【SpringCloud】Kafka消息中间件
Kafka
- Kafka
- 消息中间件对比:
- kafka介绍
- 安装教程:
- 配置以及启动顺序:
- Kafka整合微服务
- 初级入门
- 测试:
- Kafka整合SpringBoot
- ①导入spring-kafka依赖信息
- ②消息生产者
- ③消息消费者
- Postman测试
Kafka
消息中间件对比:
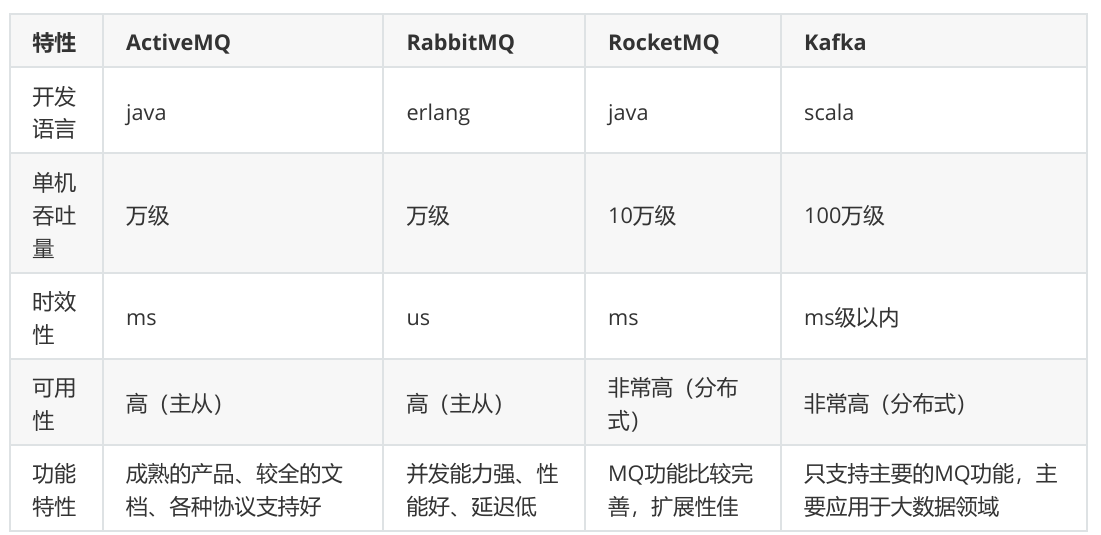
消息中间件对比-选择建议:

kafka介绍
Kafka 是一个分布式流媒体平台,类似于消息队列或企业消息传递系统。kafka官网:Apache Kafka
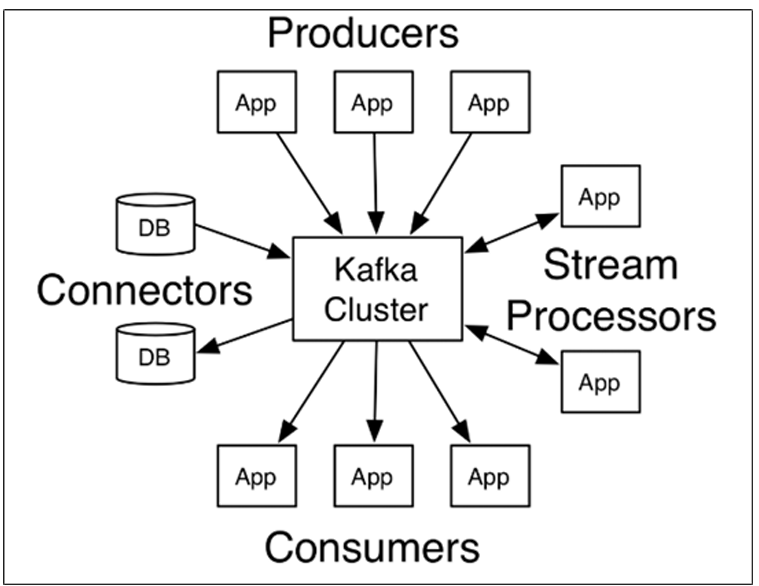
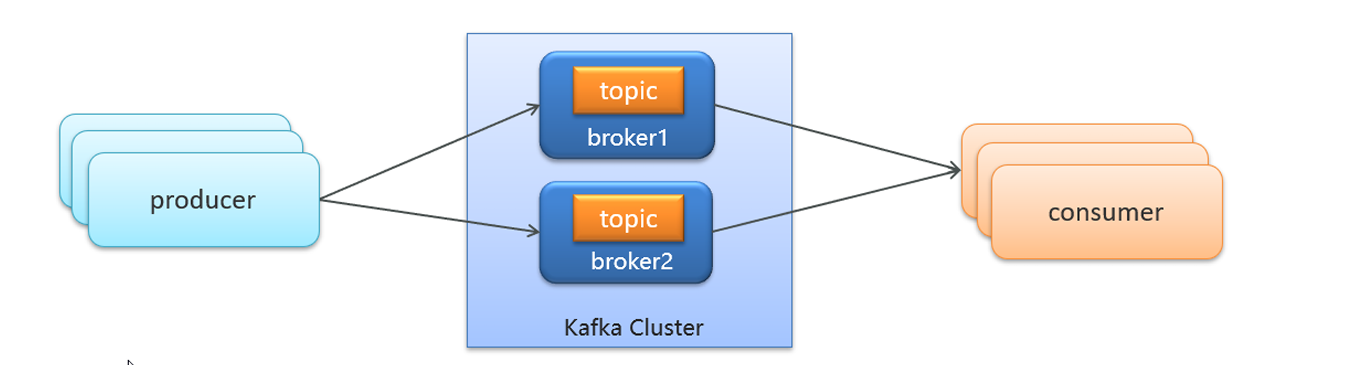
producer相当于生产者,consumer相当于消费者。
Kafka Cluster相当于快递驿站,broker1、broker2相当于1,2号快递员,topic为它们的要派送的快递;
- producer:发布消息的对象称之为主题生产者(Kafka topic producer)
- topic:Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)
- consumer:订阅消息并处理发布的消息的对象称之为主题消费者(consumers)
- broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
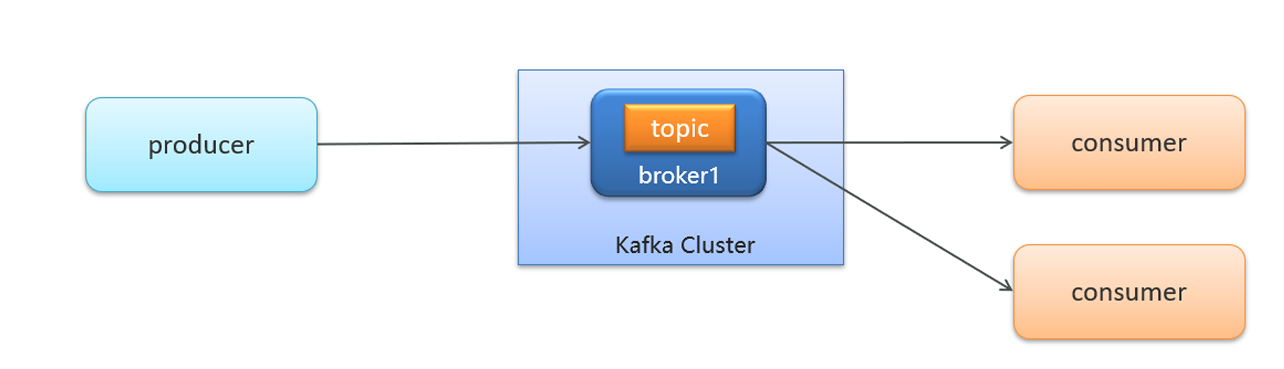
- 生产者发送消息,多个消费者只能有一个消费者接收到消息(一对一)
**理解:**相当于同一个快递员只能给一组快递的一个人派送快递,只有这个组的对应的一个人才能收到消息;
- 生产者发送消息,多个消费者都可以接收到消息 (一对多)
**理解:**相当于多个快递员给自己组的快递的一个人派送快递,各个组的对应的一个人都能收到消息;
安装教程:
windows系统kafka小白入门篇——下载安装,环境配置,入门代码书写_windows kafka-CSDN博客
配置以及启动顺序:
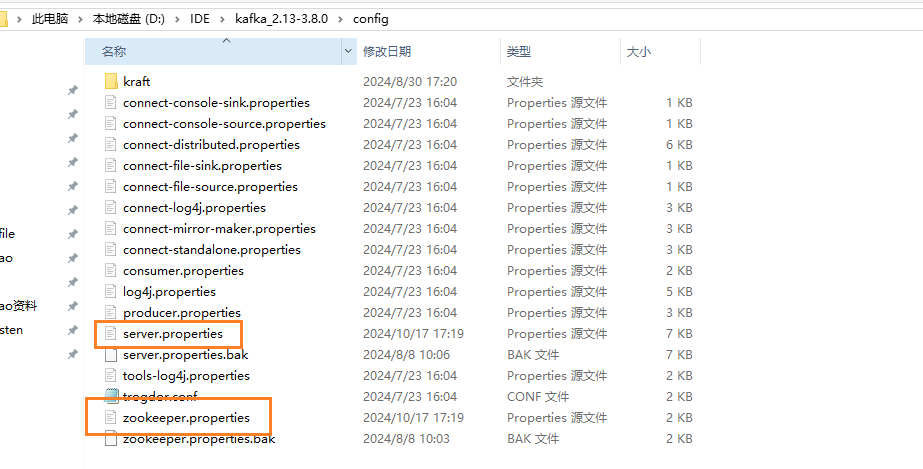

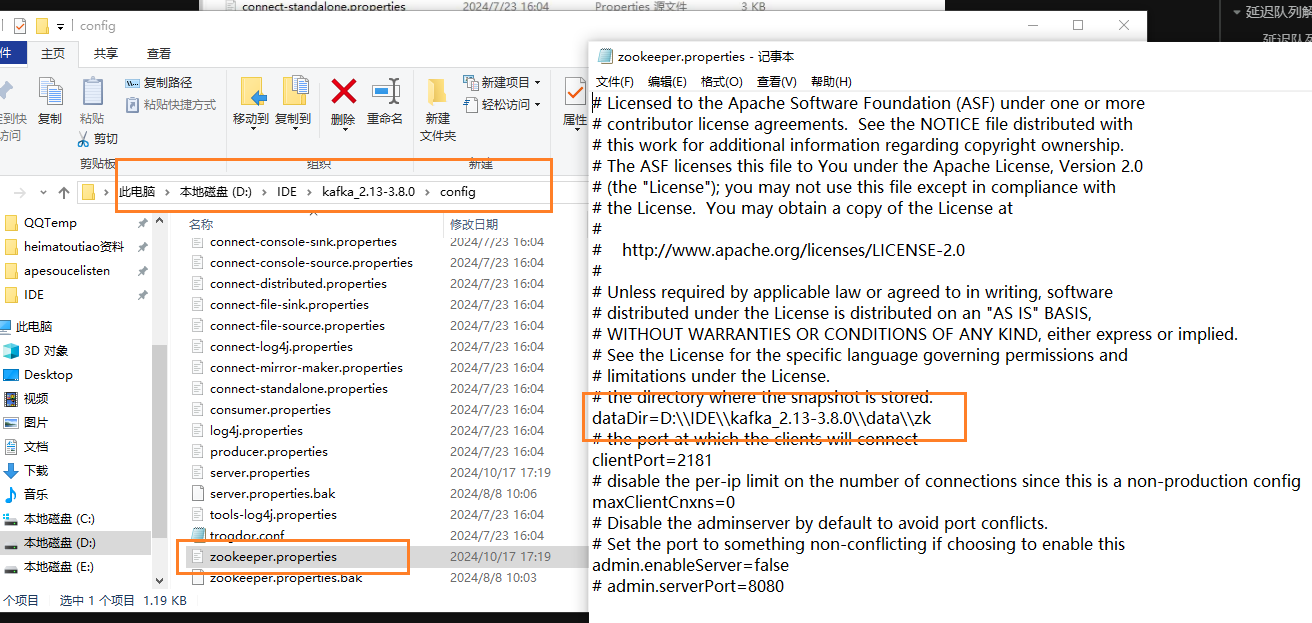
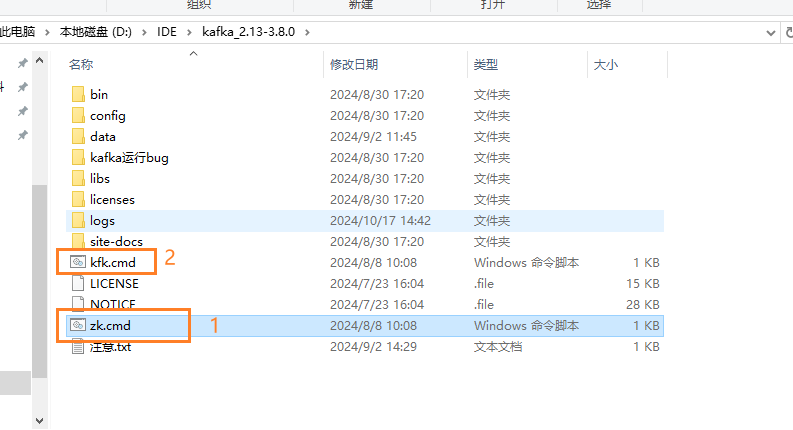
问题处理:
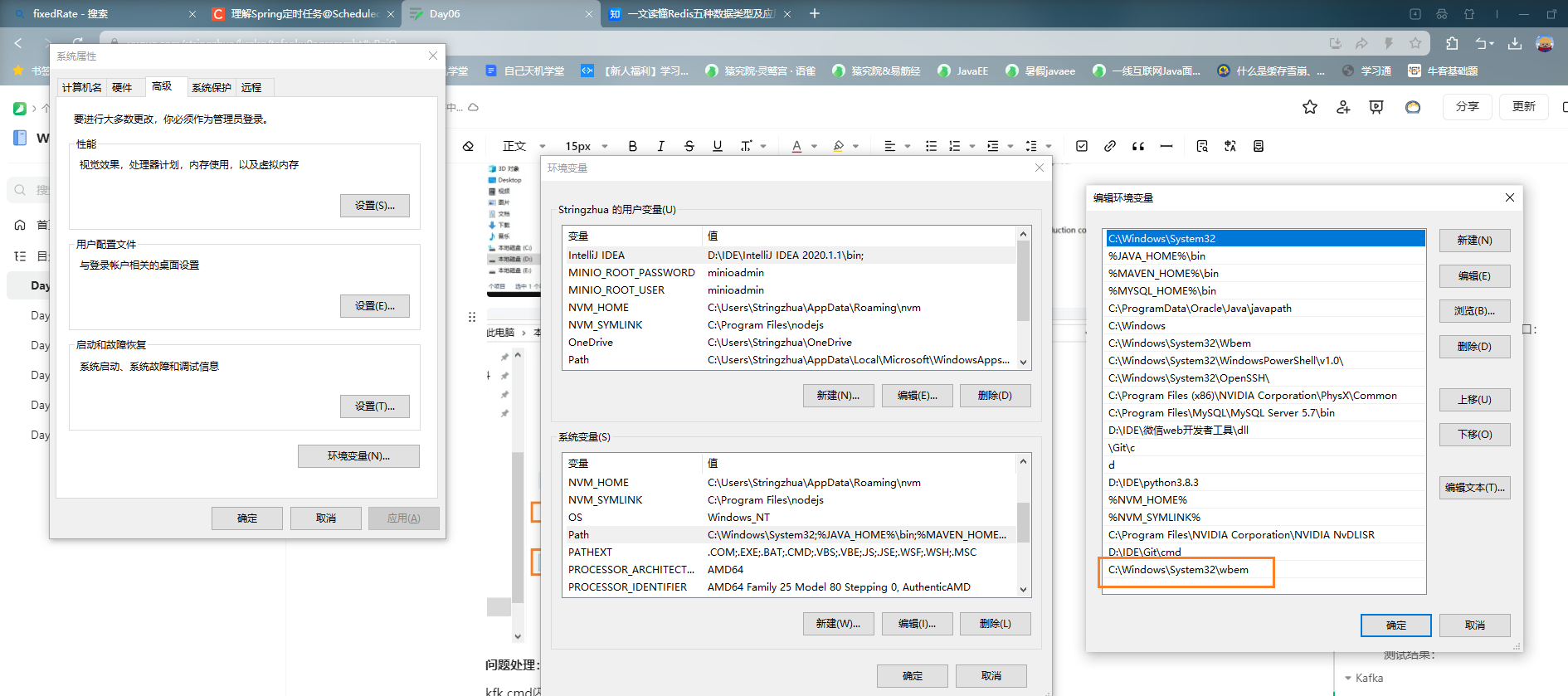
kfk.cmd闪退配置,配置环境变量https://blog.csdn.net/Xxy605/article/details/116844151
在环境变量path里面添加C:\Windows\System32\wbem
Kafka整合微服务
初级入门
①创建kafka-demo项目,导入依赖

<!-- kafkfa -->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId>
</dependency>
生产者发送消息:
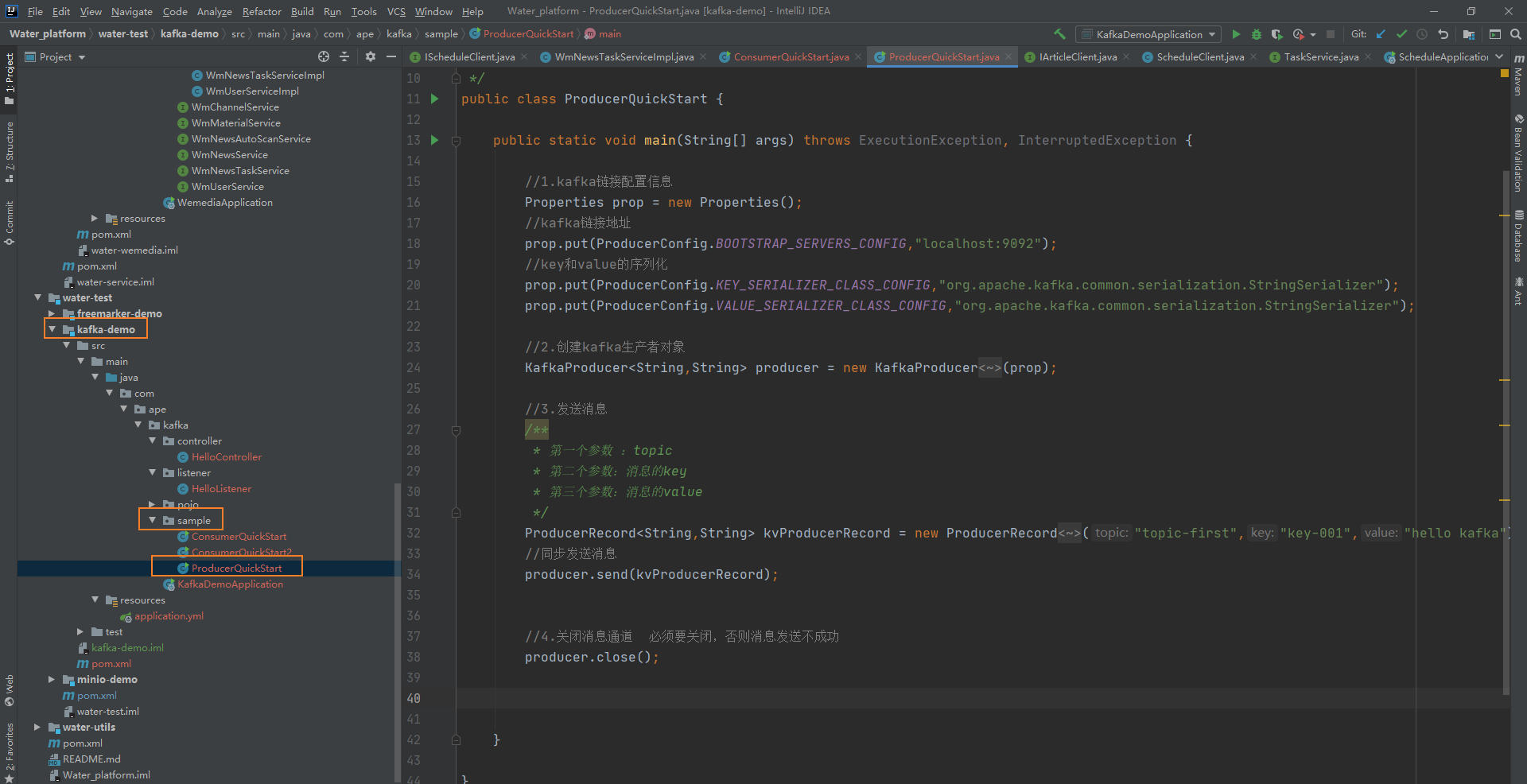
package com.ape.kafka.sample;import org.apache.kafka.clients.producer.*;import java.util.Properties;
import java.util.concurrent.ExecutionException;/*** 生产者*/
public class ProducerQuickStart {public static void main(String[] args) throws ExecutionException, InterruptedException {//1.kafka链接配置信息Properties prop = new Properties();//kafka链接地址prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");//key和value的序列化prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//2.创建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String,String>(prop);//3.发送消息/*** 第一个参数 :topic* 第二个参数:消息的key* 第三个参数:消息的value*/ProducerRecord<String,String> kvProducerRecord = new ProducerRecord<String,String>("topic-first","key-001","hello kafka");//同步发送消息producer.send(kvProducerRecord);//4.关闭消息通道 必须要关闭,否则消息发送不成功producer.close();}}
消费者1消费消息:
package com.ape.kafka.sample;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;/*** 消费者*/
public class ConsumerQuickStart {public static void main(String[] args) {//1.kafka的配置信息Properties prop = new Properties();//链接地址prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");//key和value的反序列化器prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//设置消费者组prop.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");//2.创建消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);//3.订阅主题consumer.subscribe(Collections.singletonList("topic-first"));//4.拉取消息while (true) {// 读取数据,读取超时时间为100ms ,即每个1000ms拉取一次ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.key());System.out.println(consumerRecord.value());}}}}
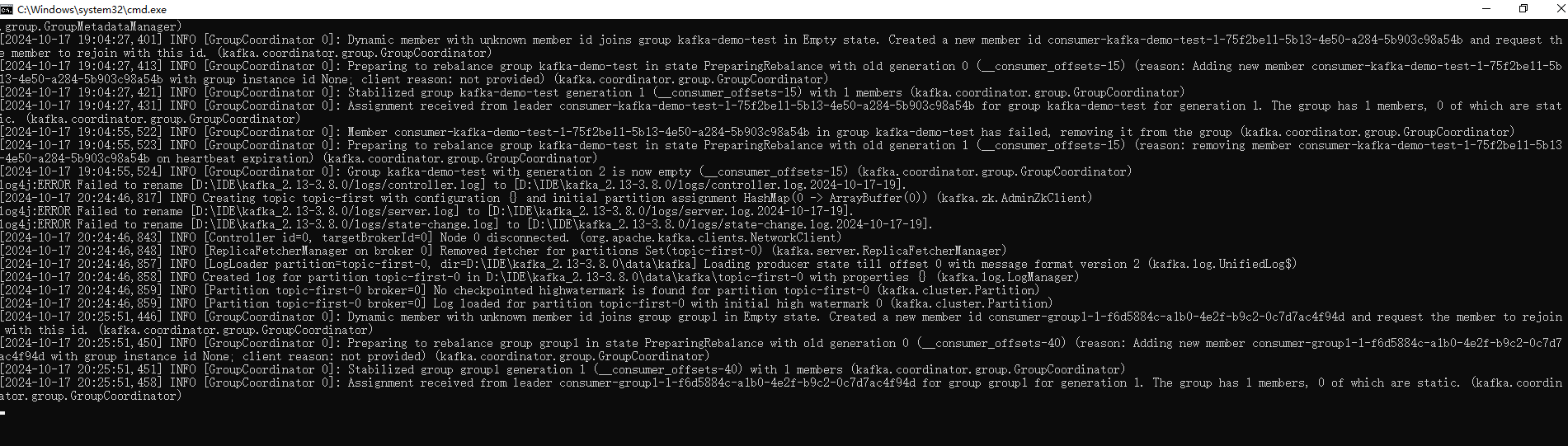 消费者2
消费者2
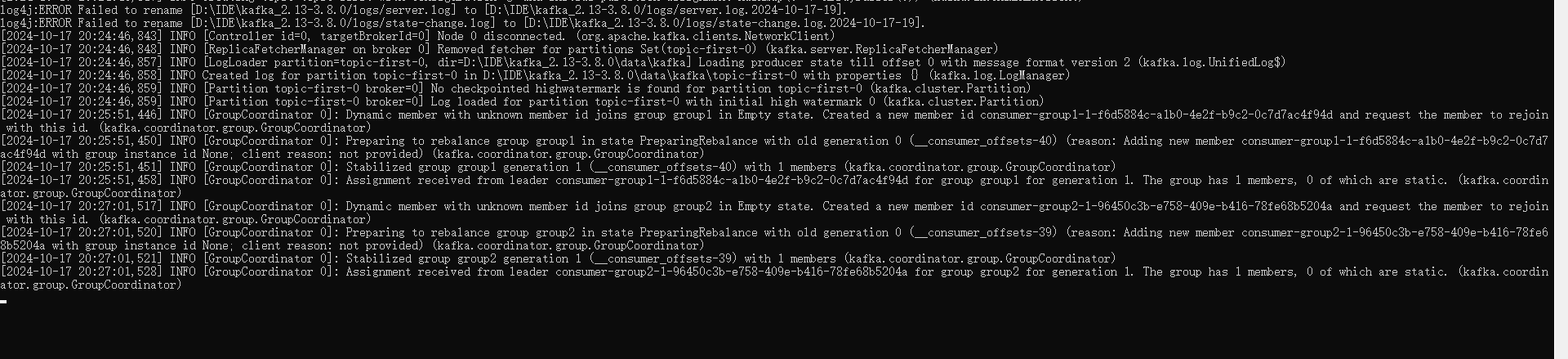
测试:
一对多
先启动俩个消费者1,2,然后在启动生产者:
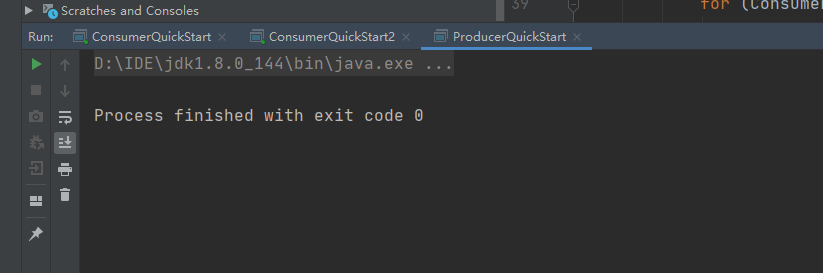
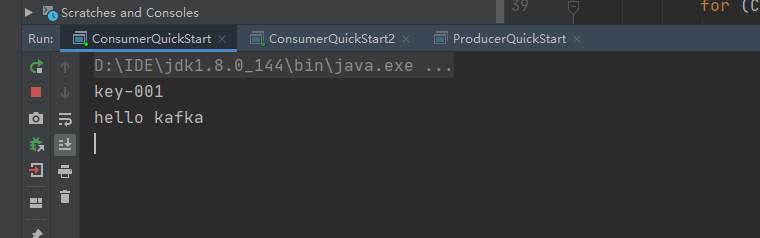
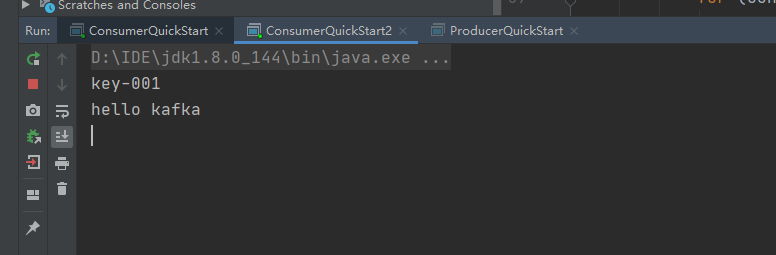
说明是一对多,对于不同的组group对应的这个人topic-first都能收到消息。
一对一:
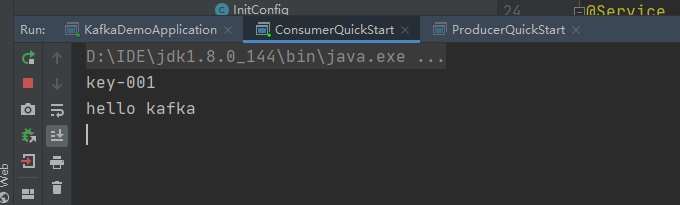
Kafka整合SpringBoot
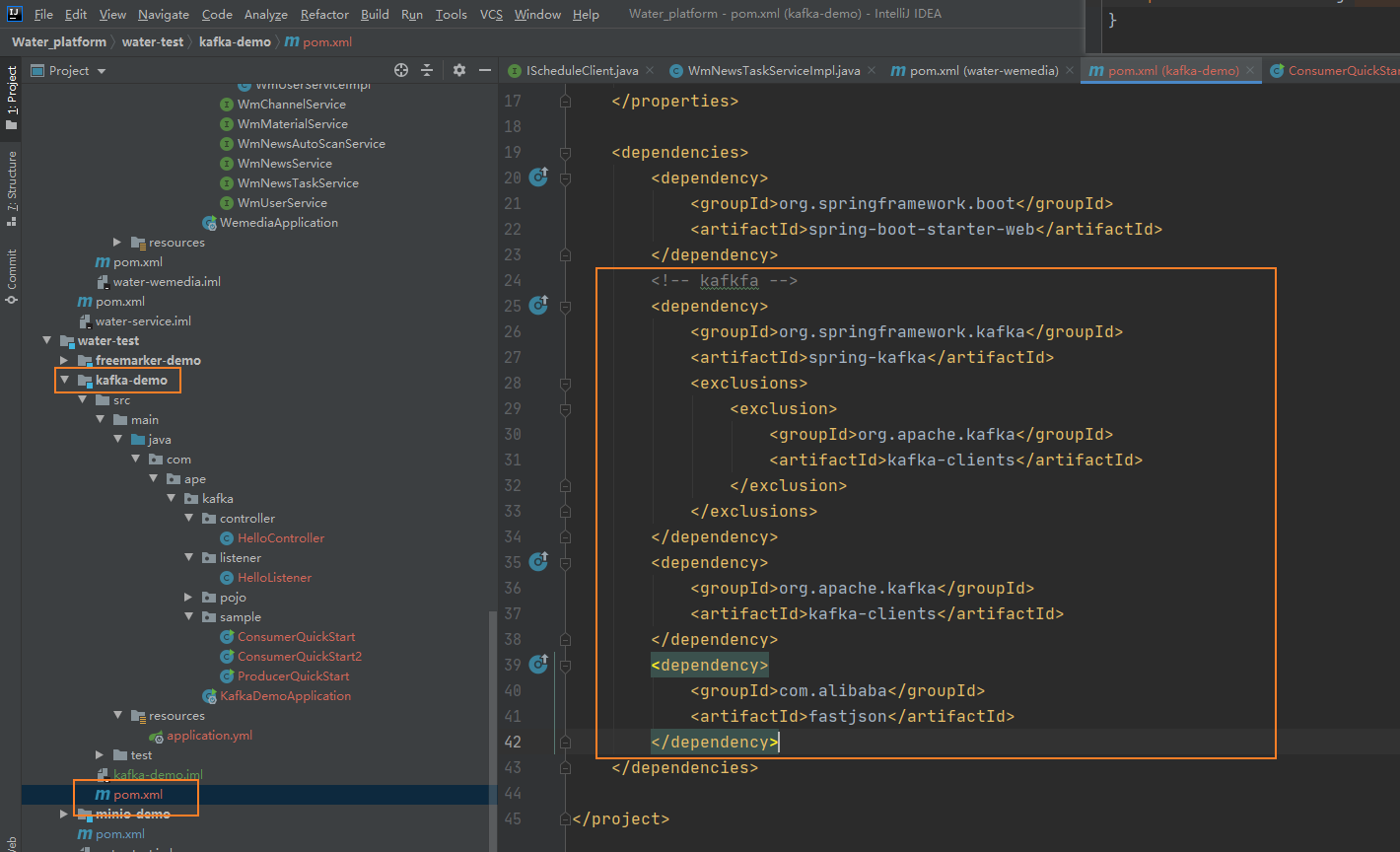
①导入spring-kafka依赖信息
<!-- kafkfa -->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId>
</dependency>
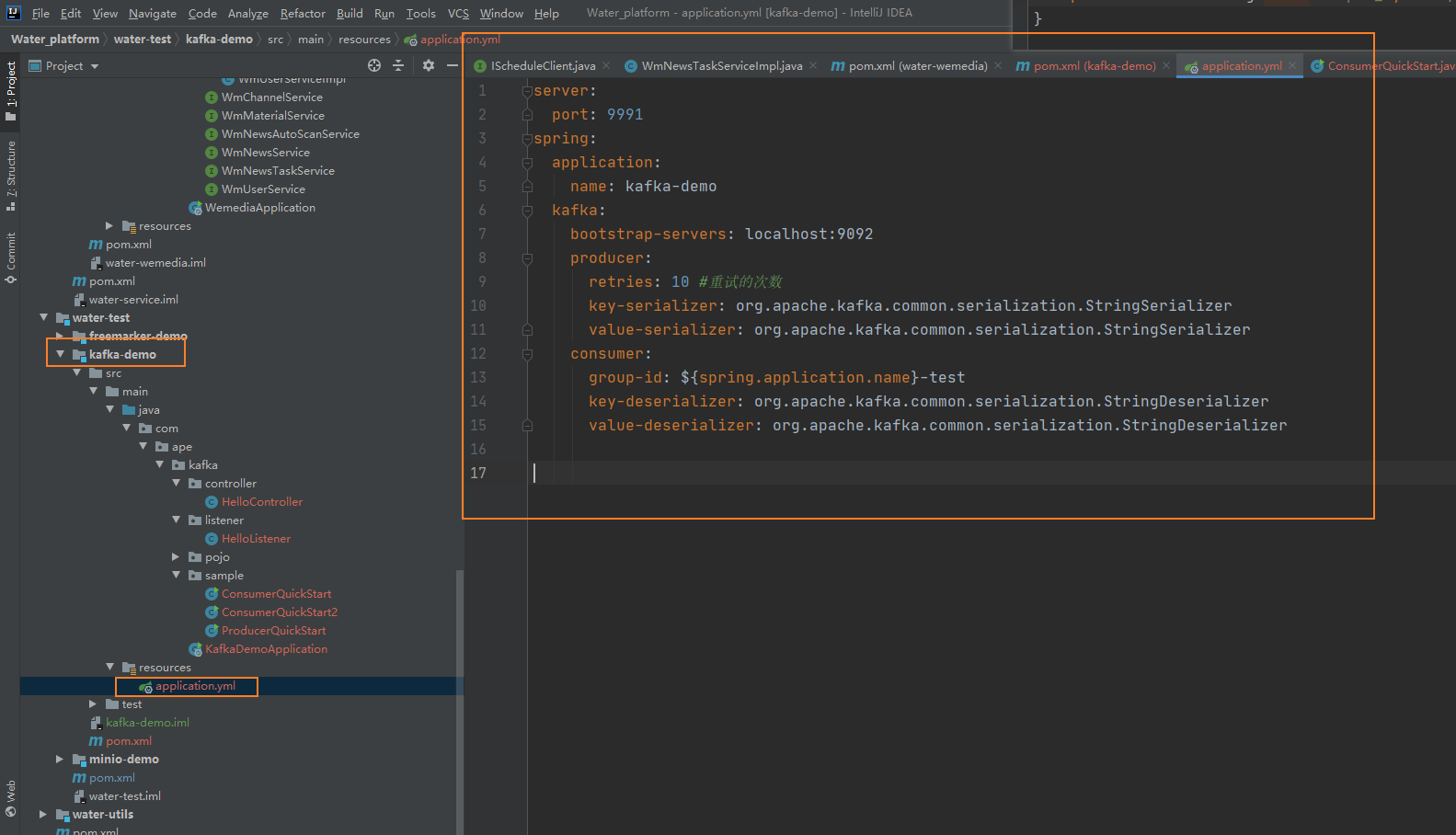
编写yaml文件:
server:port: 9991
spring:application:name: kafka-demokafka:bootstrap-servers: localhost:9092producer:retries: 10 #重试的次数key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: ${spring.application.name}-testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
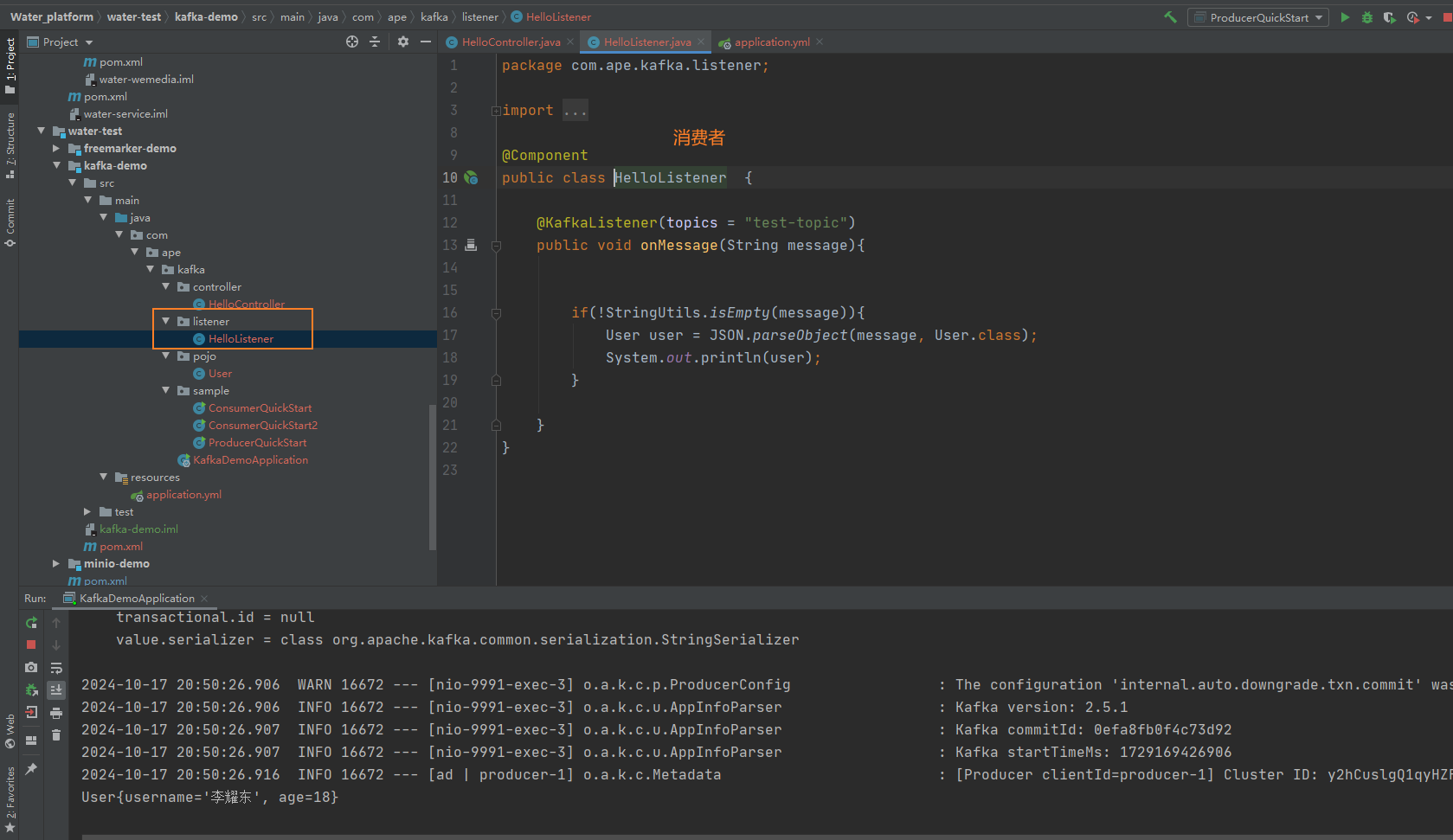
②消息生产者

③消息消费者
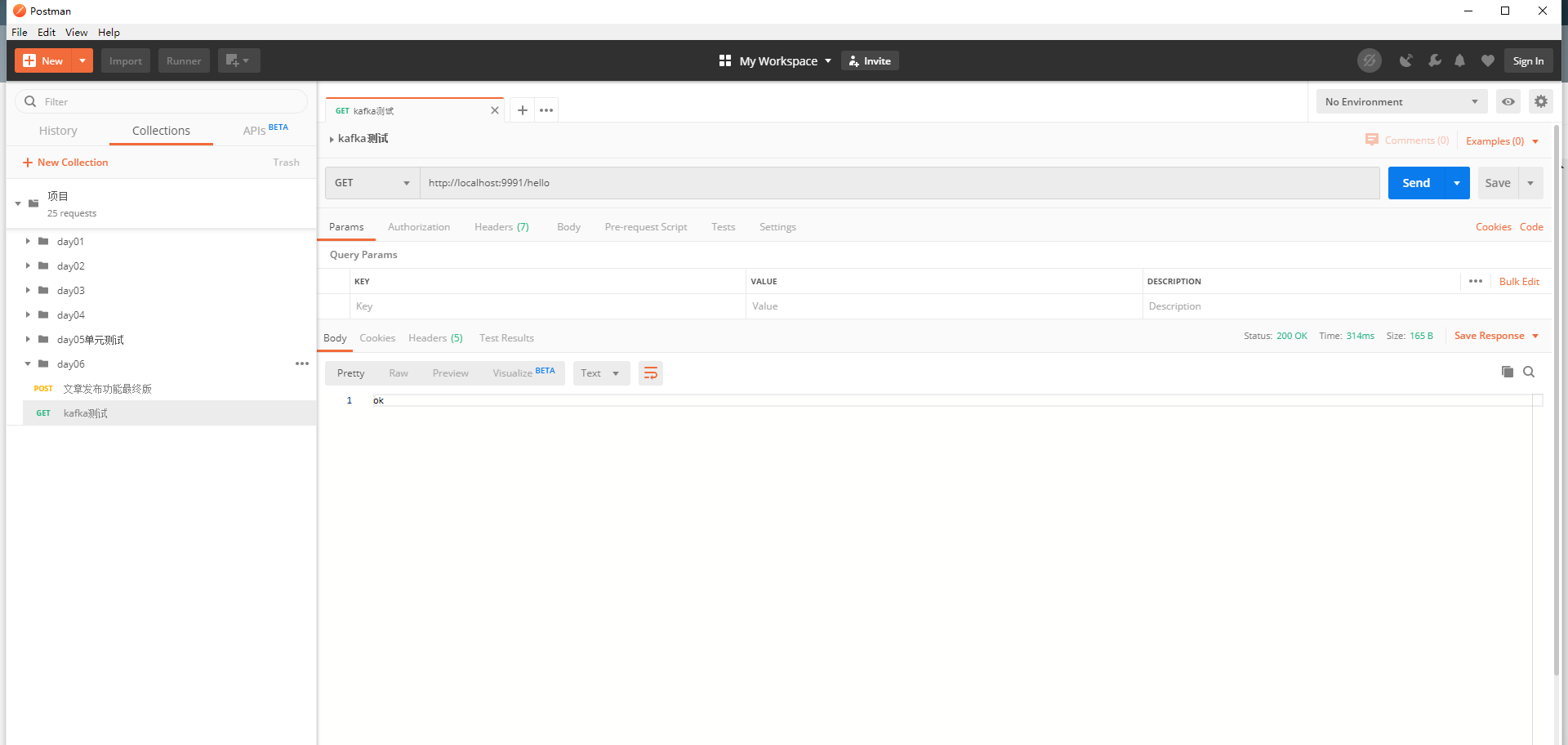
Postman测试
发送请求:http://localhost:9991/hello
控制台输出:
