要它
们的抽象方法签名能够兼容
同一个Lambda可用于多个不同的函数式接口:
Comparator<Apple> c1 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());ToIntBiFunction<Apple, Apple> c2 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());BiFunction<Apple, Apple, Integer> c3 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
-
特殊的void兼容规则
-
如果一个Lambda的主体是一个语句表达式, 它就和一个返回 void 的函数描述符兼容(当然需要参数列表也兼容)。例如,以下两行都是合法的,尽管 List 的 add 方法返回了一个boolean ,而不是 Consumer 上下文( T -> void )所要求的 void :
-
// Predicate返回了一个boolean Predicate<String> p = s -> list.add(s); // Consumer返回了一个void Consumer<String> b = s -> list.add(s);
-
类型推断
Java编译器会从上下文(目标类型)推断出函数式接口需要什么样的Lambda表达式来配合,这意味着它可以推断出适合Lambda的签名,因为函数描述符可以通过目标类型来得到。这样做的好处在于,编译器可以了解Lambda表达式的参数类型,这样就可以在Lambda语法中省去标注参数类型。
当Lambda仅有一个类型需要推断的参数时,参数名称两边的括号也可以省略
// 没有类型推断
Comparator<Apple> c =(Apple a1, Apple a2) ->a1.getWeight().compareTo(a2.getWeight());
//有类型推断
Comparator<Apple> c =(a1, a2) -> a1.getWeight().compareTo(a2.getWeight());
使用局部变量
Lambda表达式允许使用自由变量(不是参数,而是在外层作用域中定义的变量),就像匿名类一样。 它们被称作捕获Lambda。
int portNumber = 1337;
Runnable r = () -> System.out.println(portNumber);
Lambda可以没有限制地捕获(也就是在其主体中引用)实例变量和静态变量。但局部变量必须显式声明为 final ,或事实上是 final 。换句话说,Lambda表达式只能捕获指派给它们的局部变量一次。(注:捕获实例变量可以被看作捕获最终局部变量 this 。) 例如,下面的代码无法编译,因为 portNumber变量被赋值两次:
int portNumber = 1337;
//错误:Lambda表达式引用的局部变量必须是最终的( final )或事实上最终的
Runnable r = () -> System.out.println(portNumber);
portNumber = 31337;
对局部变量的限制
-
局部变量必须显式声明为 final ,或事实上是 final
-
Lambda表达式只能捕获指派给它们的局部变量一次
-
实例变量和局部变量背后的实现有一个关键不同
- 实例变量都存储在堆中,而局部变量则保存在栈上
- 如果Lambda可以直接访问局部变量,而且Lambda是在一个线程中使用的,则使用Lambda的线程,可能会在分配该变量的线程将这个变量收回之后,去访问该变量。因此,Java在访问自由局部变量时,实际上是在访问它的副本,而不是访问原始变量。如果局部变量仅仅赋值一次那就没有什么区别了,因此就有了这个限制。
-
不能修改定义Lambda的方法的局部变量的内容
- 可以认为Lambda是对值封闭,而不是对变量封闭。
- 这种限制存在的原因在于局部变量保存在栈上,并且隐式表示它们仅限于其所在线程。如果允许捕获可改变的局部变量,就会引发造成线程不安全的新的可能性,而这是我们不想看到的(实例变量可以,因为它们保存在堆中,而堆是在线程之间共享的)
方法引用
inventory.sort((Apple a1, Apple a2)-> a1.getWeight().compareTo(a2.getWeight()));
// 使用方法引用和 java.util.Comparator.comparing
inventory.sort(comparing(Apple::getWeight));
方法引用可以被看作仅仅调用特定方法的Lambda的一种快捷写法。它的基本思想是,如果一个Lambda代表的只是“直接调用这个方法”,那最好还是用名称来调用它,而不是去描述如何调用它。事实上,方法引用就是让你根据已有的方法实现来创建Lambda表达式。但是,显式地指明方法的名称,你的代码的可读性会更好。
- 使用方法引用时,目标引用放在分隔符
::前,方法的名称放在后面。 - 可以把方法引用看作针对仅仅涉及单一方法的Lambda的语法糖
如何构建方法引用
- 指向静态方法的方法引用(例如
Integer的parseInt方法,写作Integer::parseInt)
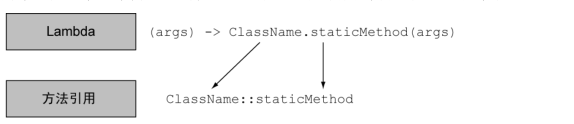
- 指 向 任 意 类 型 实 例 方 法 的 方 法 引 用 ( 例 如
String的length方 法 , 写 作
String::length)- 你在引用一个对象的方法,而这个对象本身是Lambda的一个参数

- 指向现有对象的实例方法的方法引用(假设你有一个局部变量
expensiveTransaction
用于存放Transaction类型的对象,它支持实例方法getValue,那么你就可以写expensive-Transaction::getValue)。- 你在Lambda中调用一个已经存在的外部对象中的方法

对一个字符串的 List 排序,忽略大小写。
List 的 sort 方法需要一个 Comparator 作为参数。
Comparator 描述了一个具有 (T, T) -> int 签名的函数描述符。
利用 String 类中的 compareToIgnoreCase方法来定义一个Lambda表达式
List<String> str = Arrays.asList("a","b","A","B");
//Lambda表达式的签名与 Comparator 的函数描述符兼容。
str.sort((s1, s2) -> s1.compareToIgnoreCase(s2));
//用方法引用改写成下面的样子
List<String> str = Arrays.asList("a","b","A","B");
str.sort(String::compareToIgnoreCase);
//编译器会进行一种与Lambda表达式类似的类型检查过程,来确定对于给定的函数式接口,这个方法引用是否有效:方法引用的签名必须和上下文类型匹配。
-
构造函数引用
-
对于一个现有构造函数,你可以利用它的名称和关键字 new 来创建它的一个引用:
ClassName::new。它的功能与指向静态方法的引用类似。 -
例如,假设有一个构造函数没有参数。它适合
Supplier的签名() -> Apple。你可以这样做: -
//构造函数引用指向默认的 Apple() 构造函数 Supplier<Apple> c1 = Apple::new; //调用 Supplier 的 get 方法将产生一个新的 Apple Apple a1 = c1.get();//等价于 // 利用默认构造函数创建Apple 的Lambda表达式 Supplier<Apple> c1 = () -> new Apple(); Apple a1 = c1.get(); -
如果你的构造函数的签名是
Apple(Integer weight),那么它就适合Function接口的签名,于是你可以这样写 -
Function<Integer, Apple> c2 = Apple::new; Apple a2 = c2.apply(110);//等价于 Function<Integer, Apple> c2 = (weight) -> new Apple(weight); Apple a2 = c2.apply(110); -
如果你有一个具有两个参数的构造函数
Apple(String color, Integer weight),那么它就适合BiFunction接口的签名,于是你可以这样写: -
BiFunction<String, Integer, Apple> c3 = Apple::new; Apple c3 = c3.apply("green", 110); //等价于 BiFunction<String, Integer, Apple> c3 =(color, weight) -> new Apple(color, weight); Apple c3 = c3.apply("green", 110); -
你已经看到了如何将有零个、一个、两个参数的构造函数转变为构造函数引用。那要怎么样才能对具有三个参数的构造函数,比如
Color(int, int, int), 使用构造函数引用?-
构造函数引用的语法是
ClassName::new,那么在这个例子里面就是
Color::new。但是你需要与构造函数引用的签名匹配的函数式接口。但是语言本身并没有提供这样的函数式接口,你可以自己创建一个: -
public interface TriFunction<T, U, V, R>{R apply(T t, U u, V v); } TriFunction<Integer, Integer, Integer, Color> colorFactory = Color::new;
-
-
Lambda 和方法引用实战
用不同的排序策略给一个 Apple 列表排序
第 1 步:传递代码
Java 8的API已经为你提供了一个 List 可用的 sort 方法, sort 方法的签名是这样的:void sort(Comparator<? super E> c)
需要一个 Comparator 对象来比较两个 Apple !这就是在Java中传递策略的方式:它们必
须包裹在一个对象里。我们说 sort 的行为被参数化了:传递给它的排序策略不同,其行为也会
不同。
第一个解决方案看上去是这样的:
public class AppleComparator implements Comparator<Apple> {public int compare(Apple a1, Apple a2){return a1.getWeight().compareTo(a2.getWeight());}
}inventory.sort(new AppleComparator());
第 2 步:使用匿名类
使用匿名类来改进解决方案,而不是实现一个 Comparator 却只实例化一次
inventory.sort(new Comparator<Apple>() {public int compare(Apple a1, Apple a2){return a1.getWeight().compareTo(a2.getWeight());}
});
第 3 步:使用 Lambda 表达式
Lambda表达式,它提供了一种轻量级语法来实现相同的目标:传递代码。你看到了,在需要函数式接口的地方可以使用Lambda表达式。
函数式接口就是仅仅定义一个抽象方法的接口。抽象方法的签名(称为函数描述符)描述了Lambda表达式的签名。在这个例子里, Comparator 代表了函数描述符 (T, T) -> int 。因为你用的是苹果,所以它具体代表的就是 (Apple, Apple) -> int 。改进后的新解决方案看上去就是这样的了:
inventory.sort((Apple a1, Apple a2)-> a1.getWeight().compareTo(a2.getWeight()));
Java编译器可以根据Lambda出现的上下文来推断Lambda表达式参数的类型。
inventory.sort((a1, a2) -> a1.getWeight().compareTo(a2.getWeight()));
Comparator 具有一个叫作 comparing 的静态辅助方法,它可以接受一个 Function 来提取 Comparable 键值,并生成一个 Comparator 对象
Comparator<Apple> c = Comparator.comparing((Apple a) -> a.getWeight());import static java.util.Comparator.comparing;
inventory.sort(comparing((a) -> a.getWeight()));
第 4 步:使用方法引用
方法引用就是替代那些转发参数的Lambda表达式的语法糖。你可以用方法引用让你的代码更简洁(假设你静态导入了java.util.Comparator.comparing):
inventory.sort(comparing(Apple::getWeight));
复合 Lambda 表达式的有用方法
许多函数式接口,比如用于传递Lambda表达式的 Comparator 、 Function 和 Predicate 都提供了允许你进行复合的方法。
这意味着你可以把多个简单的Lambda复合成复杂的表达式
比较器复合
使用静态方法 Comparator.comparing ,根据提取用于比较的键值的 Function 来返回一个 Comparator ,如下所示:
Comparator<Apple> c = Comparator.comparing(Apple::getWeight);
- 逆序
想要对苹果按重量递减排序怎么办?用不着去建立另一个 Comparator 的实例。接口有一个默认方法 reversed 可以使给定的比较器逆序。因此仍然用开始的那个比较器,只要修改一下前一个例子就可以对苹果按重量递减排序:
//按重量递减排序
inventory.sort(comparing(Apple::getWeight).reversed());
- 比较器链
如果发现有两个苹果一样重怎么办?哪个苹果应该排在前面呢?你可能需要再提供一个 Comparator 来进一步定义这个比较。比如,在按重量比较两个苹果之后,你可能想要按原产国排序。 thenComparing 方法就是做这个用的。它接受一个函数作为参数(就像comparing 方法一样),如果两个对象用第一个 Comparator 比较之后是一样的,就提供第二个Comparator 。
inventory.sort(comparing(Apple::getWeight)
.reversed()//按重量递减排序
.thenComparing(Apple::getCountry));//两个苹果一样重时,进一步按国家排序
谓词复合
谓词接口包括三个方法: negate 、 and 和 or ,让你可以重用已有的 Predicate 来创建更复
杂的谓词。比如,你可以使用 negate 方法来返回一个 Predicate 的非,比如苹果不是红的:
//产生现有 Predicate对象 redApple 的非
Predicate<Apple> notRedApple = redApple.negate();
把两个Lambda用 and 方法组合起来,比如一个苹果既是红色又比较重
//链接两个谓词来生成另一个 Predicate 对象
Predicate<Apple> redAndHeavyApple =redApple.and(a -> a.getWeight() > 150);
进一步组合谓词,表达要么是重(150克以上)的红苹果,要么是绿苹果
Predicate<Apple> redAndHeavyAppleOrGreen =redApple.and(a -> a.getWeight() > 150).or(a -> "green".equals(a.getColor()));
函数复合
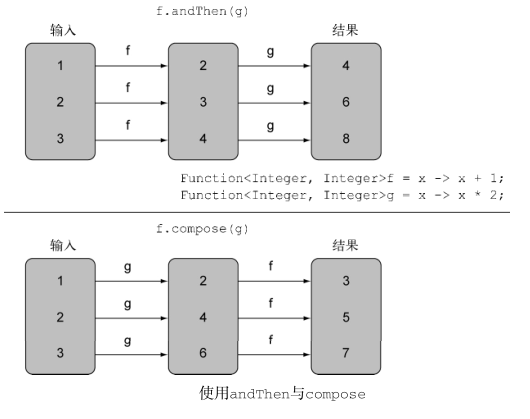
可以把 Function 接口所代表的Lambda表达式复合起来。 Function 接口为此配了 andThen 和 compose 两个默认方法,它们都会返回 Function 的一个实例
-
andThen方法会返回一个函数,它先对输入应用一个给定函数,再对输出应用另一个函数-
假设有一个函数 f 给数字加1 (x -> x + 1) ,另一个函数 g 给数字乘2,你可以将它们组合成一个函数 h ,先给数字加1,再给结果乘2:
-
Function<Integer, Integer> f = x -> x + 1; Function<Integer, Integer> g = x -> x * 2; //数学上会写作 g(f(x)) Function<Integer, Integer> h = f.andThen(g); //将返回4 int result = h.apply(1); -
compose方法,先把给定的函数用作compose的参数里面给的那个函
数,然后再把函数本身用于结果。比如在上一个例子里用compose的话,它将意味着f(g(x)),而andThen则意味着g(f(x)): -
Function<Integer, Integer> f = x -> x + 1; Function<Integer, Integer> g = x -> x * 2; // 数学上会写作 f(g(x)) Function<Integer, Integer> h = f.compose(g); // 将返回3 int result = h.apply(1); -
-
Steam 流
- 遍历数据集的高级迭代器
- 可以透明地并行处理,你无需写任何多线程代码了(并行流)
- 未特别说明情况下,以下出现的Stream流都指的是串行流
Stream本质
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ");
String maxLenStartWithZ = names.stream().filter(name -> name.startsWith(" 张 ")).mapToInt(String::length).max().toString();
需求是查找出一个长度最长,并且以张为姓氏的名字
- 首先 ,因为 names 是 ArrayList 集合,所以 names.stream() 方法将会调用集合类基础接
口 Collection 的 Stream 方法:
default Stream<E> stream() {return StreamSupport.stream(spliterator(), false);
}
- 然后,Stream 方法就会调用
StreamSupport类的stream方法,方法中初始化了一个
ReferencePipeline的Head内部类对象:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {Objects.requireNonNull(spliterator);return new ReferencePipeline.Head<>(spliterator,StreamOpFlag.fromCharacteristics(spliterator),parallel);
}
- 再调用 filter 和 map 方法,这两个方法都是无状态的中间操作,所以执行 filter 和 map操作时,并没有进行任何的操作,而是分别创建了一个 Stage 来标识用户的每一次操作。
- 而通常情况下 Stream 的操作又需要一个回调函数,所以一个完整的 Stage 是由数据来源、操作、回调函数组成的三元组来表示。如下所示,分别是
ReferencePipeline的filter方法和map方法:
@Overridepublic final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {Objects.requireNonNull(predicate);return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {@Overridepublic void begin(long size) {downstream.begin(-1);}@Overridepublic void accept(P_OUT u) {if (predicate.test(u))downstream.accept(u);}};}};}@Override@SuppressWarnings("unchecked")public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {Objects.requireNonNull(mapper);return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<R> sink) {return new Sink.ChainedReference<P_OUT, R>(sink) {@Overridepublic void accept(P_OUT u) {downstream.accept(mapper.apply(u));}};}};}
new StatelessOp将会调用父类AbstractPipeline的构造函数,这个构造函数将前后的Stage 联系起来,生成一个 Stage 链表
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {if (previousStage.linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);previousStage.linkedOrConsumed = true;// 所有中间操作,通过以下两部,生成一个双向链表,previousStage.nextStage = this;this.previousStage = previousStage;this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);this.sourceStage = previousStage.sourceStage;if (opIsStateful())sourceStage.sourceAnyStateful = true;this.depth = previousStage.depth + 1;}
- 因为在创建每一个
Stage时,都会包含一个opWrapSink()方法,该方法会把一个操作的具体实现封装在Sink类中,Sink 采用(处理 -> 转发)的模式来叠加操作。 - 当执行 max 方法时,会调用
ReferencePipeline的 max 方法,此时由于 max 方法是终结操作,所以会创建一个TerminalOp操作,同时创建一个ReducingSink,并且将操作封装在 Sink 类中
@Overridepublic final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) {return reduce(BinaryOperator.maxBy(comparator));}
- 最后,调用
AbstractPipeline的wrapSink方法,该方法会调用opWrapSink生成一个Sink 链表,Sink 链表中的每一个 Sink 都封装了一个操作的具体实现。
@Override@SuppressWarnings("unchecked")final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {Objects.requireNonNull(sink);for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {sink = p.opWrapSink(p.previousStage.combinedFlags, sink);}return (Sink<P_IN>) sink;}
- 当 Sink 链表生成完成后,Stream 开始执行,通过 spliterator 迭代集合,执行 Sink 链表中的具体操作。
@Overridefinal <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {Objects.requireNonNull(wrappedSink);if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {wrappedSink.begin(spliterator.getExactSizeIfKnown());spliterator.forEachRemaining(wrappedSink);wrappedSink.end();}else {copyIntoWithCancel(wrappedSink, spliterator);}}
- Java8 中的
Spliterator的forEachRemaining会迭代集合,每迭代一次,都会执行一次filter 操作,如果 filter 操作通过,就会触发 map 操作,然后将结果放入到临时数组object 中,再进行下一次的迭代。完成中间操作后,就会触发终结操作 max。 - Stream 并行处理
- Stream 处理数据的方式有两种,串行处理和并行处理。要实现并行处理,我们只需要在例子的代码中新增一个
Parallel()方法 - Stream 的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用
TerminalOp的evaluateParallel方法进行并行处理。 - 并行处理指的是,Stream 结合了 ForkJoin 框架,对 Stream 处理进行了分片,
Splititerator中的estimateSize方法会估算出分片的数据量 - 通过预估的数据量获取最小处理单元的阀值,如果当前分片大小大于最小处理单元的阀值,就继续切分集合。每个分片将会生成一个 Sink 链表,当所有的分片操作完成后,ForkJoin 框架将会合并分片任何结果集。
- Stream 处理数据的方式有两种,串行处理和并行处理。要实现并行处理,我们只需要在例子的代码中新增一个
- 在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。所以我们在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。
- 在串行处理操作中,Stream 在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过 Java8中的 Spliterator 迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
- 在并行处理操作中,Stream 对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream 将结合 ForkJoin 框架对集合进行切片处理,Fork
Steam 和 for循环
以一个案例分析,Stream和for循环的异同点:
一张菜肴列表,从中获取热量大于400的,菜肴名称
//菜肴类
public class Dish {private final String name;private final boolean vegetarian;private final int calories;private final Type type;public Dish(String name, boolean vegetarian, int calories, Type type) {this.name = name;this.vegetarian = vegetarian;this.calories = calories;this.type = type;}public String getName() {return name;}public boolean isVegetarian() {return vegetarian;}public int getCalories() {return calories;}public Type getType() {return type;}@Overridepublic String toString() {return name;}public enum Type {MEAT, FISH, OTHER}
}
实现需求:
public class Test {public static void main(String[] args) {
// 菜单List<Dish> menu = Arrays.asList(new Dish("pork", false, 800, Dish.Type.MEAT),new Dish("beef", false, 700, Dish.Type.MEAT),new Dish("chicken", false, 400, Dish.Type.MEAT),new Dish("french fries", true, 530, Dish.Type.OTHER),new Dish("rice", true, 350, Dish.Type.OTHER),new Dish("season fruit", true, 120, Dish.Type.OTHER),new Dish("pizza", true, 550, Dish.Type.OTHER),new Dish("prawns", false, 300, Dish.Type.FISH),new Dish("salmon", false, 450, Dish.Type.FISH));System.out.println("===========使用for循环=============");iterator(Arrays.asList(new Dish("pork", false, 800, Dish.Type.MEAT),new Dish("beef", false, 700, Dish.Type.MEAT),new Dish("chicken", false, 400, Dish.Type.MEAT),new Dish("french fries", true, 530, Dish.Type.OTHER),new Dish("rice", true, 350, Dish.Type.OTHER),new Dish("season fruit", true, 120, Dish.Type.OTHER),new Dish("pizza", true, 550, Dish.Type.OTHER),new Dish("prawns", false, 300, Dish.Type.FISH),new Dish("salmon", false, 450, Dish.Type.FISH)));System.out.println("===========使用stream=============");stream(menu);}public static void stream(List<Dish> menu) {// 统计进行过 Calories() > 400 判断的次数AtomicInteger filter_count = new AtomicInteger();// 统计调用 getName() 的次数AtomicInteger map_count = new AtomicInteger();List<String> threeHighCaloricDishNames =menu.stream().filter(d -> {filter_count.getAndIncrement();return d.getCalories() > 400;}).map(x -> {map_count.getAndIncrement();return x.getName();}).limit(3).collect(toList());// [pork, beef, french fries]System.out.println(threeHighCaloricDishNames);// 进入filter次数:4System.out.println("进入filter次数:" + filter_count.get());// 进入map次数:3System.out.println("进入map次数:" + map_count.get());}public static void iterator(List<Dish> menu) {// 统计进行过 Calories() > 400 判断的次数AtomicInteger filter_count = new AtomicInteger();// 统计调用 getName() 的次数AtomicInteger map_count = new AtomicInteger();List<String> threeHighCaloricDishNames = new ArrayList<>();for (Dish dish : menu) {filter_count.getAndIncrement();if (dish.getCalories() > 400){threeHighCaloricDishNames.add(dish.getName());map_count.getAndIncrement();if (threeHighCaloricDishNames.size()>=3){break;}}}// [pork, beef, french fries]System.out.println(threeHighCaloricDishNames);// 进入filter次数:4System.out.println("进入filter次数:" + filter_count.get());// 进入map次数:3System.out.println("进入map次数:" + map_count.get());}}
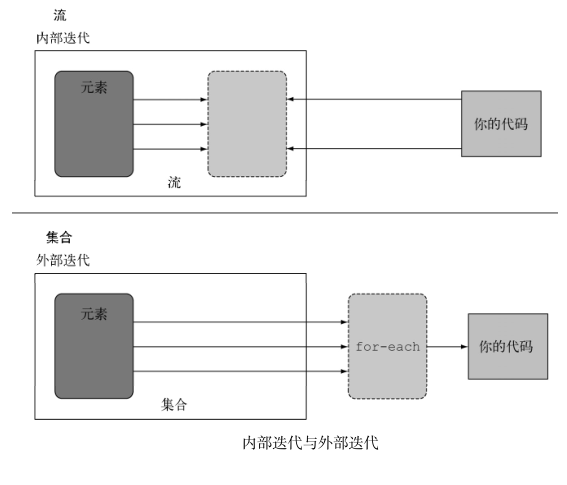
- 使用for循环处理数据
- 需要你自己写迭代获取数据
- 每次获取一个数据
- 每个数据按顺序向下执行,一个数据处理完之后,才处理下一个数据
- 使用Stream处理数据
- 不需要自己写迭代
- 每次处理一个数据
- 每个数据按要求处理完毕,所有流程后,在处理下一个数据
- 流只能消费一次
- 循环是使用外部迭代
- stream使用库文件,使用内部迭代
流操作
中间操作
- 将多个操作连接起来
- 返回值是一个流的操作是中间操作
终结操作
- 生成结果,结束流
- 返回值不是任何流的操作
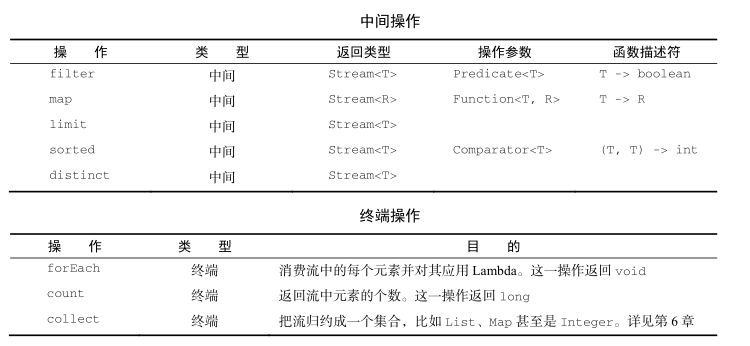
使用流
peek方法在分析Stream流水线时,能将中间变量的值输出到日志中
List<Integer> result =
numbers.stream().peek(x -> System.out.println("from stream: " + x)).map(x -> x + 17).peek(x -> System.out.println("after map: " + x)).filter(x -> x % 2 == 0).peek(x -> System.out.println("after filter: " + x)).limit(3).peek(x -> System.out.println("after limit: " + x)).collect(toList());
筛选和切片
filter该操作会接受一个谓词作为参数,并返回一个包括所有符合谓词的元素的流。distinct返回一个元素各异(根据流元素的hashCode和equals方法实现)的流。limit返回一个不超过给定长度的流。所需的长度作为参数传递给limit。如果流是有序的,则最多会返回前 n 个元素。skip返回一个扔掉了前 n 个元素的流。如果流中元素不足 n 个,则返回一个空流
映射
map接受一个函数作为参数。这个函数会被应用到每个元素上,将其映射成一个新的元素flatMap把一个流中的每个流都换成另一个流,然后把所有的流连接起来成为一个流。
查找和匹配
anyMatch流中是否有一个元素能匹配给定的谓词allMatch流中的元素是否都能匹配给定的谓词noneMatch流中没有任何元素与给定的谓词匹配findAny返回当前流中的任意元素findFirst找到第一个元素
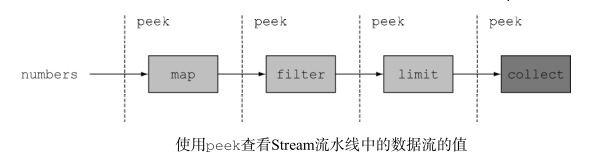
归约(reduce)
- 元素求和
- reduce 接受两个参数:
- 一个初始值,这里是0
- 一个
BinaryOperator<T>来将两个元素结合起来产生一个新值,这里用的是
lambda (a, b) -> a + b 。 - 将上一步迭代的结果,作为reduce(lambda)中下一次迭代的其中一个入参
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
//
int sum = numbers.stream().reduce(0, Integer::sum);
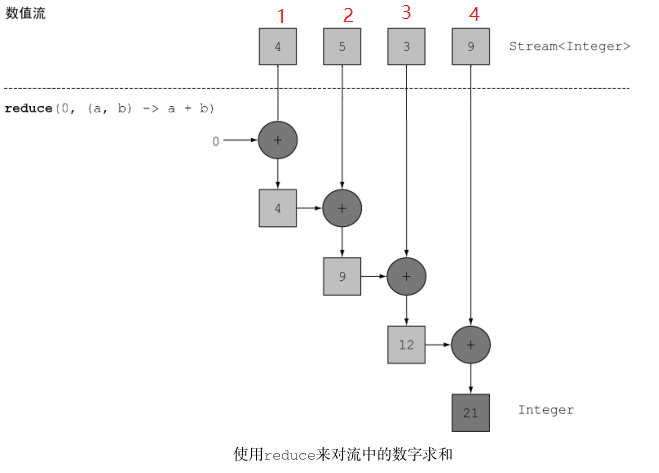
reduce 还有一个重载的变体,它不接受初始值,但是会返回一个 Optional 对象:
Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b));
返回一个 Optional ,考虑流中没有任何元素的情况。 reduce 操作无法返回其和,因为它没有初始值。结果被包裹在一个 Optional 对象里,以表明和可能不存在。
- 最大值和最小值
Optional<Integer> max = numbers.stream().reduce(Integer::max);
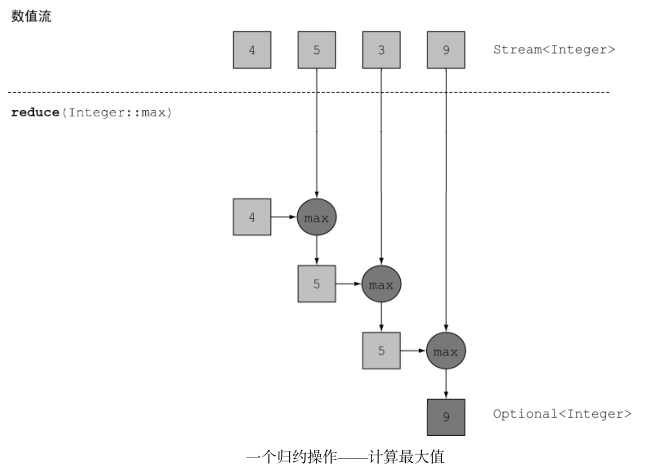
Optional<Integer> min = numbers.stream().reduce(Integer::min);
- 归约方法的优势与并行化
- 相比于前面写的逐步迭代求和,使用 reduce 的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行 reduce 操作。而迭代式求和例子要更新共享变量 sum ,这不是那么容易并行化的。如果加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升!这种计算的并行化需要另一种办法:将输入分块,分块求和,最后再合并起来。
无状态和有状态
- 诸如 map 或 filter 等操作会从输入流中获取每一个元素,并在输出流中得到0或1个结果。这些操作一般都是 无状态的:它们没有内部状态(假设用户提供的Lambda或方法引用没有内部可变状态)。
- 诸如 reduce 、 sum 、 max 等操作需要内部状态来累积结果。不管流中有多少元素要处理,内部状态都是有界的
- 诸如 sort 或 distinct 等操作。从流中排序和删除重复项时都需要知道先前的历史。例如,排序要求所有元素都放入缓冲区后才能给输出流加入一个项目,这一操作的存储要求是无界的。要是流比较大或是无限的,就可能会有问题。把这些操作叫作 有状态操作
流操作
| 操 作 | 类 型 | 返回类型 | 入参类型 | 函数描述符 |
|---|---|---|---|---|
filter | 中间 | Stream<T> | Predicate<T> | T -> boolean |
distinct | 中间 (有状态-无界) | Stream<T> | ||
skip | 中间 (有状态-有界) | Stream<T> | long | |
limit | 中间 (有状态-有界) | Stream<T> | long | |
map | 中间 | Stream<R> | Function<T, R> | T -> R |
flatMap | 中间 | Stream<R> | Function<T, Stream<R>> | T -> Stream<R> |
sorted | 中间 (有状态无界) | Stream<T> | Comparator<T> | (T, T) -> int |
anyMatch | 终结 | boolean | Predicate<T> | T -> boolean |
noneMatch | 终结 | boolean | Predicate<T> | T -> boolean |
allMatch | 终结 | boolean | Predicate<T> | T -> boolean |
findAny | 终结 | Optional<T> | ||
findFirst | 终结 | Optional<T> | ||
forEach | 终结 | void | Consumer<T> | T -> void |
collect | 终结 | R | Collector<T, A, R> | |
reduce | 终结 (有状态-有界) | Optional<T> | BinaryOperator<T> | (T, T) -> T |
count | 终结 | long |
数值流
原始类型流特化
-
IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double,从而避免了暗含的装箱成本。每个接口都带来了进行常用数值归约的新方法,比如对数值流求和的 sum ,找到最大元素的 max 。此外还有在必要时再把它们转换回对象流的方法 -
映射到数值流
mapToInt、mapToDouble和mapToLong它们返回的是一个特化流,而不是Stream<T>
int calories = menu.stream()//返回一个Stream<Dish>.mapToInt(Dish::getCalories)//返回一个IntStream.sum();如果流是空的, sum 默认返回 0 。 IntStream 还支持其他的方便方法,如max 、 min 、 average 等
-
转换回对象流
-
boxed()
//将 Stream 转换为数值流
IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
//将数值流转换为 Stream
Stream<Integer> stream = intStream.boxed();
-
默认值 OptionalInt
Optional原始类型特化版本:OptionalInt、OptionalDouble和OptionalLong
OptionalInt maxCalories = menu.stream().mapToInt(Dish::getCalories).max();
数值范围
-
IntStream和LongStream的静态方法 -
range第一个参数接受起始值,第二个参数接受结束值。但range 是不包含结束值的 -
rangeClosed第一个参数接受起始值,第二个参数接受结束值, rangeClosed 则包含结束值
IntStream evenNumbers = IntStream.rangeClosed(1, 100).filter(n -> n % 2 == 0);
构建流
- 由值创建流
- 使用静态方法
Stream.of,通过显式值创建一个流。它接受任意数量的参数。
- 使用静态方法
Stream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action");//使用 empty 得到一个空流
Stream<String> emptyStream = Stream.empty();
- 由数组创建流
- 静态方法
Arrays.stream从数组创建一个流
- 静态方法
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();
- 由文件生成流
java.nio.file.Files中的很多静态方法都会返回一个流。
long uniqueWords = 0;
//流会自动关闭
try(Stream<String> lines =Files.lines(Paths.get("data.txt"), Charset.defaultCharset())){uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" ")))//生成单词流.distinct()//删除重复项.count();//计数
}catch(IOException e){//如果打开文件时出现异常则加以处理
}
- 由函数生成流:创建无限流
Stream.iterate接受一个初始值,还有一个依次应用在每个产生的新值上的
Lambda(UnaryOperator<t>类型)Stream.generate接受一个Supplier<T>类型的Lambda提供新的值
Stream.iterate(0, n -> n + 2).limit(10).forEach(System.out::println);Stream.generate(Math::random).limit(5).forEach(System.out::println);
用流收集数据
收集器
- 收集器用作高级归约
- 收集器非常有用,因为用它可以简洁而灵活地定义 collect 用来生成结果集合的标准。更具体地说,对流调用
collect方法将对流中的元素触发一个归约操作(由Collector来参数化)。它遍历流中的每个元素,并让 Collector 进行处理
- 收集器非常有用,因为用它可以简洁而灵活地定义 collect 用来生成结果集合的标准。更具体地说,对流调用
- 一般来说, Collector 会对元素应用一个转换函数(很多时候是不体现任何效果的恒等换,例如 toList ),并将结果累积在一个数据结构中,从而产生这一过程的最终输出。
归约和汇总
Collectors.counting()统计Collectors.maxBy()流中的最大值Collectors.minBy()流中的最小值Collectors.summingInt()汇总(总和、平均值、最大值和最小值)Collectors.joining()连接字符串
以上方法是对 Collectors.reducing()的特化
Collectors.reducing()- 需要三个参数
- 第一个参数是归约操作的起始值,也是流中没有元素时的返回值
- 第二个参数是转换函数
- 第三个参数是一个
BinaryOperator,将两个项目累积成一个同类型的值。转换函数转化后,如何累积BinaryOperator<T>它需要的函数必须能接受两个参数,然后返回相同类型的值
分组
Collectors.groupingBy()接收分类函数
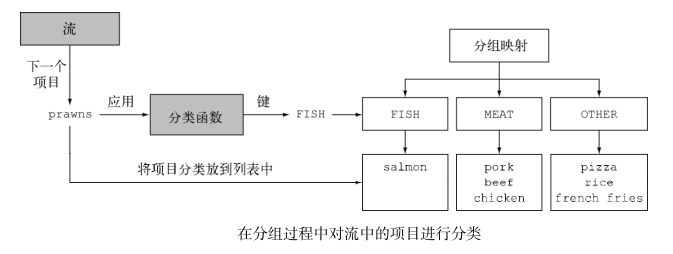
-
Collectors.groupingBy()接收分类函数,可以接受 collector 类型的第二个参数。-
多级分组:要进行二级分组的话,可以把一个内层 groupingBy 传递给外层 groupingBy ,并定义一个为流中项目分类的二级标准
-
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel = menu.stream().collect(//一级分类函数groupingBy(Dish::getType,//二级分类函数groupingBy(dish -> {if (dish.getCalories() <= 400) return CaloricLevel.DIET;else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;else return CaloricLevel.FAT;} )) );
-
-
把收集器的结果转换为另一种类型
Collectors.collectingAndThen接受两个参数要:转换的收集器以及转换函数,并返回另一个收集器- 这个收集器相当于旧收集器的一个包装, collect 操作的最后一步就是将返回值用转换函数做一个映射。在这里,被包起来的收集器就是用 maxBy 建立的那个,而转换函数 Optional::get 则把返回的 Optional 中的值提取出来
Map<Dish.Type, Dish> mostCaloricByType =menu.stream().collect(//分类函数groupingBy(Dish::getType,collectingAndThen(//包装后的收集器 maxBy(comparingInt(Dish::getCalories)),//转换函数Optional::get)));
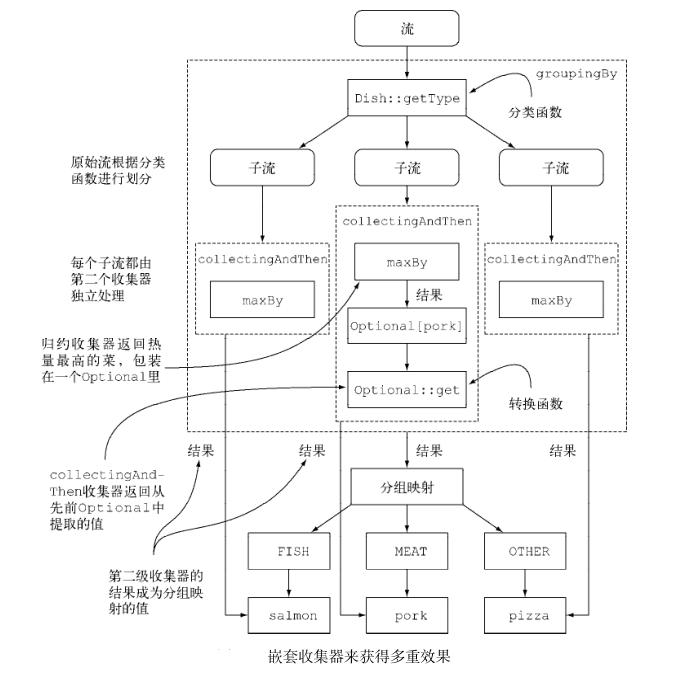
-
收集器用虚线表示,因此
groupingBy是最外层,根据菜肴的类型把菜单流分组,得到三个子流。 -
groupingBy收集器包裹着collectingAndThen收集器,因此分组操作得到的每个子流都用这第二个收集器做进一步归约。 -
collectingAndThen收集器又包裹着第三个收集器maxBy -
随后由归约收集器进行子流的归约操作,然后包含它的
collectingAndThen收集器会对其结果应用Optional:get转换函数。 -
对三个子流分别执行这一过程并转换而得到的三个值,也就是各个类型中热量最高的Dish,将成为 groupingBy 收集器返回的 Map 中与各个分类键( Dish 的类型)相关联的值
-
常常和
groupingBy联合使用的另一个收集器是mapping方法-
这个方法接受两个参数:一个函数对流中的元素做变换,另一个则将变换的结果对象收集起来。其目的是在累加之前对每个输入元素应用一个映射函数,这样就可以让接受特定类型元素的收集器适应不同类型的对象。
-
Map<Dish.Type, Set<CaloricLevel>> caloricLevelsByType = menu.stream().collect( groupingBy(Dish::getType, mapping( dish -> { if (dish.getCalories() <= 400) return CaloricLevel.DIET; else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL; else return CaloricLevel.FAT; }, toSet() )));
-
分区
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函
数。分区函数返回一个布尔值,这意味着得到的分组 Map 的键类型是 Boolean ,于是它最多可以
分为两组—— true 是一组, false 是一组。
partitioningBy
Map<Boolean, List<Dish>> partitionedMenu =
menu.stream().collect(partitioningBy(Dish::isVegetarian));
Collectors 类的静态工厂方法
| 工厂方法 | 返回类型 | 用 于 | 使用示例 |
|---|---|---|---|
toList | List<T> | 把流中所有项目收集到一个 List | List<Dish> dishes = menuStream.collect(toList()); |
toSet | Set<T> | 把流中所有项目收集到一个 Set ,删除重复项 | Set<Dish> dishes = menuStream.collect(toSet()); |
toCollection | Collection<T> | 把流中所有项目收集到给定的供应源创建的集合 | Collection<Dish> dishes = menuStream.collect(toCollection(),ArrayList::new); |
counting | Long | 计算流中元素的个数 | long howManyDishes = menuStream.collect(counting()); |
summingInt | Integer | 对流中项目的一个整数属性求和 | int totalCalories =menuStream.collect(summingInt(Dish::getCalories)); |
averagingInt | Double | 计算流中项目 Integer 属性的平均值 | double avgCalories =menuStream.collect(averagingInt(Dish::getCalories)); |
summarizingInt | IntSummaryStatistics | 收集关于流中项目 Integer 属性的统计值,例如最大、最小、总和与平均值 | IntSummaryStatistics menuStatistics =menuStream.collect(summarizingInt(Dish::getCalories)); |
joining | String | 连接对流中每个项目调用 toString 方法所生成的字符串 | String shortMenu =menuStream.map(Dish::getName).collect(joining(", ")); |
maxBy | Optional<T> | 一个包裹了流中按照给定比较器选出的最大元素的 Optional ,或如果流为空则为 Optional.empty() | Optional<Dish> fattest =menuStream.collect(maxBy(comparingInt(Dish::getCalories))); |
minBy | Optional<T> | 一个包裹了流中按照给定比较器选出的最小元素的 Optional ,或如果流为空则为 Optional.empty() | Optional<Dish> lightest =menuStream.collect(minBy(comparingInt(Dish::getCalories))); |
reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用 BinaryOperator 与流中的元素逐个结合,从而将流归约为单个值 | int totalCalories =menuStream.collect(reducing(0, Dish::getCalories, Integer::sum)); |
collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果应用转换函数 | int howManyDishes =menuStream.collect(collectingAndThen(toList(), List::size)); |
groupingBy | Map<K, List<T>> | 根据项目的一个属性的值对流中的项目作问组,并将属性值作为结果 Map 的键 | Map<Dish.Type,List<Dish>> dishesByType =menuStream.collect(groupingBy(Dish::getType)); |
partitioningBy | Map<Boolean,List<T>> | 根据对流中每个项目应用谓词的结果来对项目进行分区 | Map<Boolean,List<Dish>> vegetarianDishes =menuStream.collect(partitioningBy(Dish::isVegetarian)); |
Collector 接口
public interface Collector<T, A, R> {Supplier<A> supplier();BiConsumer<A, T> accumulator();Function<A, R> finisher();BinaryOperator<A> combiner();Set<Characteristics> characteristics();
}
- T 是流中要收集的项目的泛型。
- A 是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
- R 是收集操作得到的对象(通常但并不一定是集合)的类型
例如,你可以实现一个 ToListCollector<T> 类,将 Stream<T> 中的所有元素收集到一个
List<T> 里,它的签名如下:
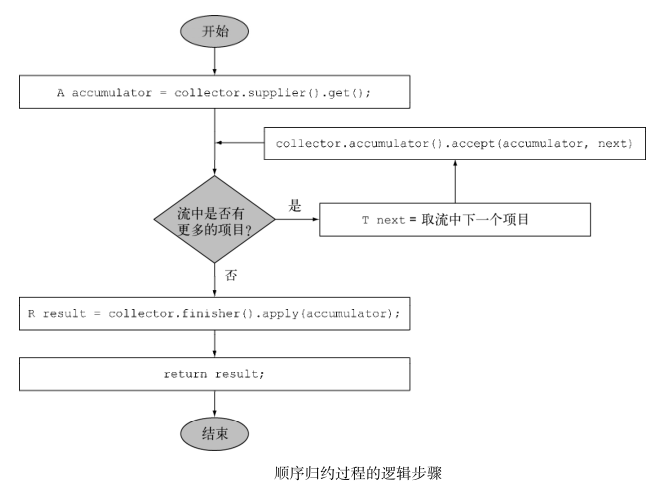
public class ToListCollector<T> implements Collector<T, List<T>, List<T>>{//建立新的结果容器: supplier 方法//supplier 方法必须返回一个结果为空的 Supplier ,也就是一个无参数函数,在调用时它会
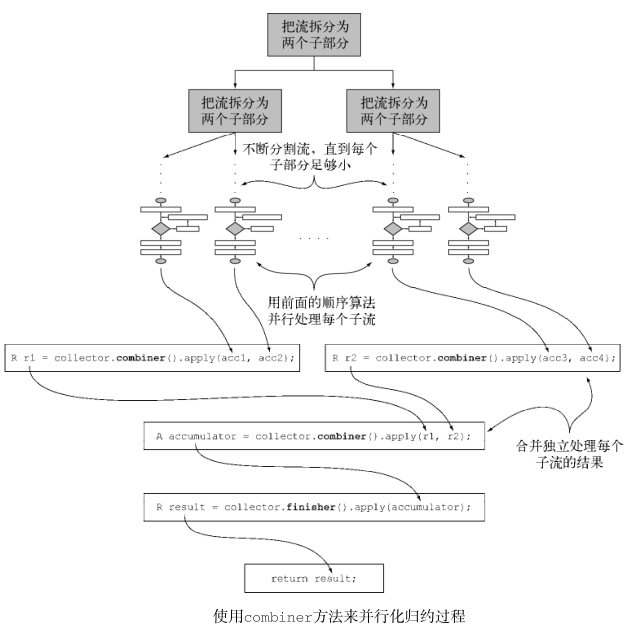
创建一个空的累加器实例,供数据收集过程使用。public Supplier<List<T>> supplier() {return ArrayList::new;}//将元素添加到结果容器: accumulator 方法//accumulator 方法会返回执行归约操作的函数。当遍历到流中第n个元素时,这个函数执行时会有两个参数:保存归约结果的累加器(已收集了流中的前 n1 个项目),还有第n个元素本身。该函数将返回 void ,因为累加器是原位更新,即函数的执行改变了它的内部状态以体现遍历的元素的效果。public BiConsumer<List<T>, T> accumulator() {return List::add;}//对结果容器应用最终转换: finisher 方法//在遍历完流后, finisher 方法必须返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果。public Function<List<T>, List<T>> finisher() {return Function.identity();}//合并两个结果容器: combiner 方法//四个方法中的最后一个—— combiner 方法会返回一个供归约操作使用的函数,它定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器要如何合并。//有了这个方法,就可以对流进行并行归约了。它会用到Java 7中引入的分支/合并框架和Spliterator 抽象//原始流会以递归方式拆分为子流,直到定义流是否需要进一步拆分的一个条件为非(如果分布式工作单位太小,并行计算往往比顺序计算要慢,而且要是生成的并行任务比处理器内核数多很多的话就毫无意义了)。//现在,所有的子流都可以并行处理,即对每个子流应用顺序归约算法。//最后,使用收集器 combiner 方法返回的函数,将所有的部分结果两两合并。这时会把原始流每次拆分时得到的子流对应的结果合并起来。public BinaryOperator<List<T>> combiner() {return (list1, list2) -> {list1.addAll(list2);return list1; }}//characteristics 方法// characteristics 会返回一个不可变的 Characteristics 集合,它定义了收集器的行为——尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示//UNORDERED ——归约结果不受流中项目的遍历和累积顺序的影响。//CONCURRENT —— accumulator 函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为 UNORDERED ,那它仅在用于无序数据源时才可以并行归约。//IDENTITY_FINISH ——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。这也意味着,将累加器 A 不加检查地转换为结果 R 是安全的。public Set<Characteristics> characteristics() {return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, CONCURRENT));
}
并行数据处理与性能
Stream 接口可以让你非常方便地处理它的元素:可以通过对收集源调用 parallelStream 方法来把集合转换为并行流。并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。
-
顺序流转换为并行流
-
parallel() -
对顺序流调用 parallel 方法并不意味着流本身有任何实际的变化。它在内部实际上就是设了一个 boolean 标志,表示你想让调用 parallel 之后进行的所有操作都并
行执行。 -
并行流内部使用了默认的
ForkJoinPool它默认的线 程 数 量 就是 你 的 处 理器 数 量 , 这个 值 是 由Runtime.getRuntime().available-Processors()得到的。但 是 你 可 以 通 过 系 统 属 性java.util.concurrent.ForkJoinPool.common.parallelism来改变线程池大小 -
public static long parallelSum(long n) {return Stream.iterate(1L, i -> i + 1).limit(n).parallel().reduce(0L, Long::sum); } -
只需要对并行流调用
sequential方法就可以把它变成顺序流 -
stream.parallel().filter(...).sequential().map(...).parallel().reduce(); //最后一次 parallel 或 sequential 调用会影响整个流水线。在本例中,流水线会并行执行,因为最后调用的是它
-
-
正确使用并行流
- 错用并行流而产生错误的首要原因,就是使用的算法改变了某些共享状态。

接口中的默认方法
向接口添加方法是诸多问题的罪恶之源;一旦接口发生变化,实现这些接口的类往往也需要更新,提供新添方法的实现才能适配接口的变化。如果你对接口以及它所有相关的实现有完全的控制,这可能不是个大问题。但是这种情况是极少的。这就是引入默认方法的目的:它让类可以自动地继承接口的一个默认实现
如果一个类使用相同的函数签名从多个地方(比如另一个类或接口)继承了方法,通过三条
规则可以进行判断
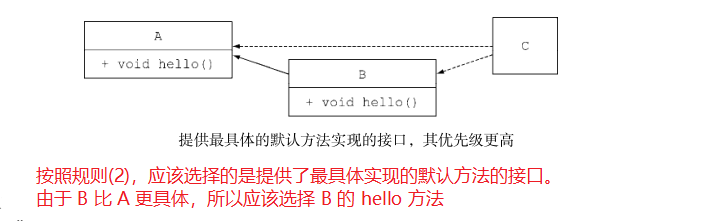
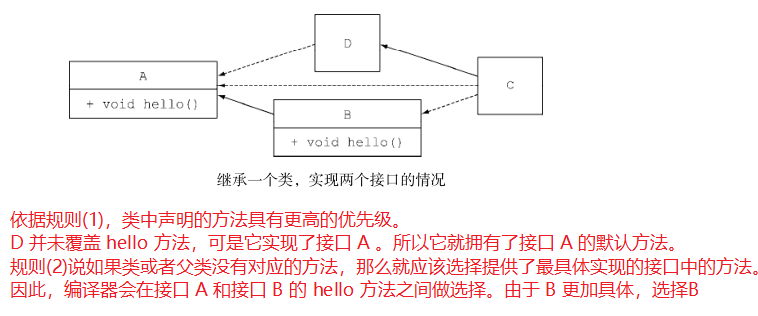
- 类中的方法优先级最高。类或父类中声明的方法的优先级高于任何声明为默认方法的优先级。
- 如果无法依据第一条进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口,即如果 B 继承了 A ,那么 B 就比 A 更加具体。
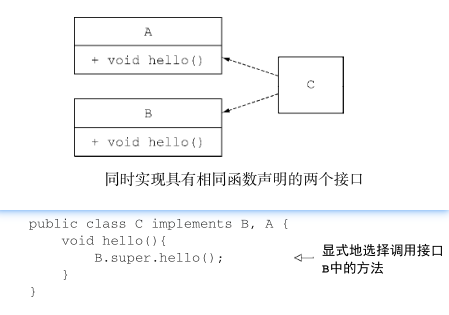
- 最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现。
Optinal 取代 null
Optional 类只是对类简单封装。变量不存在时,缺失的值会被建模成一个“空”的 Optional 对象,由方法 Optional.empty() 返回。 Optional.empty() 方法是一个静态工厂方法,它返回 Optional 类的特定单一实例。
使用Optinal方法时,可以将Optional 看成最多包含一个元素的 Stream 对象
-
创建 Optional 对象
- 声明一个空的 Optional:
Optional<Car> optCar = Optional.empty(); - 依据一个非空值创建 Optional:
Optional<Car> optCar = Optional.of(car); - **可接受 null **的 Optional:
Optional<Car> optCar = Optional.ofNullable(car);
- 声明一个空的 Optional:
-
从 Optional 对象中提取和转换值
-
map 方法:将Optional内部的数据转化成另一个类型
-
Optional<Insurance> optInsurance =Optional.ofNullable(insurance); Optional<String> name = optInsurance.map(Insurance::getName); -
flatMap与Stream流的flatMap类似,将Optional<Optional<T>>内部的Optional<T>转换成T
-
-
在域模型中使用 Optional ,以及为什么它们无法序列化
-
Optional 的设计初衷仅仅是要支持能返回 Optional 对象的语法。
-
Optional 类设计时就没特别考虑将其作为类的字段使用,所以它也并未实现Serializable 接口。由于这个原因,如果你的应用使用了某些要求序列化的库或者框架,在域模型中使用 Optional ,有可能引发应用程序故障。
-
如果你一定要实现序列化的域模型,作为替代方案,建议像下面这个例子那样,提供一个能访问声明为 Optional 、变量值可能缺失的接口
-
public class Person {private Car car;public Optional<Car> getCarAsOptional() {return Optional.ofNullable(car);} }
-
-
默认行为及解引用 Optional 对象
get()最简单但又最不安全的方法。如果变量存在,它直接返回封装的变量值,否则就抛出一个NoSuchElementException异常。所以,除非你非常确定Optional变量一定包含值,否则使用这个方法是个相当糟糕的主意。此外,这种方式即便相对于嵌套式的 null 检查,也并未体现出多大的改进。orElse(T other)它允许你在Optional 对象不包含值时提供一个默认值orElseGet(Supplier<? extends T> other)是 orElse 方法的延迟调用版, Supplier方法只有在 Optional 对象不含值时才执行调用。如果创建默认值是件耗时费力的工作,你应该考虑采用这种方式(借此提升程序的性能),或者你需要非常确定某个方法仅在Optional 为空时才进行调用,也可以考虑该方式(这种情况有严格的限制条件)。orElseThrow(Supplier<? extends X> exceptionSupplier)它们遭遇Optional 对象为空时都会抛出一个异常,但是使用orElseThrow你可以定制希望抛出的异常类型。ifPresent(Consumer<? super T>)在变量值存在时执行一个作为参数传入的
方法,否则就不进行任何操作。
-
使用 filter 剔除特定的值
-
filter 方法接受一个谓词作为参数。如果 Optional 对象的值存在,并且它符合谓词的条件,filter 方法就返回其值;否则它就返回一个空的 Optional 对象。
-
optInsurance.filter(insurance ->"CambridgeInsurance".equals(insurance.getName())).ifPresent(x -> System.out.println("ok"));
-
CompletableFuture
-
类似Future使用CompletableFuture(不建议如此使用)
-
public Future<Double> getPriceAsync(String product) {//创建 CompletableFuture对象,它会包含计算的结果CompletableFuture<Double> futurePrice = new CompletableFuture<>();//在另一个线程中以异步方式执行计算new Thread( () -> {try {double price = calculatePrice(product);//如果价格计算正常结束,完成 Future 操作并设置商品价格futurePrice.complete(price);} catch (Exception ex) {//否则就抛出导致失败的异常,完成这次 Future 操作futurePrice.completeExceptionally(ex);}}).start();//无需等待还没结束的计算,直接返回 Future 对象return futurePrice; }
-
-
使用工厂方法
supplyAsync创建CompletableFuture- supplyAsync 方法接受一个生产者( Supplier )作为参数,返回一个CompletableFuture对象,该对象完成异步执行后会读取调用生产者方法的返值。生产者方法会交由 ForkJoinPool池中的某个执行线程( Executor )运行,但是也可以使用 supplyAsync 方法的重载版本,传递第二个参数指定不同的执行线程执行生产者方法。
-
join阻塞等待CompletableFuture运行结束, 不会抛出任何检测到的异常-
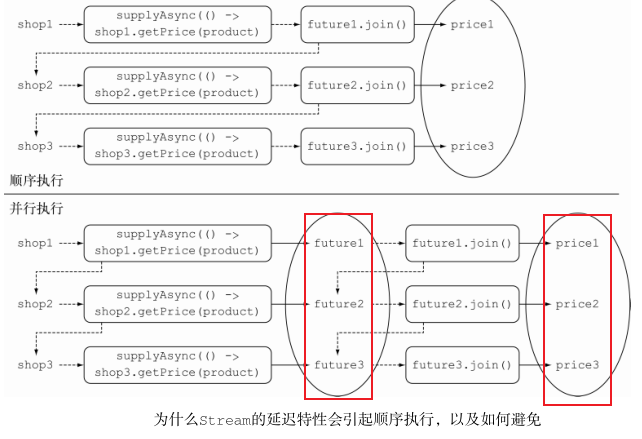
public List<String> findPrices(String product) {//使用 CompletableFuture以异步方式计算每种商品的价格List<CompletableFuture<String>> priceFutures =shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " +shop.getPrice(product))).collect(Collectors.toList());//等待所有异步操作结束return priceFutures.stream().map(CompletableFuture::join).collect(toList()); } -
这里使用了两个不同的 Stream 流水线,而不是在同一个处理流的流水线上一个接一个地放置两个 map 操作——这其实是有缘由的。考虑流操作之间的延迟特性,如果你在单一流水线中处理流,发向不同商家的请求只能以同步、顺序执行的方式才会成功。因此,每个创建 CompletableFuture 对象只能在前一个操作结束之后执行查询指定商家的动作、通知 join方法返回计算结果。
-
-
-
调整线程池的大小
-
如果线程池中线程的数量过多,最终它们会竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上。反之,如果线程的数目过少,处理器的一些核可能就无法充分利用。
-
线程池大小与处理器的利用率之比可以使用下面的公式进行估算:
-
N t h r e a d s = N C P U ∗ U C P U ∗ ( 1 + W / C ) N_{threads} = N_{CPU} * U_{CPU} * (1 + W/C) Nthreads=NCPU∗UCPU∗(1+W/C)
- NCPU 是处理器的核的数目,可以通过
Runtime.getRuntime().availableProce-ssors()得到 - UCPU 是期望的CPU利用率(该值应该介于0和1之间)
- W/C是等待时间与计算时间的比率
- NCPU 是处理器的核的数目,可以通过
-
-
并行——使用流还是 CompletableFutures
- 对集合进行并行计算有两种方式:要么将其转化为并行流,利用 map这样的操作开展工作,要么枚举出集合中的每一个元素,创建新的线程,在 Completable-
Future 内对其进行操作。后者提供了更多的灵活性,你可以调整线程池的大小,而这能帮助你确保整体的计算不会因为线程都在等待I/O而发生阻塞 - 如果你进行的是计算密集型的操作,并且没有I/O,那么推荐使用 Stream 接口,因为实现简单,同时效率也可能是最高的(如果所有的线程都是计算密集型的,那就没有必要创建比处理器核数更多的线程)。
- 反之,如果你并行的工作单元还涉及等待I/O的操作(包括网络连接等待),那么使用CompletableFuture 灵活性更好,你可以依据等待/计算,或者W/C的比率设定需要使用的线程数。这种情况不使用并行流的另一个原因是,处理流的流水线中如果发生I/O等待,流的延迟特性会让我们很难判断到底什么时候触发了等待。
- 对集合进行并行计算有两种方式:要么将其转化为并行流,利用 map这样的操作开展工作,要么枚举出集合中的每一个元素,创建新的线程,在 Completable-
-
将多个异步操作结合在一起,以流水线的方式运行
-
public List<String> findPrices(String product) {List<CompletableFuture<String>> priceFutures =shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product), executor))//以异步方式取得每个 shop 中指定产品的原始价格.map(future -> future.thenApply(Quote::parse))//Quote 对象存在时,对其返回的值进行转换.map(future -> future.thenCompose(quote ->CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote), executor)))//使用另一个异步任务构造期望的 Future ,申请折扣.collect(toList());return priceFutures.stream().map(CompletableFuture::join).collect(toList()); } -
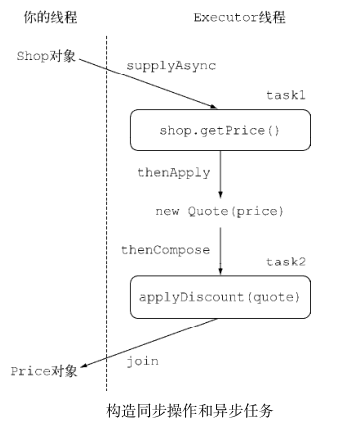
-
获取价格:第一个转换的结果是一个 Stream<CompletableFuture> ,一旦运行结束,每个 CompletableFuture 对象中都会包含对应 shop 返回的字符串。
-
解析报价:第二次转换将字符串转变为订单。由于一般情况下解析操作不涉及任何远程服务,也不会进行任何I/O操作,它几乎可以在第一时间进行,所以能够采用同步操作,不会带来太多的延迟。由于这个原因,你可以对第一步中生成的CompletableFuture 对象调用它的thenApply ,将一个由字符串转换 Quote 的方法作为参数传递给它。直到你调用的 CompletableFuture 执行结束,使用的thenApply 方法都不会阻塞你代码的执行。这意味着 CompletableFuture 最终结束运行时,你希望传递Lambda表达式给
thenApply方法,将 Stream 中的每个CompletableFuture<String>对象转换为对应的CompletableFuture<Quote>对象。 -
为计算折扣价格构造 Future:第三个 map 操作涉及联系远程的 Discount 服务,为从商店中得到的原始价格申请折扣率。这一转换与前一个转换又不大一样,因为这一转换需要远程执行,出于这一原因,希望它能够异步执行。为了实现这一目标,像第一个调用传递 getPrice 给 supplyAsync 那样,将这一操作以Lambda表达式的方式传递给了 supplyAsync 工厂方法,该方法最终会返回另一个Completable-Future 对象。
-
-
thenApply对CompletableFuture里面包裹到的数据类型做转换 -
thenCompose方法允许你对两个异步操作进行流水线,第一个操作完成时,将其结果作为参数传递给第二个操作。可以创建两个 CompletableFutures 对象,对第一个 CompletableFuture 对象调用 thenCompose ,并向其传递一个函数。当第一个CompletableFuture 执行完毕后,它的结果将作为该函数的参数,这个函数的返回值是以第一个 CompletableFuture 的返回做输入计算出的第二个 CompletableFuture 对象。 -
方法名称中不带
Async的方法和它的前一个任务一样,在同一个线程中运行;而名称以Async结尾的方法会将后续的任务提交到一个线程池,所以每个任务是由不同的线程处理的。 -
thenCombine方法,它接收名为 BiFunction 的第二参数,这个参数定义了当两个 CompletableFuture 对象完成计算后,结果如何合并。将两个完全不相干的 CompletableFuture 对象的结果整合起来,而且也不希望等到第一个任务完全结束才开始第二项任务-
Future<Double> futurePriceInUSD = CompletableFuture.supplyAsync(() -> shop.getPrice(product)) .thenCombine(CompletableFuture.supplyAsync(() -> exchangeService.getRate(Money.EUR, Money.USD)),(price, rate) -> price * rate ); -
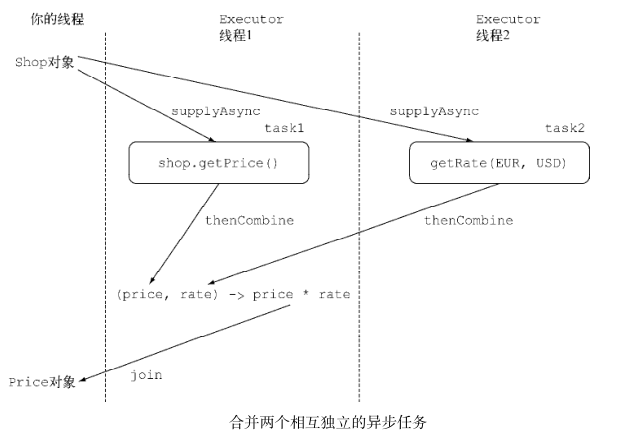
-
-
响应 CompletableFuture 的completion (完成事件)
-
public Stream<CompletableFuture<String>> findPricesStream(String product) { return shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product), executor)).map(future -> future.thenApply(Quote::parse)).map(future -> future.thenCompose(quote ->CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote), executor))); } -
findPricesStream 方法内 部 调 用 了 三 次 map 。第一个map创建了
CompletableFuture之后的map是在已有CompletableFuture上注册操作 -
findPricesStream("myPhone").map(f -> f.thenAccept(System.out::println)); -
为 findPricesStream 方法返回的 Stream 添加了第四个 map 操作, 这 个 新 添 加 的 操 作 其 实 很 简 单 , 只 是 在 每 个CompletableFuture 上注册一个操作,该操作会在 CompletableFuture 完成执行后使用它的返回值。
-
thenAccept它接收CompletableFuture 执行完毕后的返回值做参数。 -
由于 thenAccept 方法已经定义了如何处理 CompletableFuture 返回的结果,一旦CompletableFuture 计算得到结果,它就返回一个CompletableFuture 。所以, map操作返回的是一个 Stream<CompletableFuture> 。对这个 <CompletableFuture> 对象,你能做的事非常有限,只能等待其运行结束
-
希望打印所有的输出返回价格,可以把构成Stream 的所有CompletableFuture 对象放到一个数组中,等待所有的任务执行完成
-
CompletableFuture[] futures = findPricesStream("myPhone") .map(f -> f.thenAccept(System.out::println)) .toArray(size -> new CompletableFuture[size]);CompletableFuture.allOf(futures).join(); -
allOf工厂方法接收一个由 CompletableFuture 构成的数组,**数组中的所有CompletableFuture 对象执行完成之后,它返回一个CompletableFuture 对象。**这意味着,如果你需要等待最初 Stream 中的所有 CompletableFuture 对象执行完毕,对 allOf 方法返回的CompletableFuture 执行 join 操作是个不错的主意。 -
anyOf该方法接收一个 CompletableFuture 对象构成的数组,返回由第一个执行完毕的 CompletableFuture 对象的返回值构成的 CompletableFuture
-
日期时间API
-
LocalDate日期-
该类的实例是一个不可变对象,它只提供了简单的日期,并不含时间信息。另外,它也不附带任何与时区相关的信息。
-
LocalDate date = LocalDate.of(2014, 3, 18); int year = date.getYear(); Month month = date.getMonth(); int day = date.getDayOfMonth(); DayOfWeek dow = date.getDayOfWeek(); int len = date.lengthOfMonth(); boolean leap = date.isLeapYear();//使用 TemporalField 读取 LocalDate 的值 int year = date.get(ChronoField.YEAR); int month = date.get(ChronoField.MONTH_OF_YEAR); int day = date.get(ChronoField.DAY_OF_MONTH);//获取当前的日期 LocalDate today = LocalDate.now(); //解析字符串创建 LocalDate date = LocalDate.parse("2014-03-18");
-
-
LocalTime时间 -
LocalTime time = LocalTime.of(13, 45, 20); int hour = time.getHour(); int minute = time.getMinute(); int second = time.getSecond(); //解析字符串创建 LocalTime time = LocalTime.parse("13:45:20"); -
LocalDateTime日期+时间-
// 2014-03-18T13:45:20 LocalDateTime dt1 = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45, 20); LocalDateTime dt2 = LocalDateTime.of(date, time); LocalDateTime dt3 = date.atTime(13, 45, 20); LocalDateTime dt4 = date.atTime(time); LocalDateTime dt5 = time.atDate(date);LocalDate date1 = dt1.toLocalDate(); LocalTime time1 = dt1.toLocalTime();
-
-
Instant用于机器时间 -
Instant 的设计初衷是为了便于机器使用。它包含的是由秒及纳秒所构成的数字。所以,它无法处理那些我们非常容易理解的时间单位。
-
Instant 类也支持静态工厂方法 now ,它能够帮你获取当前时刻的时间戳。
-
从计算机的角度来看,建模时间最自然的格式是表示一个持续时间段上某个点的单一大整型数
-
Instant 类对时间建模的方式,基本上它是以Unix元年时间(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的秒数进行计算。
-
//通过向静态工厂方法 ofEpochSecond 传递一个代表秒数的值创建一个该类的实例 Instant.ofEpochSecond(3); Instant.ofEpochSecond(3, 0); //接收第二个以纳秒为单位的参数值,对传入作为秒数的参数进行调整 Instant.ofEpochSecond(2, 1_000_000_000); Instant.ofEpochSecond(4, -1_000_000_000); -
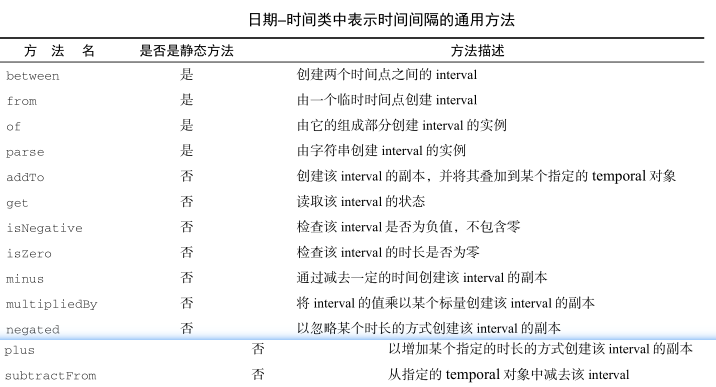
Duration用于时间间隔 -
创建两个 Temporal 对象之间的 duration 。 Duration 类的静态工厂方法 between 就是为这个目的而设计的。
-
Duration d1 = Duration.between(time1, time2); Duration d1 = Duration.between(dateTime1, dateTime2); Duration d2 = Duration.between(instant1, instant2); -
由于 Duration 类主要用于以秒和纳秒衡量时间的长短,你不能仅向 between 方法传递一个 LocalDate 对象做参数
-
Period用于日期间隔 -
如果你需要以年、月或者日的方式对多个时间单位建模,可以使用 Period 类。使用该类的工厂方法 between ,你可以使用得到两个 LocalDate 之间的时长
-
Period tenDays = Period.between(LocalDate.of(2014, 3, 8),LocalDate.of(2014, 3, 18));
-
DateTimeFormatter解析格式化日期时间 -
该类的实例定义了如何格式化一个日期或者时间对象。
-
LocalDate date = LocalDate.of(2014, 3, 18); String s1 = date.format(DateTimeFormatter.BASIC_ISO_DATE); String s2 = date.format(DateTimeFormatter.ISO_LOCAL_DATE);//创建 DateTimeFormatter DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy"); -
单点时间日期的修改、读取
- 使用 get 和 with 方法,可以将 Temporal 对象值的读取和修改区分开。

-
使用
TemporalAdjuster-
将日期调整到下个周日、下个工作日,或者是本月的最后一天。这时,你可以使用重载版本的 with 方法,向其传递一个提供了更多定制化选择的TemporalAdjuster 对象,更加灵活地处理日期。
-
import static java.time.temporal.TemporalAdjusters.*; //2014-03-18 LocalDate date1 = LocalDate.of(2014, 3, 18); //2014-03-23 LocalDate date2 = date1.with(nextOrSame(DayOfWeek.SUNDAY)); //2014-03-31 LocalDate date3 = date2.with(lastDayOfMonth()); -

-
-
处理不同的时区和历法
-
之前你看到的日期和时间的种类都不包含时区信息。
-
时区的处理是新版日期和时间API新增加的重要功能,使用新版日期和时间API时区的处理被极大地简化了。
-
新的 java.time.ZoneId类是老版 java.util.TimeZone 的替代品。它的设计目标就是要让你无需为时区处理的复杂和繁琐而操心
-
调用 ZoneId 的 getRules() 得到指定时区的规则
-
//地区ID都为“{区域}/{城市}”的格式 ZoneId romeZone = ZoneId.of("Europe/Rome");// toZoneId 将一个老的时区对象转换为 ZoneId ZoneId zoneId = TimeZone.getDefault().toZoneId(); -
ZonedDateTime它代表了相对于指定时区的时间点 -
//为时间点添加时区信息 ZoneId romeZone = ZoneId.of("Europe/Rome");LocalDate date = LocalDate.of(2014, Month.MARCH, 18); ZonedDateTime zdt1 = date.atStartOfDay(romeZone); LocalDateTime dateTime = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45); ZonedDateTime zdt2 = dateTime.atZone(romeZone); Instant instant = Instant.now(); ZonedDateTime zdt3 = instant.atZone(romeZone); -
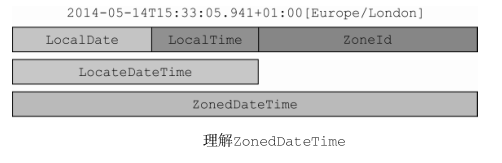
-
//通过 ZoneId ,你还可以将 LocalDateTime 转换为 Instant : LocalDateTime dateTime = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45); Instant instantFromDateTime = dateTime.toInstant(romeZone);//也可以通过反向的方式得到 LocalDateTime 对象 Instant instant = Instant.now(); LocalDateTime timeFromInstant =LocalDateTime.ofInstant(instant, romeZone);
-
-
Date与新版日期时间API的转换-
通过机器时间
Instant作为媒介进行转换 -
//Date转LocalDateTime Date date = new Date(); //获取机器时间 Instant instant = date.toInstant(); //获取时区 ZoneId zoneId = ZoneId.systemDefault(); //LocalDateTime LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, zoneId); -
//LocalDateTime转Date LocalDateTime now = LocalDateTime.now(); //获取时区 ZoneId zoneId = ZoneId.systemDefault(); //获取机器时间 Instant instant = now.atZone(zoneId).toInstant(); //Date Date date = Date.from(instant);
-