Linux 零拷贝技术
在很多的博客文章里面,已经见到过零拷贝这个词,会不禁的发出一些疑问,什么是零拷贝?
从字面上我们很容易理解出,零拷贝包含两个意思:
-
拷贝:就是指数据从一个存储区域转移到另一个存储区域。
-
零:它表示拷贝数据的次数为 0。
零拷贝就是不需要将数据从一个存储区域复制到另一个存储区域。
果真是这样的吗?
最早的零拷贝定义,来源于 Linux 系统的 sendfile 方法逻辑!
在 Linux 2.4 内核中,sendfile 系统调用方法,可以将磁盘数据通过 DMA 拷贝到内核态 Buffer 后,再通过 DMA 拷贝到 NIC Buffer(socket buffer),无需 CPU 拷贝,这个过程被称之为零拷贝。
从这段描述里面我们可以得知,站在操作系统的角度,零拷贝没有说不需要拷贝数据,而是省掉了 CPU 拷贝环节,减少了不必要的拷贝次数,提升数据拷贝效率。
要想深度的了解这里面的原理,我们还得从 IO 拷贝机制说起!
02、IO 拷贝机制介绍
2.1、传统数据拷贝流程
以客户端从服务器下载文件为例,熟悉服务端开发的同学可能知道,服务端需要做两件事:
-
第一步:从磁盘中读取文件内容
-
第二步:将文件内容通过网络传输给客户端
事实上看似简单的操作,里面的流程却没那么简单,例如应用程序从磁盘中读取文件内容的操作,大体会经过以下几个流程:
-
第一步:用户应用程序调用 read 方法,向操作系统发起 IO 请求,CPU 上下文从用户态转为内核态,完成第一次 CPU 切换
-
第二步:操作系统通过 DMA 控制器从磁盘中读数据,并把数据存储到内核缓冲区
-
第三步:CPU 把内核缓冲区的数据,拷贝到用户缓冲区,同时上下文从内核态转为用户态,完成第二次 CPU 切换
整个读取数据的过程,完成了 1 次 DMA 拷贝,1 次 CPU 拷贝,2 次 CPU 切换;反之写入数据的过程,也是一样的。
整个拷贝过程,可以用如下流程图来描述!
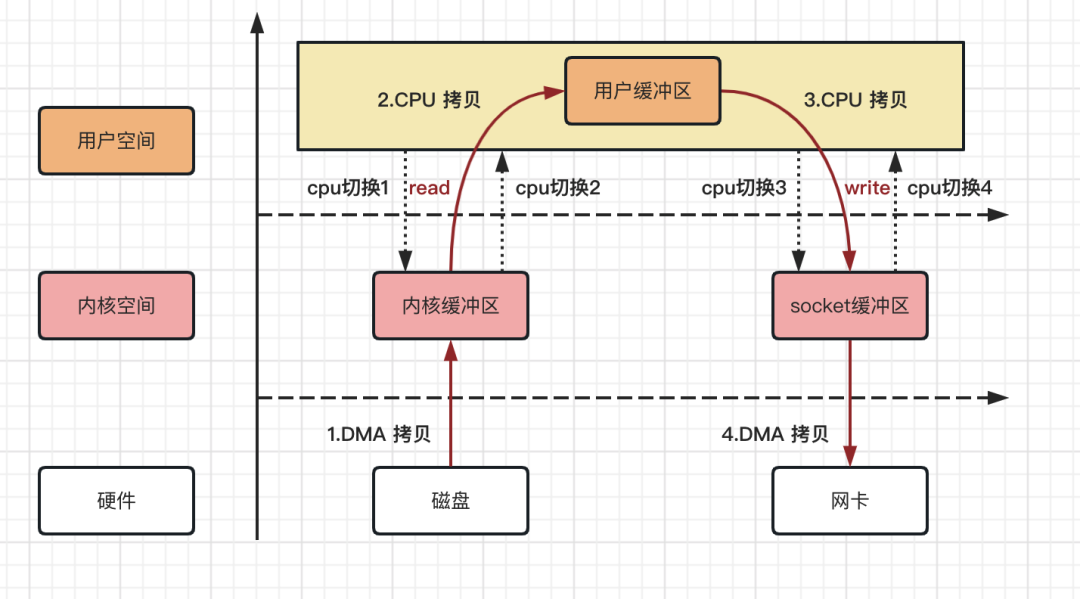
从上图,我们可以得出如下结论,4 次拷贝次数、4 次上下文切换次数。
-
数据拷贝次数:2 次 DMA 拷贝,2 次 CPU 拷贝
-
CPU 切换次数:4 次用户态和内核态的切换
而实际 IO 读写,有时候需要进行 IO 中断,同时也需要 CPU 响应中断,拷贝次数和切换次数比预期的还要多,以至于当客户端进行资源文件下载的时候,传输速度总是不尽人意。
那有没有好的办法来提升资源拷贝的速度呢?
答案是肯定的,传统的数据拷贝流程还有很大的优化空间。
下面我们一起来看看几种其它的拷贝方式。
2.2、mmap 内存映射拷贝流程
mmap 内存映射的拷贝,指的是将用户应用程序的缓冲区和操作系统的内核缓冲区进行映射处理,数据在内核缓冲区和用户缓冲区之间的 CPU 拷贝将其省略,进而加快资源拷贝效率。
整个拷贝过程,可以用如下流程图来描述!
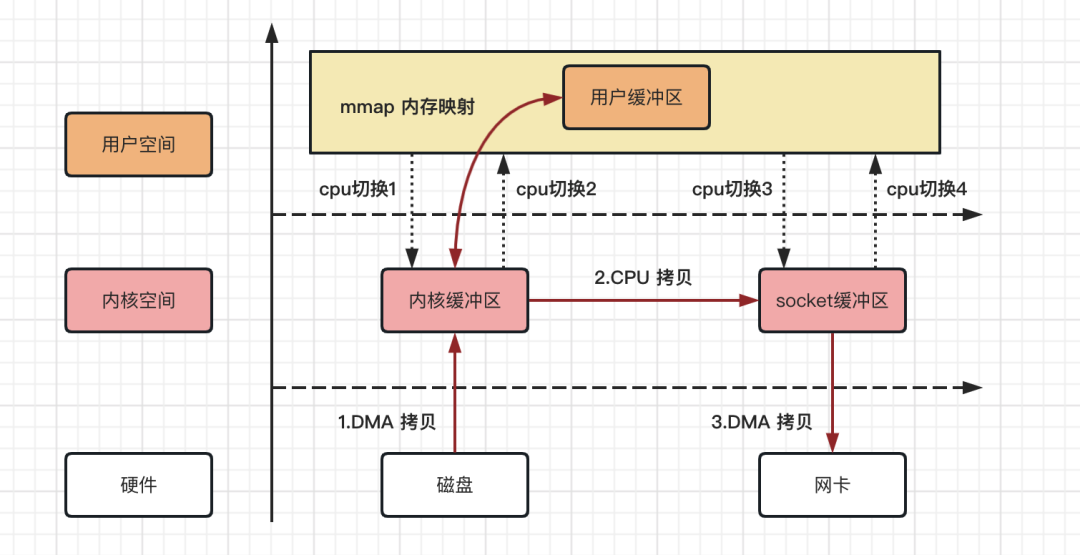
mmap 内存映射拷贝流程,从上图可以得出如下结论:
-
数据拷贝次数:2 次 DMA 拷贝,1 次 CPU 拷贝
-
CPU 切换次数:4 次用户态和内核态的切换
整个过程省掉了数据在内核缓冲区和用户缓冲区之间的 CPU 拷贝环节,在实际的应用中,对资源的拷贝能提升不少。
2.3、Linux 系统 sendfile 拷贝流程
在 Linux 2.1 内核版本中,引入了一个系统调用方法:sendfile。
当调用 sendfile() 时,DMA 将磁盘数据复制到内核缓冲区 kernel buffer;然后将内核中的 kernel buffer 直接拷贝到 socket buffer;最后利用 DMA 将 socket buffer 通过网卡传输给客户端。
整个拷贝过程,可以用如下流程图来描述!
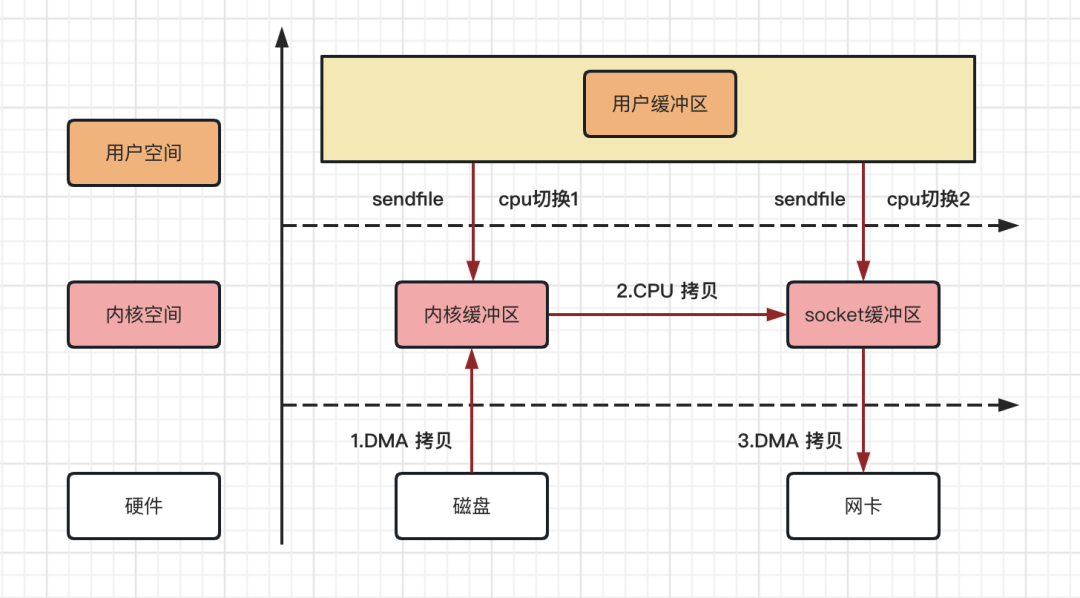
Linux 系统 sendfile 拷贝流程,从上图可以得出如下结论:
-
数据拷贝次数:2 次 DMA 拷贝,1 次 CPU 拷贝
-
CPU 切换次数:2 次用户态和内核态的切换
相比 mmap 内存映射方式,Linux 2.1 内核版本中 sendfile 拷贝流程省掉了 2 次用户态和内核态的切换,同时内核缓冲区和用户缓冲区也无需建立内存映射,对资源的拷贝能提升不少。
2.4、sendfile With DMA scatter/gather 拷贝流程
在 Linux 2.4 内核版本中,对 sendfile 系统方法做了优化升级,引入 SG-DMA 技术,需要 DMA 控制器支持。
其实就是对 DMA 拷贝加入了 scatter/gather 操作,它可以直接从内核空间缓冲区中将数据读取到网卡。使用这个特点来实现数据拷贝,可以多省去一次 CPU 拷贝。
整个拷贝过程,可以用如下流程图来描述!
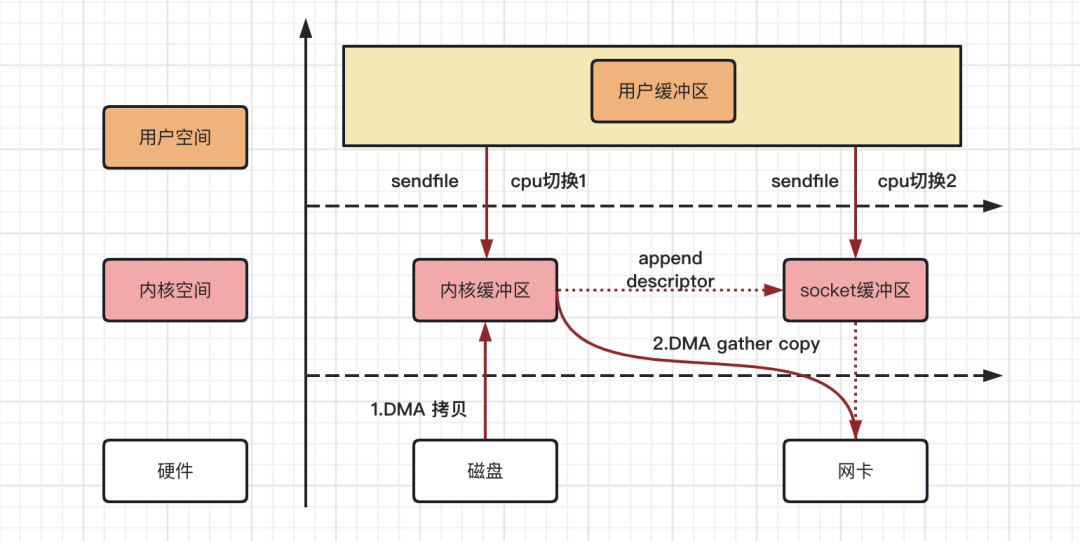
Linux 系统 sendfile With DMA scatter/gather 拷贝流程,从上图可以得出如下结论:
-
数据拷贝次数:2 次 DMA 拷贝,0 次 CPU 拷贝
-
CPU 切换次数:2 次用户态和内核态的切换
可以发现,sendfile With DMA scatter/gather 实现的拷贝,其中 2 次数据拷贝都是 DMA 拷贝,全程都没有通过 CPU 来拷贝数据,所有的数据都是通过 DMA 来进行传输的,这就是操作系统真正意义上的零拷贝(Zero-copy) 技术,相比其他拷贝方式,传输效率最佳。
2.5、Linux 系统 splice 零拷贝流程
在 Linux 2.6.17 内核版本中,引入了 splice 系统调用方法,和 sendfile 方法不同的是,splice 不需要硬件支持。
它将数据从磁盘读取到 OS 内核缓冲区后,内核缓冲区和 socket 缓冲区之间建立管道来传输数据,避免了两者之间的 CPU 拷贝操作。
整个拷贝过程,可以用如下流程图来描述!
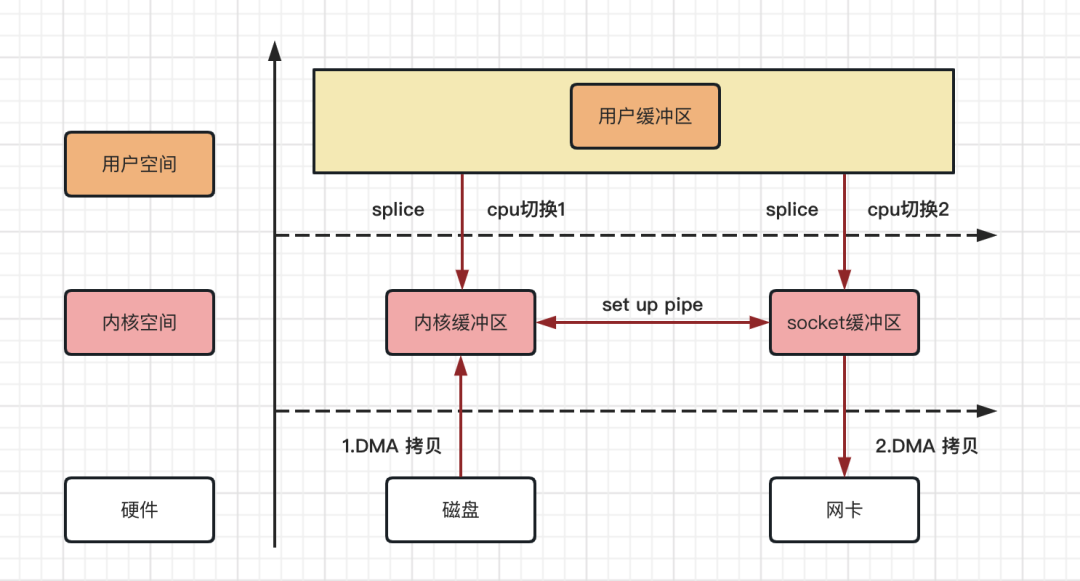
Linux 系统 splice 拷贝流程,从上图可以得出如下结论:
-
数据拷贝次数:2 次 DMA 拷贝,0 次 CPU 拷贝
-
CPU 切换次数:2 次用户态和内核态的切换
Linux 系统 splice 方法逻辑拷贝,也是操作系统真正意义上的零拷贝。
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/socket.h>
#include <linux/un.h>#define BUFFER_SIZE 4096int main()
{int pipefd1[2], pipefd2[2];ssize_t nbytes;// 创建两个管道if (pipe(pipefd1) == -1) {perror("pipe1");return 1;}if (pipe(pipefd2) == -1) {perror("pipe2");close(pipefd1[0]);close(pipefd1[1]);return 1;}// 向第一个管道写入数据char buffer[BUFFER_SIZE];snprintf(buffer, BUFFER_SIZE, "This is a test data for splice example");write(pipefd1[1], buffer, strlen(buffer));// 使用splice将数据从第一个管道传输到第二个管道nbytes = splice(pipefd1[0], NULL, pipefd2[1], NULL, BUFFER_SIZE, SPLICE_F_MOVE);if (nbytes == -1) {perror("splice");close(pipefd1[0]);close(pipefd1[1]);close(pipefd2[0]);close(pipefd2[1]);return 1;}// 从第二个管道读取数据并打印char read_buffer[BUFFER_SIZE];nbytes = read(pipefd2[0], read_buffer, BUFFER_SIZE);if (nbytes == -1) {perror("read");close(pipefd1[0]);close(pipefd1[1]);close(pipefd2[0]);close(pipefd2[1]);return 1;}read_buffer[nbytes] = '\0';printf("Data received from the second pipe: %s\n", read_buffer);// 关闭管道close(pipefd1[0]);close(pipefd1[1]);close(pipefd2[0]);close(pipefd2[1]);return 0;
}03、IO 拷贝机制对比
从上面的 IO 拷贝机制可以看出,无论是传统 IO 方式,还是引入零拷贝之后,2次 DMA copy 是都少不了的,唯一的区别就是省掉 CPU 参与环节的方式不同。
以 Linux 系统为例,拷贝机制对比结果如下!
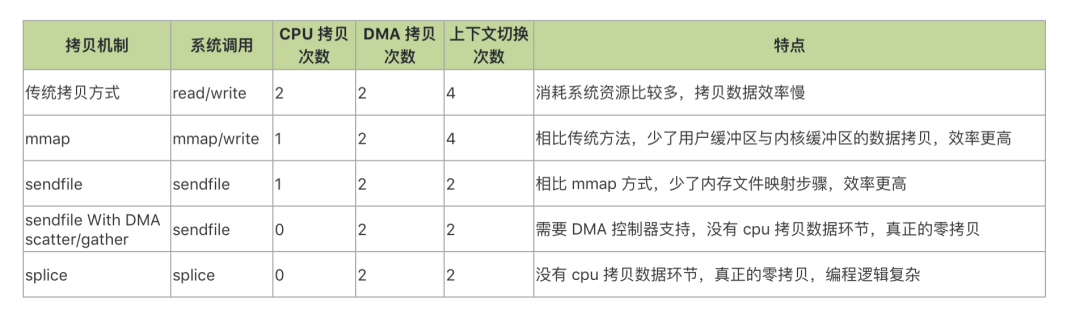
需要注意的地方是,零拷贝所有的方式,都需要操作系统支持,具体采用哪种方式,由操作系统来决定。
参考:
潘志的研发笔记
1、https://zhuanlan.zhihu.com/p/78869158
2、https://zhuanlan.zhihu.com/p/447890038
3、https://zhuanlan.zhihu.com/p/83398714