数学建模---利用Matlab快速实现机器学习(上)
文章目录
- 1.机器学习的引入
- 2.机器学习划分
- 2.1输入输出变量的介绍
- 2.2机器学习的分类
- 3.模型评估指标
- 4.混淆矩阵的引入
- 4.1反映内容
- 4.3正类和负类
- 5.ROC和AUC的说明
- 6.K折交叉验证
- 7.过拟合和欠拟合
- 8.Matlab操作
- 8.0数据集分析
- 8.1路径选择
- 8.2导入数据
- 8.3查看工作区
- 8.4分类学习工具箱使用
- 8.5我的总结
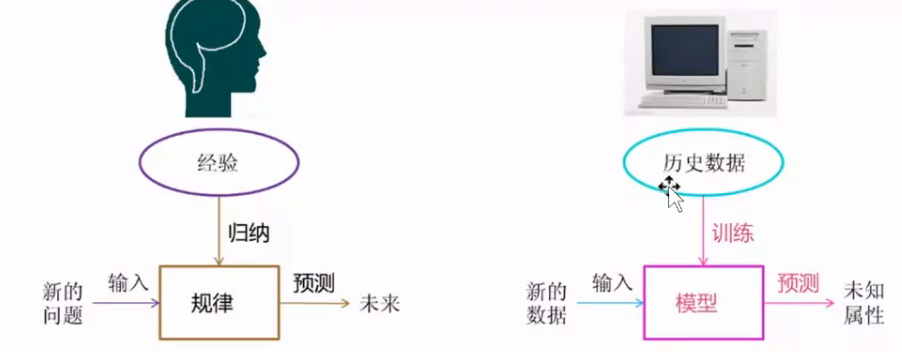
1.机器学习的引入
下面的这个就是基于我们的日常经验进行规律的这个归纳和总结,到我们使用这个计算机进行这个模型的预测(模型就是基于这个已有的这个历史数据进行训练得到的这个共性的规律);
2.机器学习划分
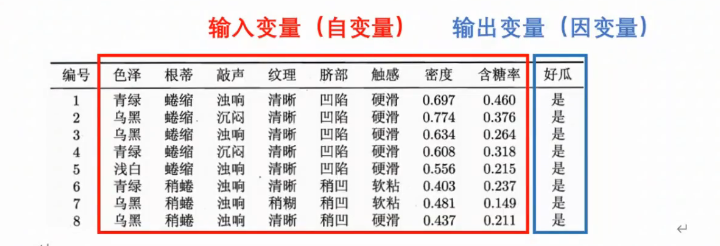
2.1输入输出变量的介绍
我们下面的这个过程里面,很多地方都是用到了这个卖瓜的情景,下面的这个输入输出变量也是基于这个卖瓜的场景进行介绍的;
在这个卖瓜的场景里面,这个输入变量就是我们的这个西瓜的相关的特征(例如下面的这个表里面呈现出来的这个色泽,敲击声音,纹理之类的这个数据)输出变量就是我们的这个瓜的评价结果,就是我们的这个西瓜是好西瓜还是坏西瓜(这个就是我们的目的嘛,因为我们的这个评价指标就是想要知道这个西瓜是好的还是坏的);
2.2机器学习的分类
监督学习和无监督学习,以及这个强化学习,之前只是知道这些概念(尤其是之前的这个python学习的时候,但是感觉当时这个python确实是被捧得太高了,现在觉得,站在数学的角度学习这个机器学习的相关的概念,比当时站在这个python编程语言的角度学习这个相关的概念会变得明朗很多;
不得不承认,通过一个典型的案例,把一些晦涩难懂的这个概念讲的清除和明白,这个其实才是一个有效的学习的手段,对于这一点,我自己是深有体会的,可以简单的谈一下:
1)数学建模的学习:清风把自己的理解通过具体的实例进行介绍,这个其实应该是我们初学者更加容易接受的方式;这个过程往往是劝退很多人的过程;
2)思政的学习:这个可能有点扯远了,但是这个现在推行的这个“大思政课”理念虽然很响,但是真正的进行落实是很困难的,我自己这个学习正在学习这个马克思主义基本原理,这门课程对于这个理工科同学可能本来就不是很有趣,如果不加上案例,场景进行分析,这个只会让我们的这个思政课的效果大大折扣;
3)编程的学习:其实这个编程的学习也是需要场景的,这个里面也是有很多的这个概念的,我们也是需要一定的这个场景进行理解,印象最深的就是学习多线程的时候:哲学家就餐问题,这个一个典型的案例就可以让我们对于这个线程的执行过程,出现死锁的这个原因,以及我们如何对于这个问题进行解决,讲的明明白白;
其实诸如这样的情况还有很多,因为这个只是我第一次觉得对于这些类似于这个机器学习,降维,监督学习饿,无监督学习有一个立体的认识(可能还不是很全面),但是他们的这个面纱被解开了,之前一直觉得这些内容很高大上,但是如果有真正的这个案例进行辅助,我相信我们都是可以学好学明白的;
我只是站在一个初学者的角度,通过今天对于监督学习,无监督学习这些术语有了清晰的认识,所以很受触动
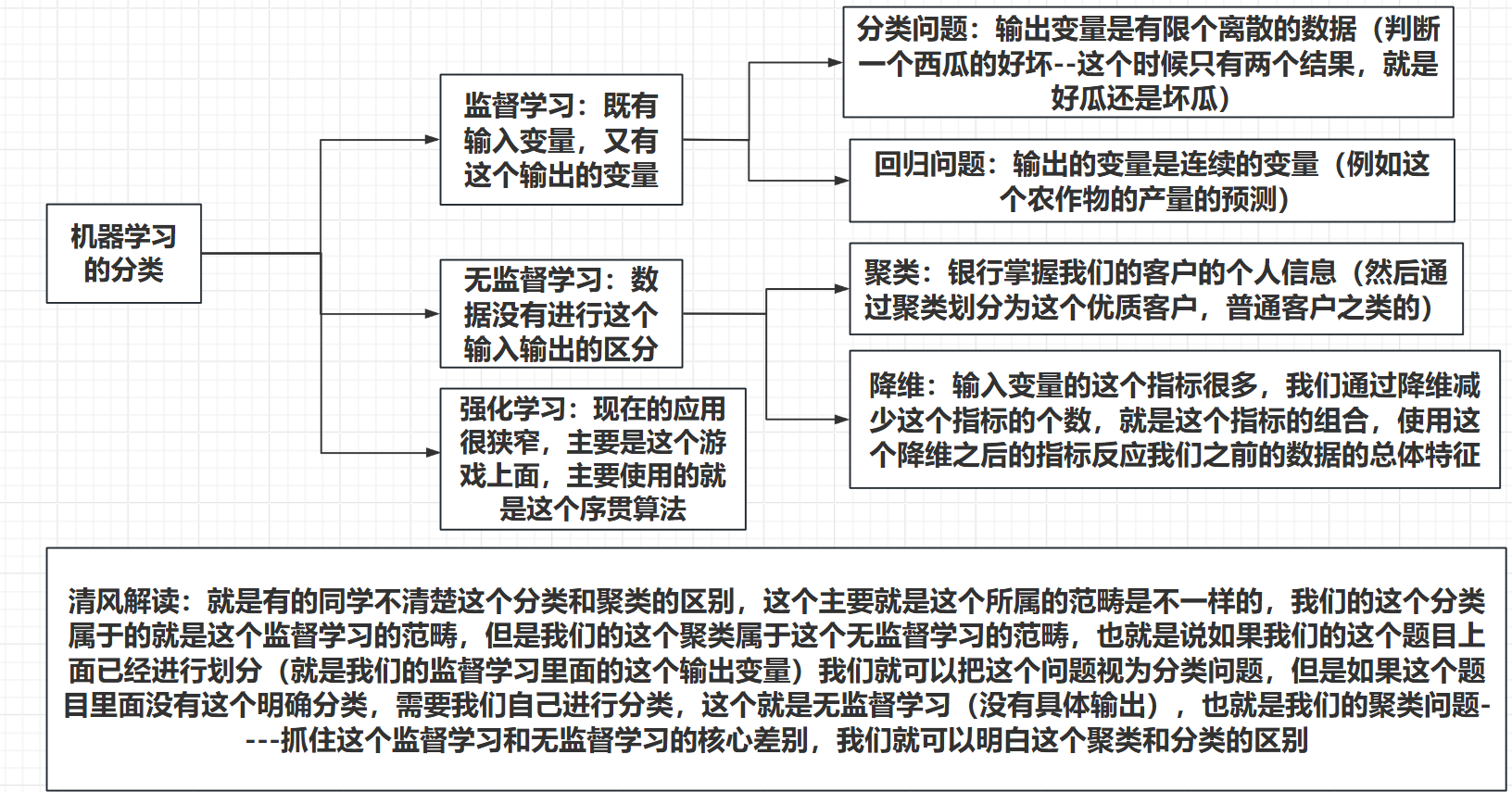
上面的这个图里面还写出来这个:分类和降维的这个区别,其实主要就是把握住这个监督学习和无监督学习的这个区别就可以了;
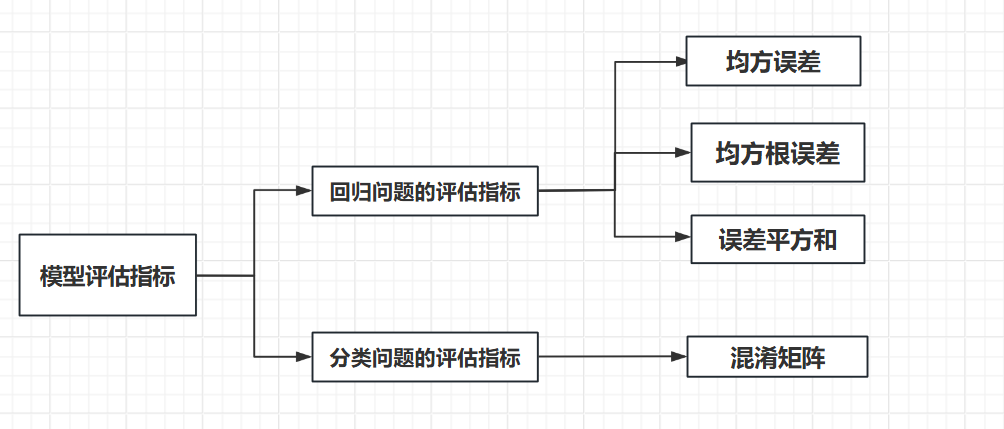
3.模型评估指标
这个对于模型的评估的指标,也是分为了这个回归问题和这个分类学习问题的;
对于这个回归问题:我们使用的进行评估的指标就是我们的这个
1)误差平方和:就是我们的这个实际数据和真实数据的差值进行平方,再进行求和;
2)均方误差:这个就是在上面的这个基础上面进行这个除以n(就是我们的个数)的操作;
3)均方根误差:这个就是我们的的这个2)的基础上面,进行开平方的操作,这个是使用的最多的;
除了上面的这三个,也是存在其他的这个方法的,可自行了解;
4.混淆矩阵的引入
上面的这个是评估指标,在我们的这个分类问题的评估指标里面,引入了这个混淆矩阵的概念:
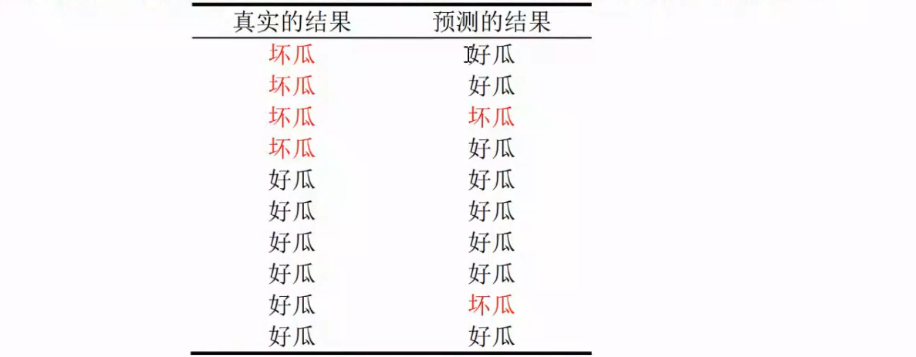
混淆矩阵:下面的这个表示的就是我们的这个预测的结果和我们的这个真实的结果进行比对;
就是我们的这个真实的好瓜,实际上是坏瓜就是1个,以此类推下去;
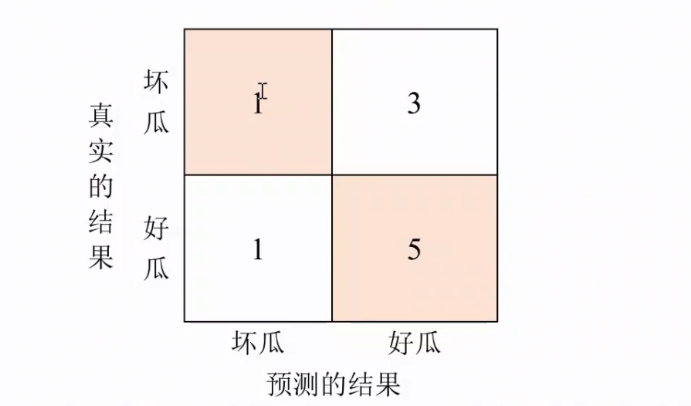
4.1反映内容
1)样本的个数:象限的数据进行加和:
2)分类成功的数量:就是我们的这个主对角线的数量求和;
4.3正类和负类
倾向于把这个不好的,关注的当做正类;

根据我们的正类和负类进行这个混淆矩阵的改写:
改写之后,相当于就是4种,分别是这个正类预测为正类的,正类预测为父类的,负类预测为正类的,负类预测为父类的4种类型,并且有了这个对应的表示;
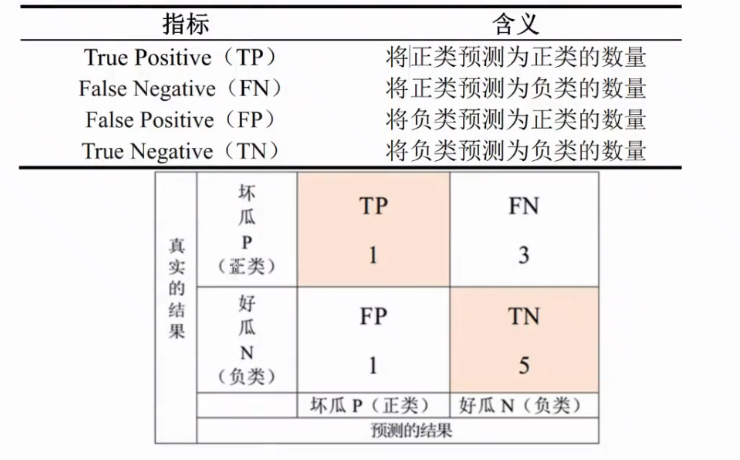
评价指标:分类准确率,查全率和我们的这个查准率;

5.ROC和AUC的说明
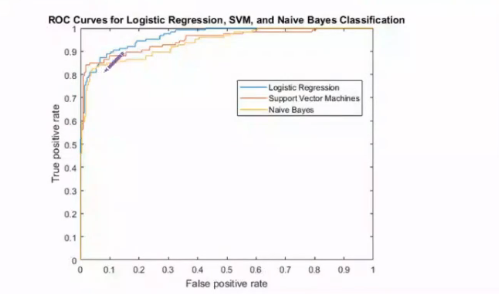
ROC表示的是这个曲线的一个情况,我们的这个ROC曲线越接近于这个左上角,就说明我们的这个效果越好,但是有的时候这个观察不是很直观;
我们引入了基于这个ROC进行改进之后的这个AUC曲线,这个曲线就是我们直接根据这个面积进行判断的;
下面的这个就是直接使用ROC进行观察就不是很直观,我们可以使用这个AUC里面的这个面积进行计算,这个面积也是这个MATLAB直接计算出来;
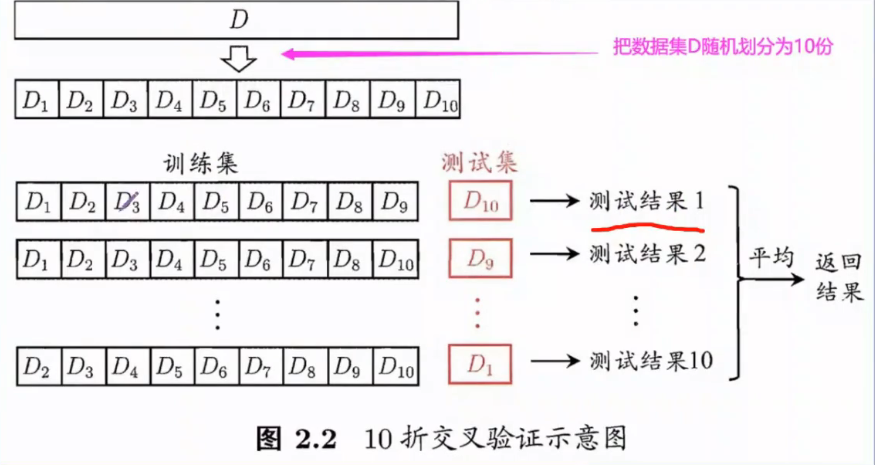
6.K折交叉验证
下面的这个图真的是很棒,可谓是一图胜千言:
完整的呈现了我们的这个训练集和测试集的划分的过程,以及这个对于结果是如何进行处理的;
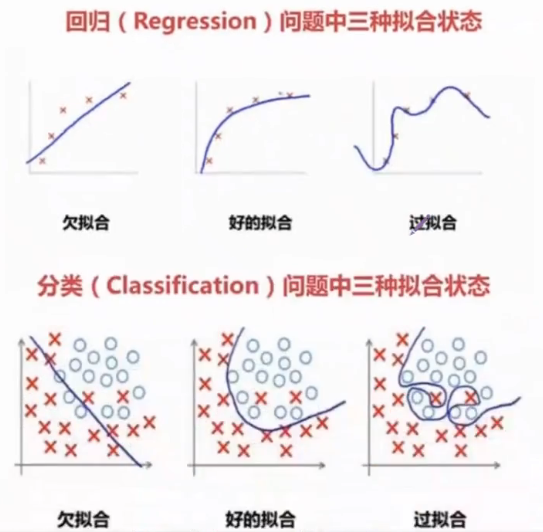
7.过拟合和欠拟合
过拟合:测试集上面的这个效果很好,但是我们的这个测试集上面表现的不好;
欠拟合:就是我们的这个参数在这个测试集和训练接上面的这个效果都不是很好;
8.Matlab操作
8.0数据集分析
下面的这个就是我们的这个数据,根据上面介绍的这个输入输出变量我们就可以知道这个花片的相关的属性就是这个输入变量,我们的这个花片的这个种类就是我们的输出变量;
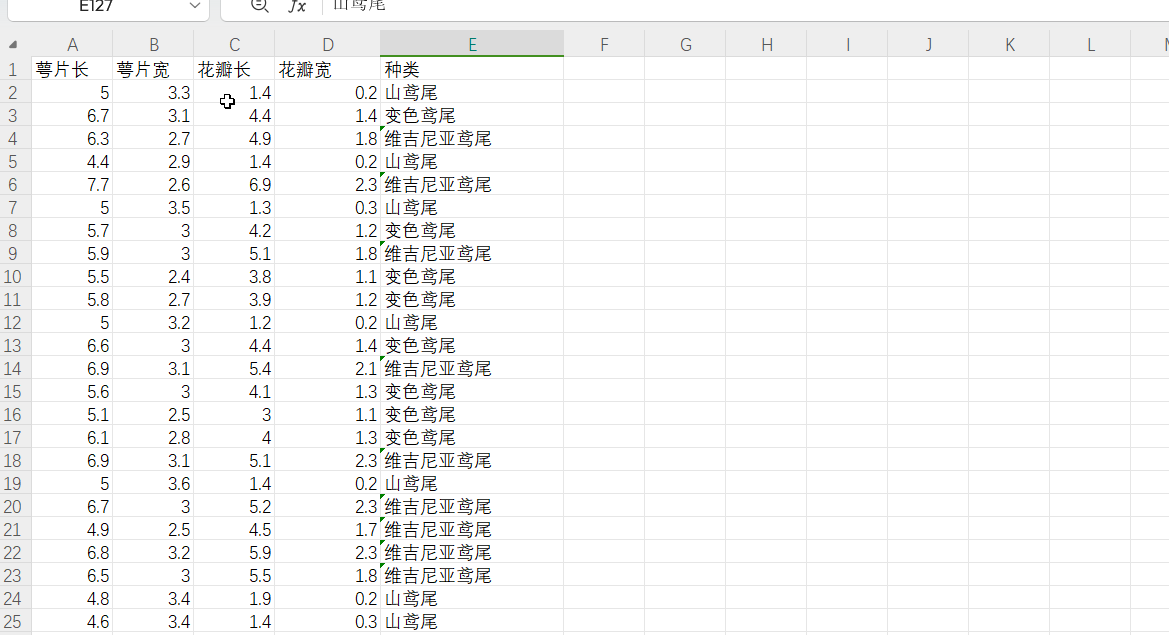
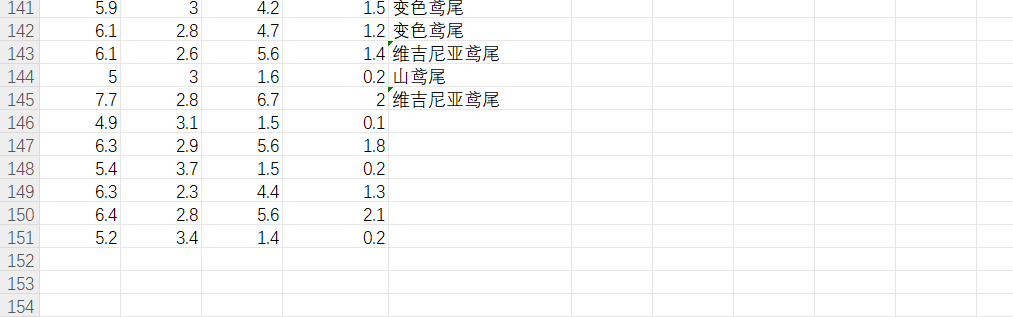
在我们的这个数据结合里面,其实这个最后是有没有进行分类的数据的,这个就是需要我们进行预测的,因此我们需要把这个数据集分为两个部分,已知种类的命名为这个d1,未知的,需要我们进行预测的就是剩下的没有给出来这个类别的数据,我们把这个单独的拿出来,作为d2;
将来就是导入数据之后,我们使用这个d1训练数据,使用这个d2对于未知的进行预测,这个就是大概的流程吧;
8.1路径选择
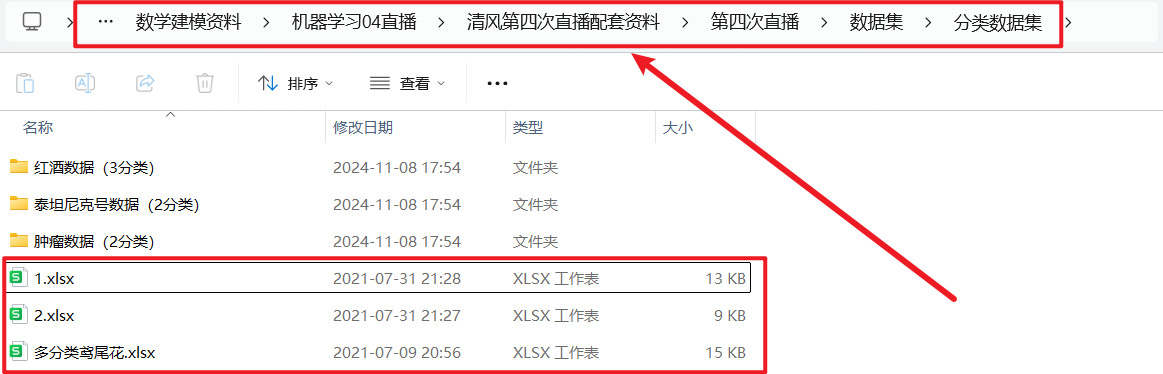
复制到matlab里面的下面的这个位置:

8.2导入数据

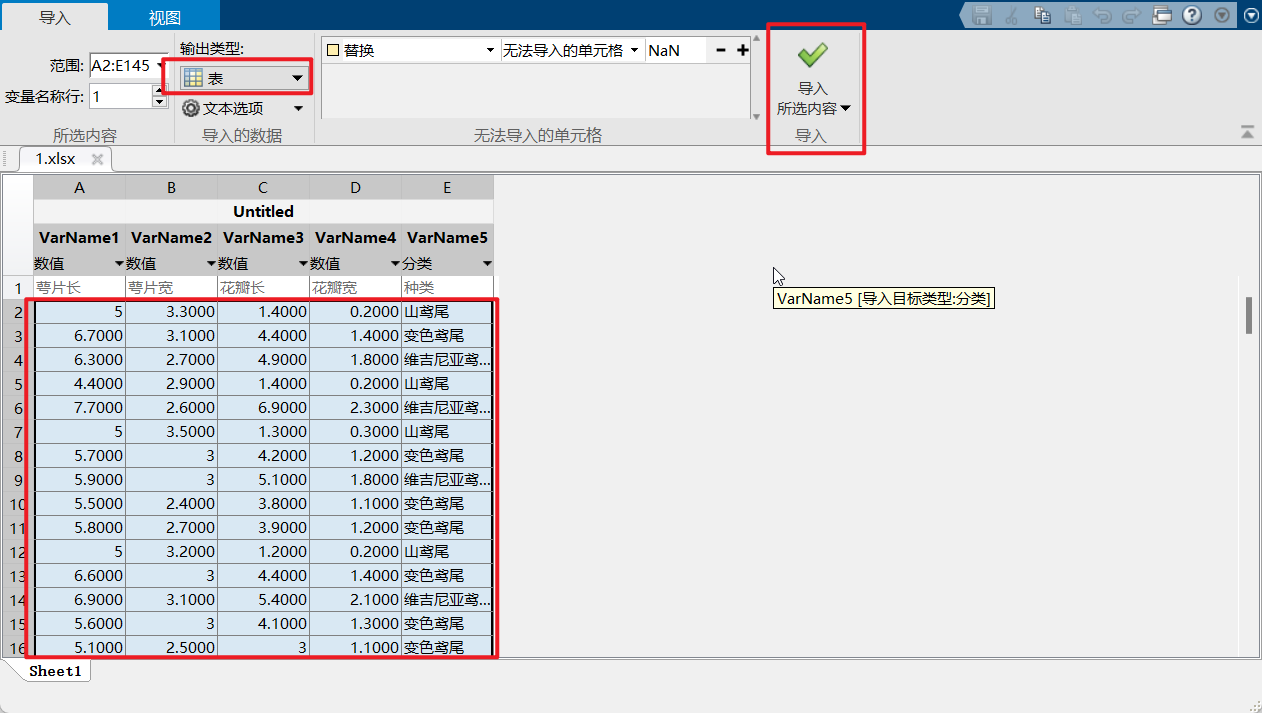
进行选择数据:ctrl+shift按住之后,按下这个右键和下键,就可以选中我们的全部数据了;
确认这个属性就是这个表,可以进行这个重命名的操作,然后点击这个导入数据就可以了;
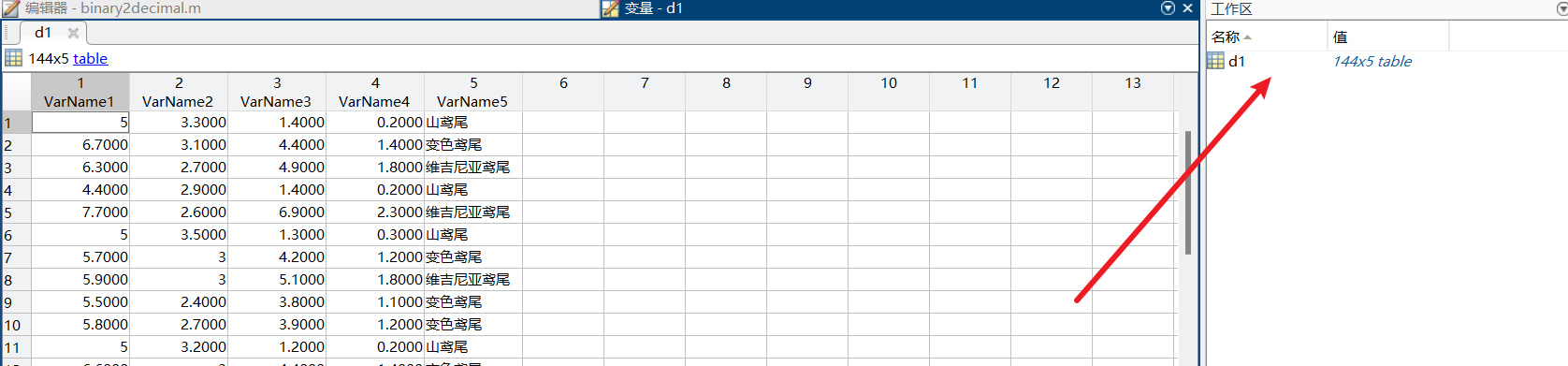
8.3查看工作区
下面的这个工作区存在就说明是导入成功,这个时候我们就可以按照这个方式导入另外的一个表格;
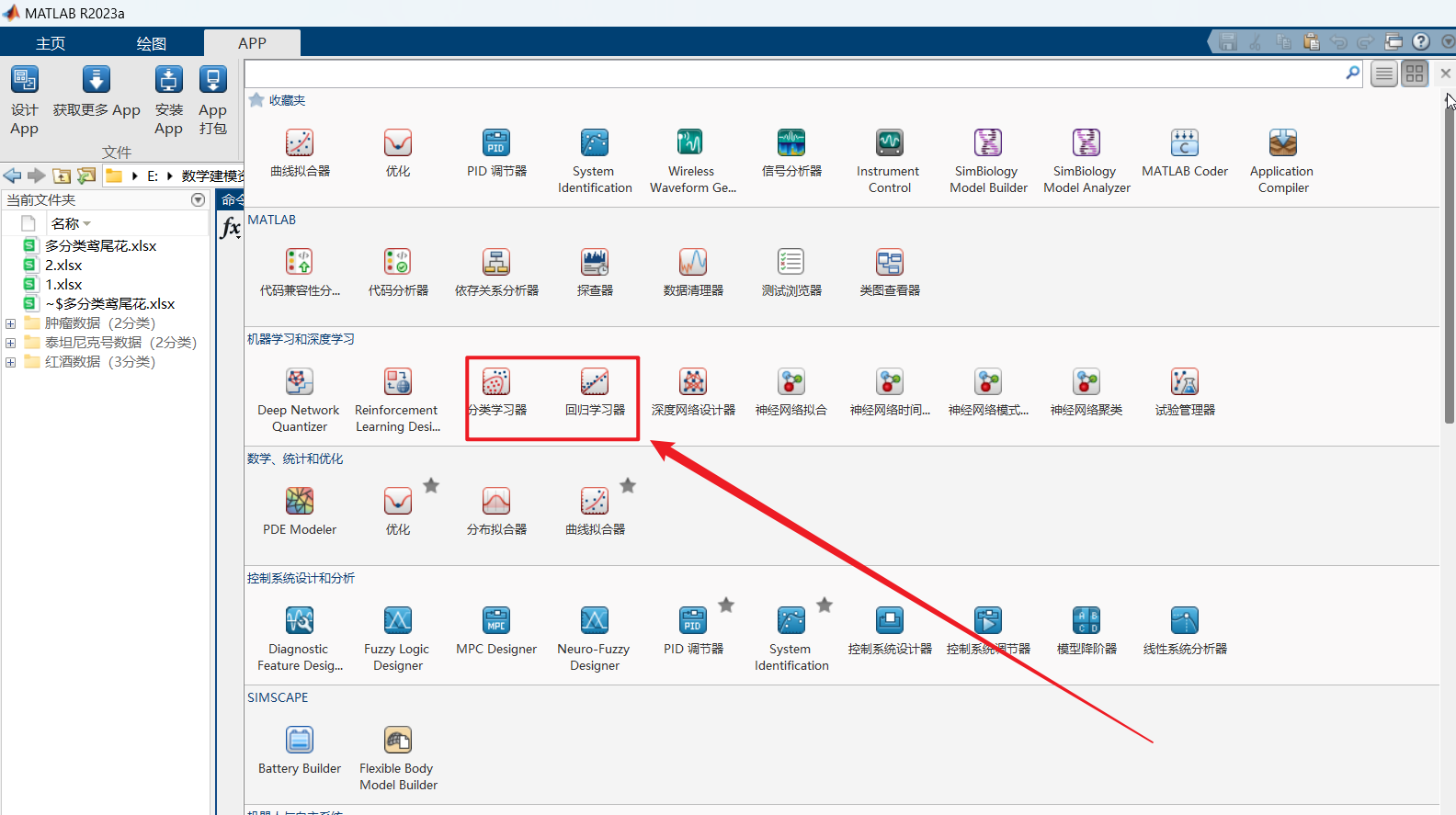
8.4分类学习工具箱使用
下面的这个就是两个工具箱位置,我们的这个案例使用的是这个分类学习工具箱的;
导入数据:这个刚开始是空白的,如果我们没有使用过的话,但是我们可以使用把工作区里面的这个数据导入进来;
导入过程:
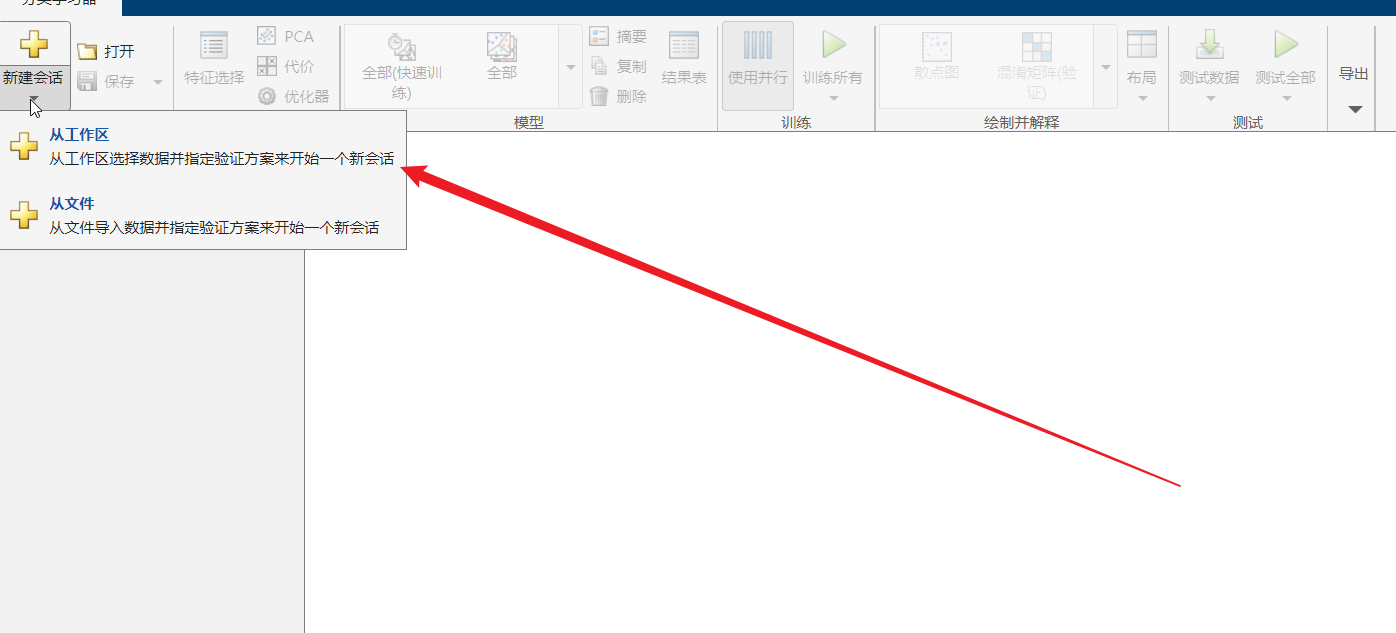
选择工作区里面的数据:就是我们回使用这个d1进行训练,因此这个里面使用的也是这个d1;
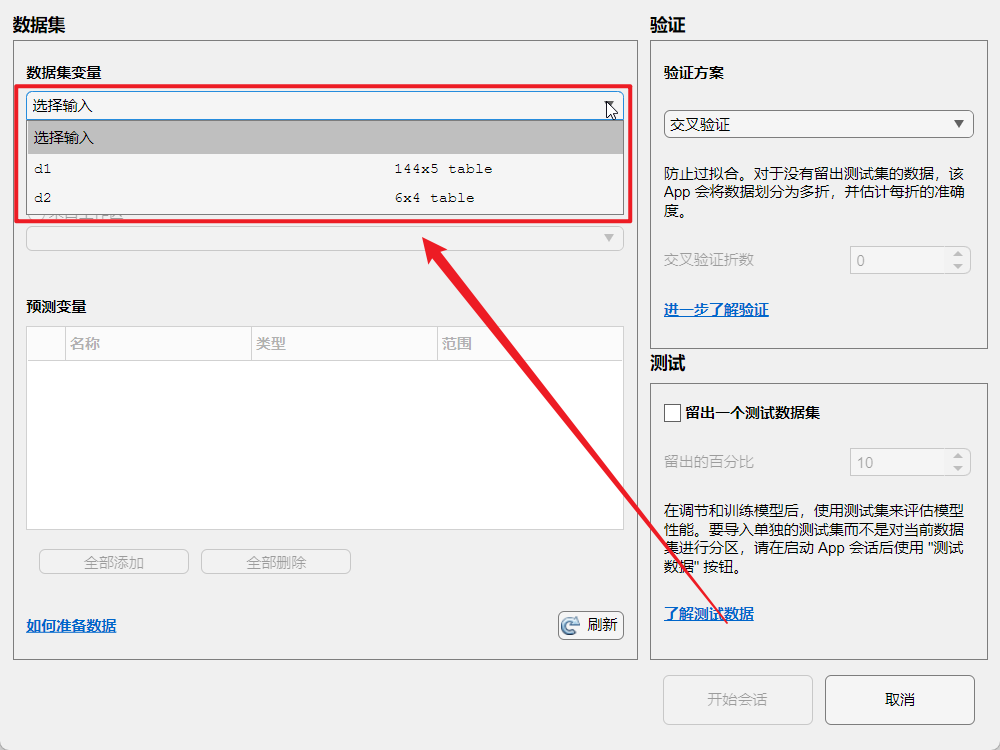
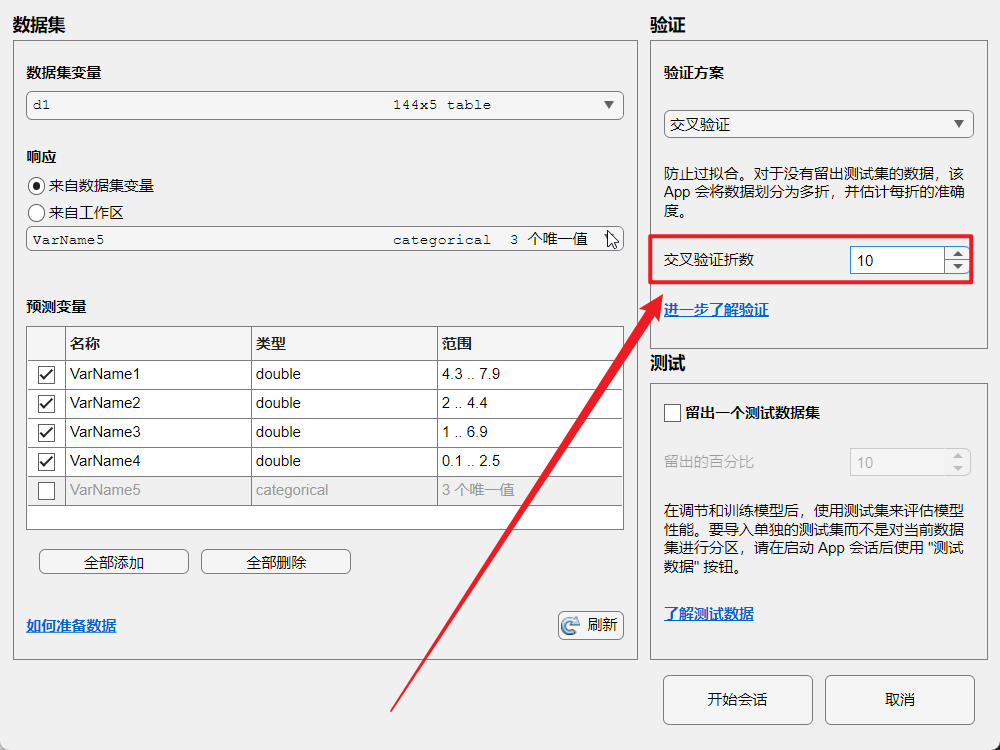
下面的这个页面使用的这个响应就是我们的输出变量,这个就是我们的花瓣的种类,下面的这个预测变量就是我们的输入变量(这个和老师的不一样,但是我们自行调整就可以了),K折交叉验证选择10就可以;
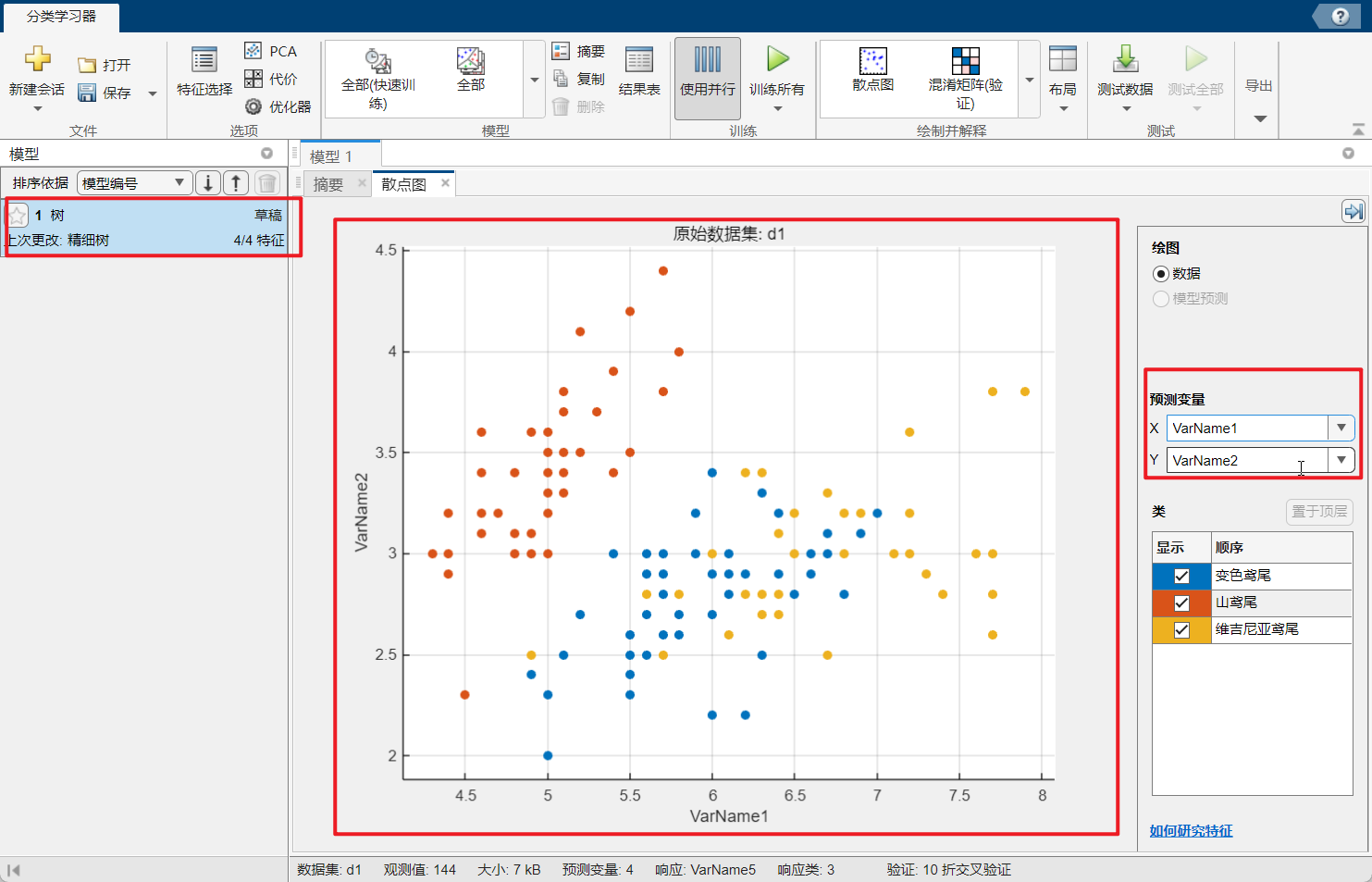
下面的这个就是我们训练的结果:主要就是这个散点图,右边的这个位置也是可以修改这个输入变量的,左边的这个就是我们的这次训练;
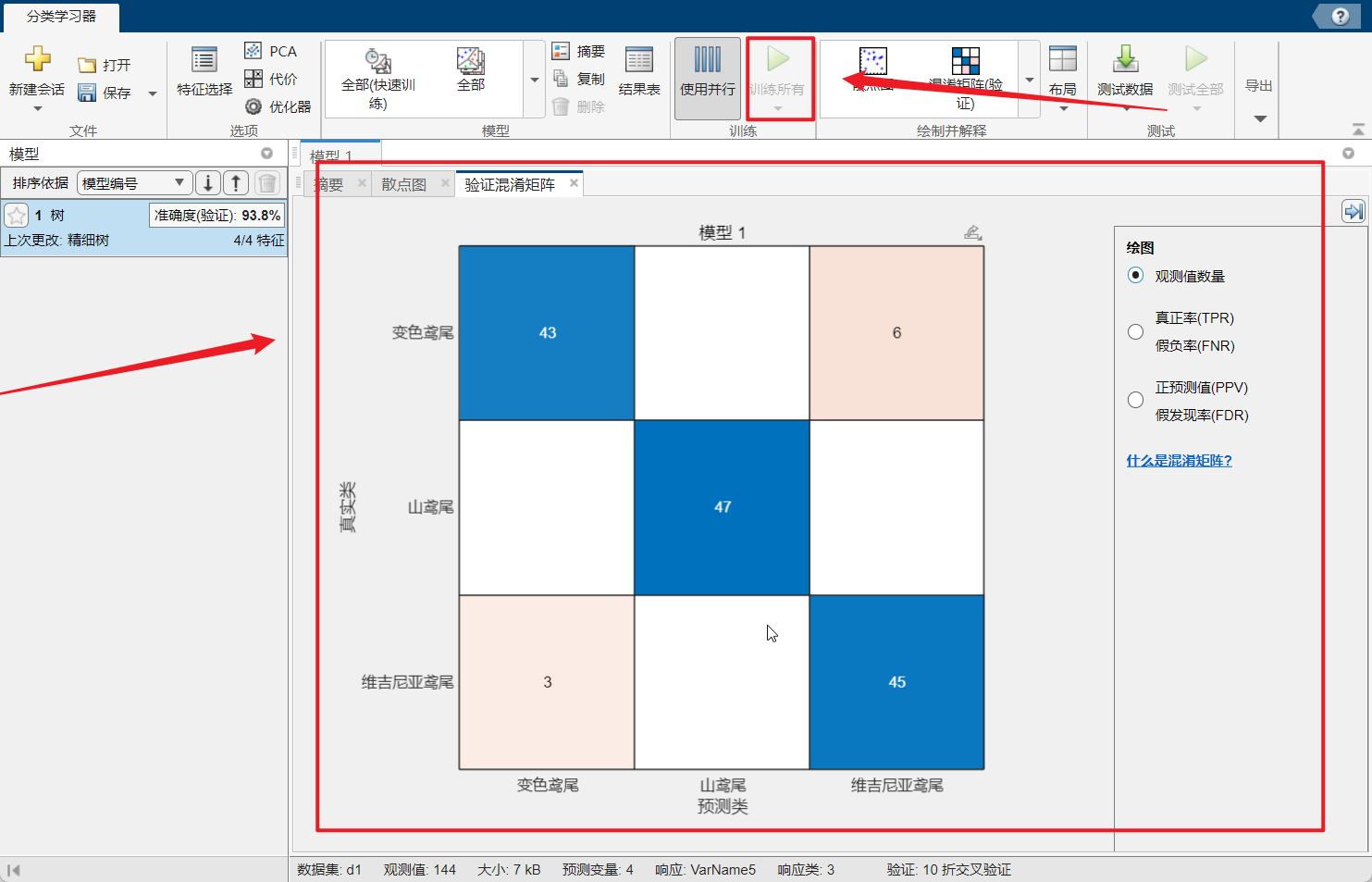
点击这个训练所有:这个显示的就是我们的这个混淆矩阵的情况,我的这个左边是只显示了一个准确率,老师的是很多个(这个我暂时还没有搞明白原因);
这个混淆矩阵就是我们上面介绍的,我们就可以自己根据图象进行分析;
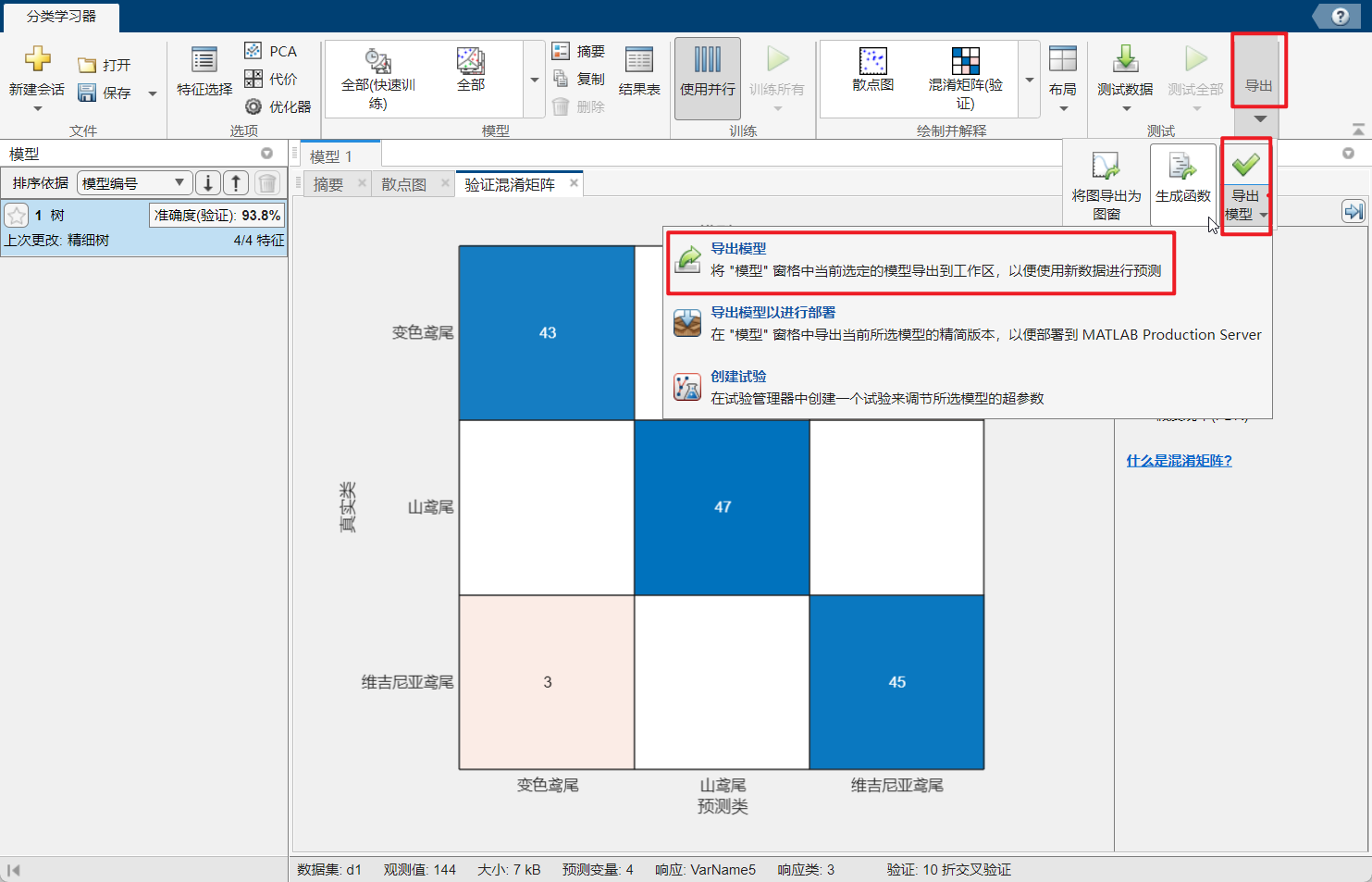
导出模型:进行d2的预测:
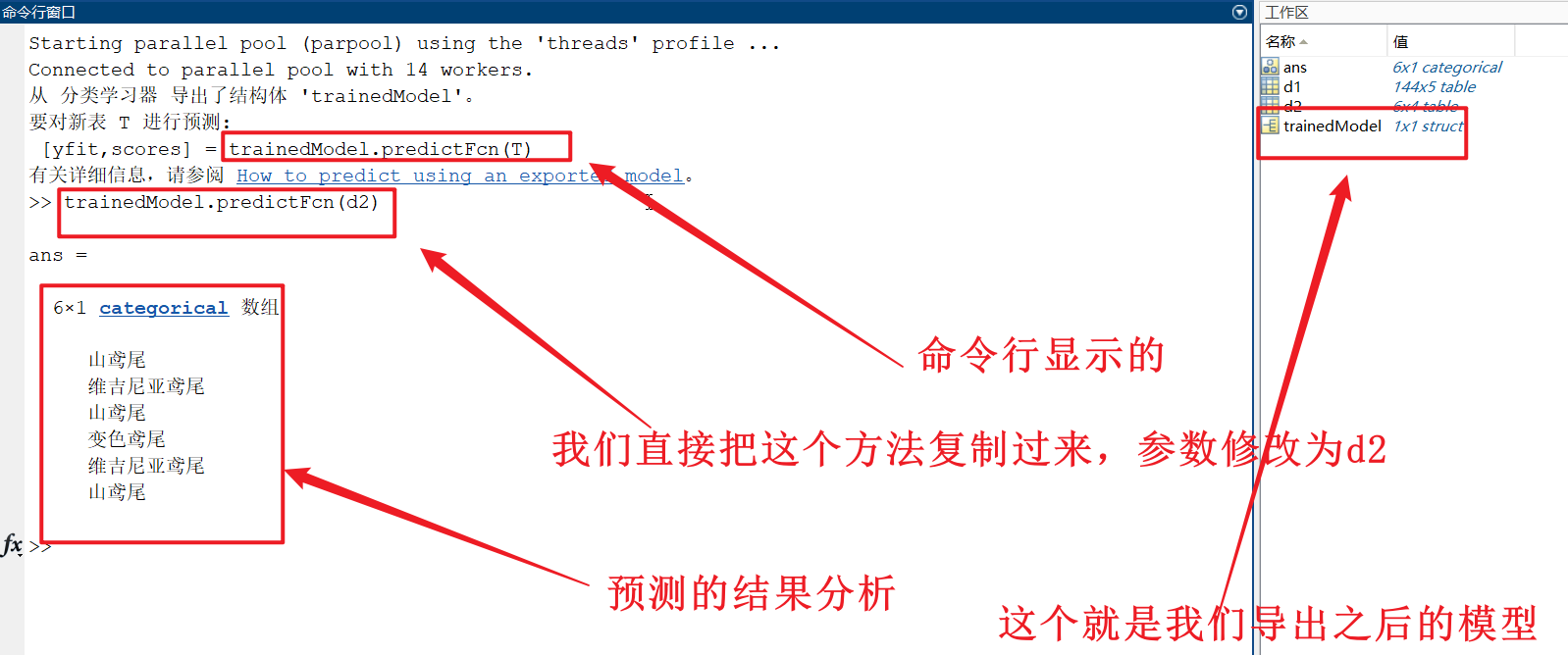
根据这个提示进行d2的预测:
8.5我的总结
这个只是一个demo吧,但是这个输出的结果并不可以直接使用,这个只是一次k折交叉验证的结果罢了,我们需要使用代码,调参进行验证之类的操作,这个还是任重而道远的,但是我觉得这个过程已经很可以让我这样的小白体会一把了,因为也是我自己也是第一次使用这个matlab里面的工具箱,进行这个预测的使用,感觉自己的这个收获还是很大的,我觉得最好还是在这个B栈上面找到视频,自己实操一下,这个收获会更大;
个只是一个demo吧,但是这个输出的结果并不可以直接使用,这个只是一次k折交叉验证的结果罢了,我们需要使用代码,调参进行验证之类的操作,这个还是任重而道远的,但是我觉得这个过程已经很可以让我这样的小白体会一把了,因为也是我自己也是第一次使用这个matlab里面的工具箱,进行这个预测的使用,感觉自己的这个收获还是很大的,我觉得最好还是在这个B栈上面找到视频,自己实操一下,这个收获会更大;