多任务学习在转转主搜精排的应用
文章目录
- 1 引言
- 2 多任务学习概述
- 2.1 多任务学习的必要性
- 2.2 多任务学习的效用
- 2.3 多任务学习的实践
- 3 转转场景下的多任务学习
- 3.1 模型选型
- 3.2 未来规划
- 参考文献
1 引言
在搜推系统中,随着场景建模目标越来越丰富,我们越来越多的希望模型可以兼顾多个任务的建模,多任务学习(multi-task learning)逐渐走入了人们的视野,成为了当前精排模型的主流方向之一。在转转的搜索场景中,用户的每个行为背后都有其特定的考虑因素,这也导致了不同行为之间流量效率的差异。下图展示了用户在详情页所看到的信息,其中包括收藏、加购、咨询等行为按钮,这些行为为精排模型预测用户的最终决策——是否购买——提供了重要的参考。基于此,我们在建模时需要全面考虑用户的决策链路,以实现最优的模型效果。
2 多任务学习概述
2.1 多任务学习的必要性
如果为每个行为单独设计模型进行单目标建模,并将其输出最终结合使用,除了增加工程上的复杂性外,模型可能会面临信息孤立的问题,无法充分利用不同目标之间的相关性,导致整体性能下降。独立训练每个模型会显著增加训练时间和计算资源的消耗,从而降低系统迭代效率。多个模型的存在还可能增加过拟合的风险,在某些行为样本量较少时尤为明显。管理和维护多个模型也会使复杂性加大,为模型的部署带来挑战。
此外,由于不同模型之间的优化目标可能存在冲突,例如点击率与转化率之间的关系往往难以进行协调优化。在转转的场景里,前者可能通过给低价商品更多曝光来吸引更多点击,而后者则强调精准性和质量,过于关注点击率可能导致转化率的下降。这种相互矛盾的优化目标使得在模型训练和调优过程中,难以找到各目标之间的最佳平衡点,最终可能导致整体效果不尽如人意。同时,当不同模型的优化方向相互冲突时,可能会造成资源浪费,影响决策的效率,进而影响业务的长期发展。因此,寻找一个能够同时兼顾多种目标的建模方法显得尤为重要。
当然,借助多任务学习的方式虽然不能完全避免多个优化目标之间的冲突,但它可以在整体上实现对多个目标的有效权衡,从而获得更优的结果。
2.2 多任务学习的效用
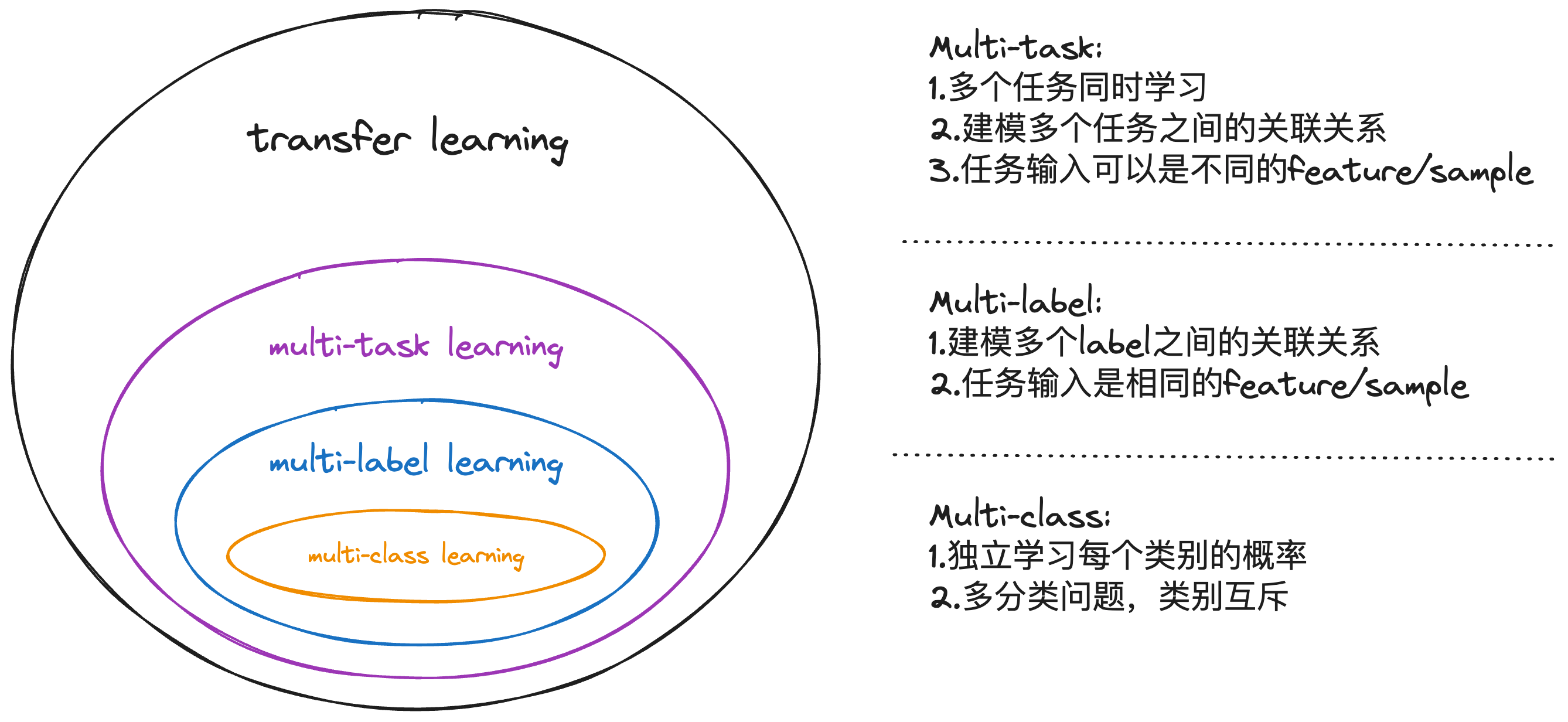
深度学习涉及的应用领域有多个multi相关的概念,除了多任务multi-task,还包括多标签multi-label,多类别multi-class等,他们之间的关系如图所示:
-
multi-task: 这里的task可以是分类或者回归任务。不同的任务有着不同的样本或者特征,同时也有一部分特征与样本共享。
-
multi-label:
多标签multi-label表示对样本进行多个维度的分类,是multi-task的一种,区别在于multi-label是用了相同的样本和特征进行建模。 -
multi-class:
多分类multi-class表示分类结果有多种选项。
多任务学习通过知识共享、减少过拟合、提升泛化能力、优化效率、任务间相互促进以及动态调整模型关注点等机制,有效提升模型在复杂问题上的表现。通过共享信息和特征,模型更好地捕捉数据模式;通过多个任务的共同训练,降低单任务的过拟合风险并提高泛化能力;同时训练多个任务提高了效率,节省计算资源;某些辅助任务还可以为主任务提供监督信息,进一步优化效果。
2.3 多任务学习的实践
多任务学习相比于单独建模的核心优势在于不同任务之间的网络可以进行共享,实现多个任务共同提升的效果,因此如何设计有效的网络结构成为多任务学习的一个重要研究方向。在引入多个label时,自然会产生多个loss,如何制定优化策略在联合训练中让整体的loss达到最佳也是模型能否取得更好收益的关键。
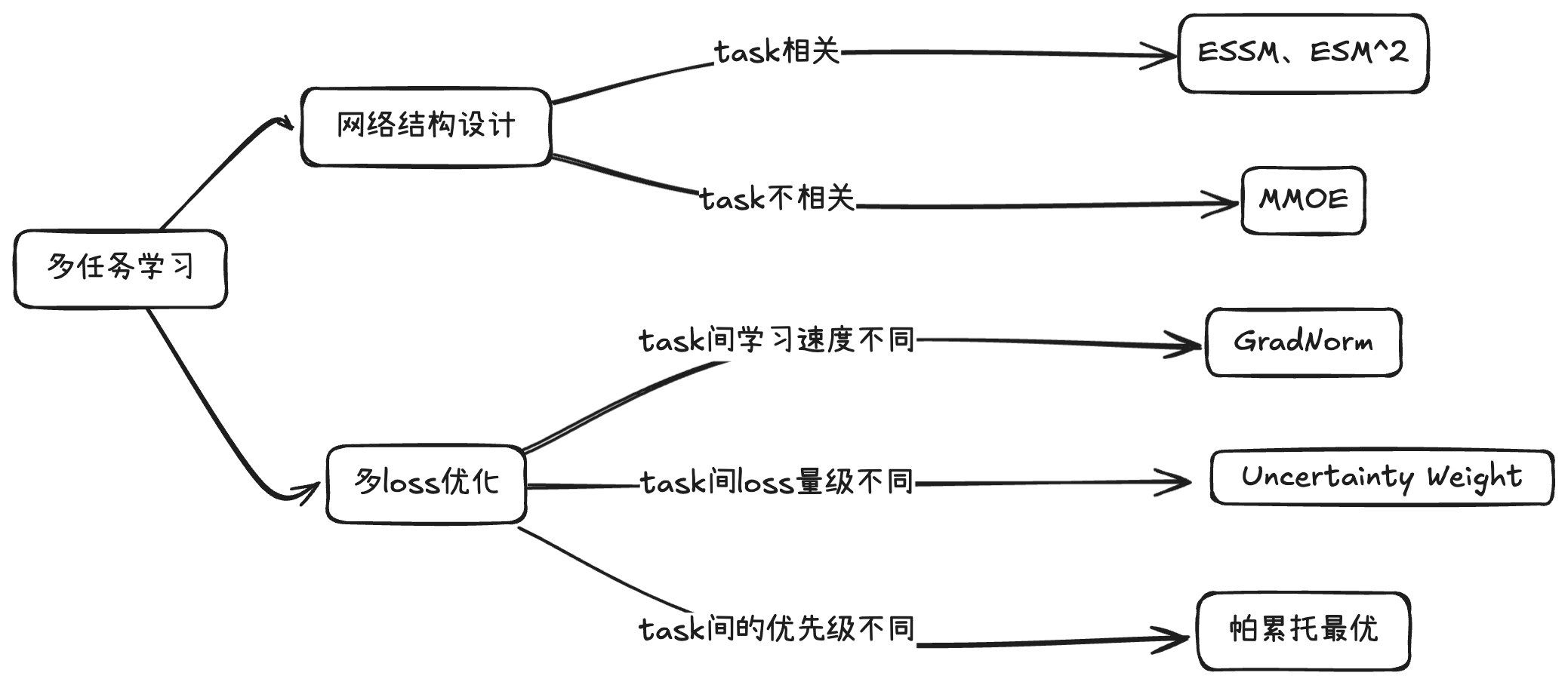
网络结构设计:这一方向主要关注哪些参数可以共享、在何处共享以及如何共享。我们可以将其分为两大类:第一类是在设计网络结构时考虑任务之间的显式关系,例如淘宝中点击与购买之间的关系,以阿里提出的ESMM模型为代表;第二类则是任务间没有显式关系的情况,例如短视频中的收藏与分享,在这种情况下,模型设计时不考虑标签之间的量化关系,以谷歌提出的MMOE模型为代表。
多loss优化策略:这一策略主要解决损失值差异、学习速度不均以及更新方向不一致等问题。两个经典的工作包括UWL(Uncertainty Weight)和GradNorm。UWL通过自动学习任务的不确定性,为不确定性大的任务分配较小的权重,而为不确定性小的任务分配较大的权重;GradNorm则结合任务梯度的二范数与损失下降梯度,引入加权损失函数Gradient Loss,并通过梯度下降更新该权重。
3 转转场景下的多任务学习
3.1 模型选型
早期转转搜索场景的精排CVR模型同时建模的两个目标分别为“下单”和“支付”。考虑到两个task之间存在递进关系,在模型选型时使用了与ESMM相同的结构。ESMM论文所要解决的两个关键问题:样本选择偏差(Sample Selection Bias)和样本稀疏(Data Sparsity):
-
样本选择偏差(Sample Selection Bias) :转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。即是说,训练数据与实际要预测的数据来自不同分布,这个偏差对模型的泛化能力构成了很大挑战。
-
样本稀疏(Data Sparsity) :作为CVR训练数据的点击样本远小于CTR预估训练使用的曝光样本。
这篇论文通过同时学习CTR和CTCVR两个目标,间接学习并优化CVR目标,从而有效规避了上述两个问题,使CVR模型的性能得到了提升。
在应用于转转搜索场景时,CVR模型建模路径为“点击->下单->支付”。如果直接建模“点击->支付”,则会丢失“下单”行为所包含的重要信息;而若将“点击->下单”和“下单->支付”两个阶段分开建模,除了增加工程复杂性外,“下单->支付”模型还将面临更加严重的样本稀疏问题。我们的模型结构如下图所示:
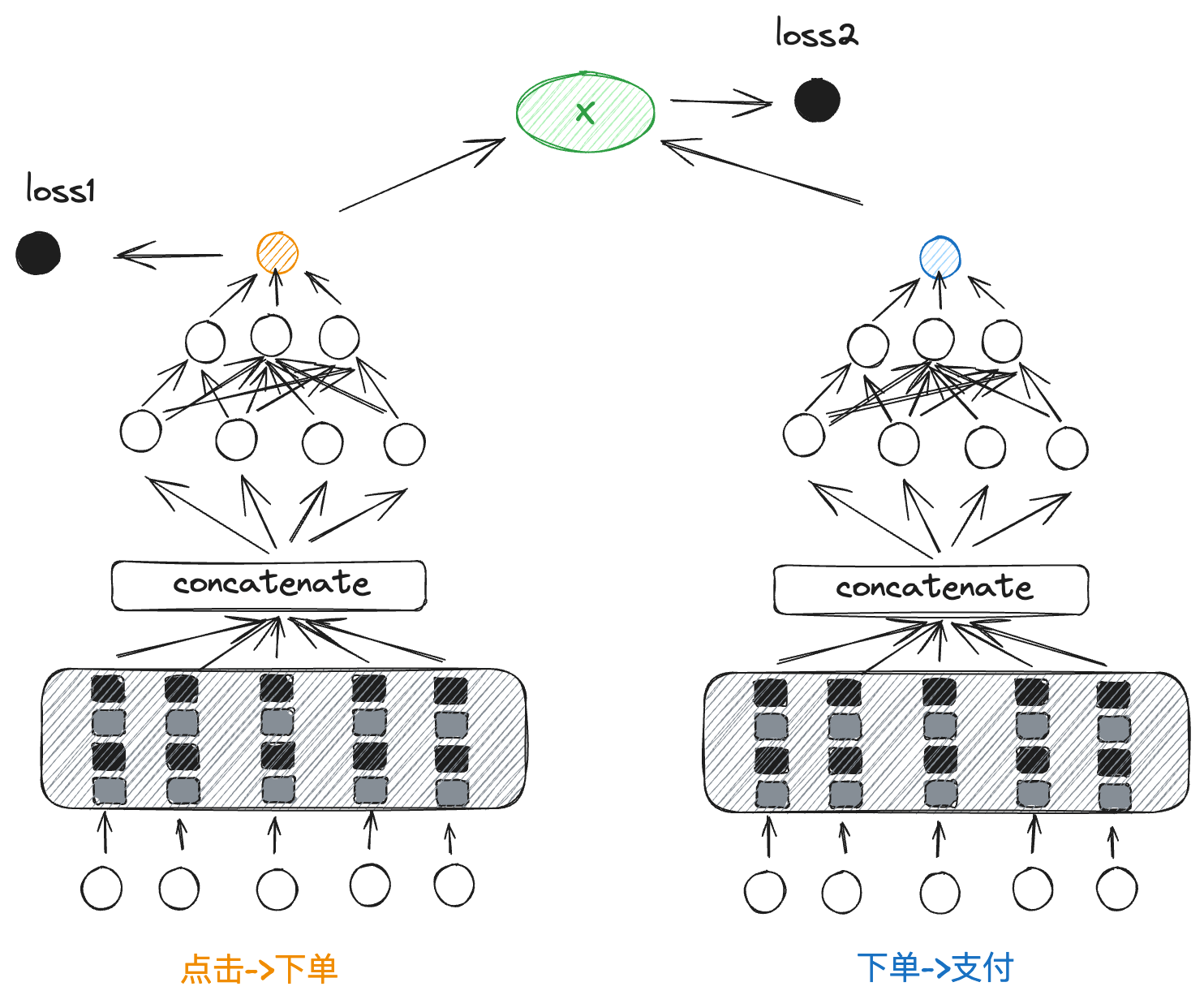
具体实现上会构建两个塔用于预测“点击到下单”和“下单到支付”两个任务。模型分别输入两组特征,其中包含部分共享特征。两个塔共享底层特征的embedding,然后分别通过上层网络进行特定任务的预测。在“点击到下单”和“下单到支付”两条分支中,各自的特征经过多层网络后在 concatenate 层融合,再通过更深层网络得到预测结果,并分别计算损失 loss1 和 loss2。这种结构通过共享特征提高了模型的整体效果,同时兼顾了两个任务的优化。在线上预测时,会使用两个塔输出的乘积作为CVR模型的最终打分。
在确定基本框架后,我们在此基础上进行了一些尝试,例如将每个塔从W&D替换为DeepFM、DCN等模型,为两个塔的loss设置不同权重,以及对比同时训练和分别训练两个塔的效果等。然而,这些调整并未带来显著的性能提升。对模型效果影响最大的,仍然是样本和特征的优化。值得注意的是,模型只有结合具体业务场景才能最大限度地发挥作用。接下来,我们计划将“收藏”行为纳入建模目标。做出这一决定的主要原因在于统计结果显示,用户对收藏夹中商品有着更高的成交概率,同时使用收藏功能的用户比例也相当可观。尽管我们此前在样本和特征中对收藏行为做了一些描述,但这显然还不够。
加入收藏行为之后,用户的决策路径不再是单一的,CVR模型需要建模的路径如下所示:
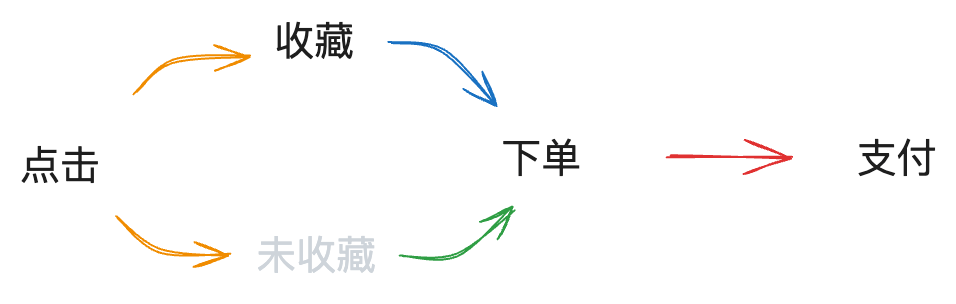
在对比了其他的多目标模型之后,我们还是决定参考阿里对ESMM的改进,将ESM^2应用到我们的场景中。模型从原先的两个塔扩展为了四个塔来为“收藏”、“下单”和“支付”三个目标进行建模,模型结构如下图所示:
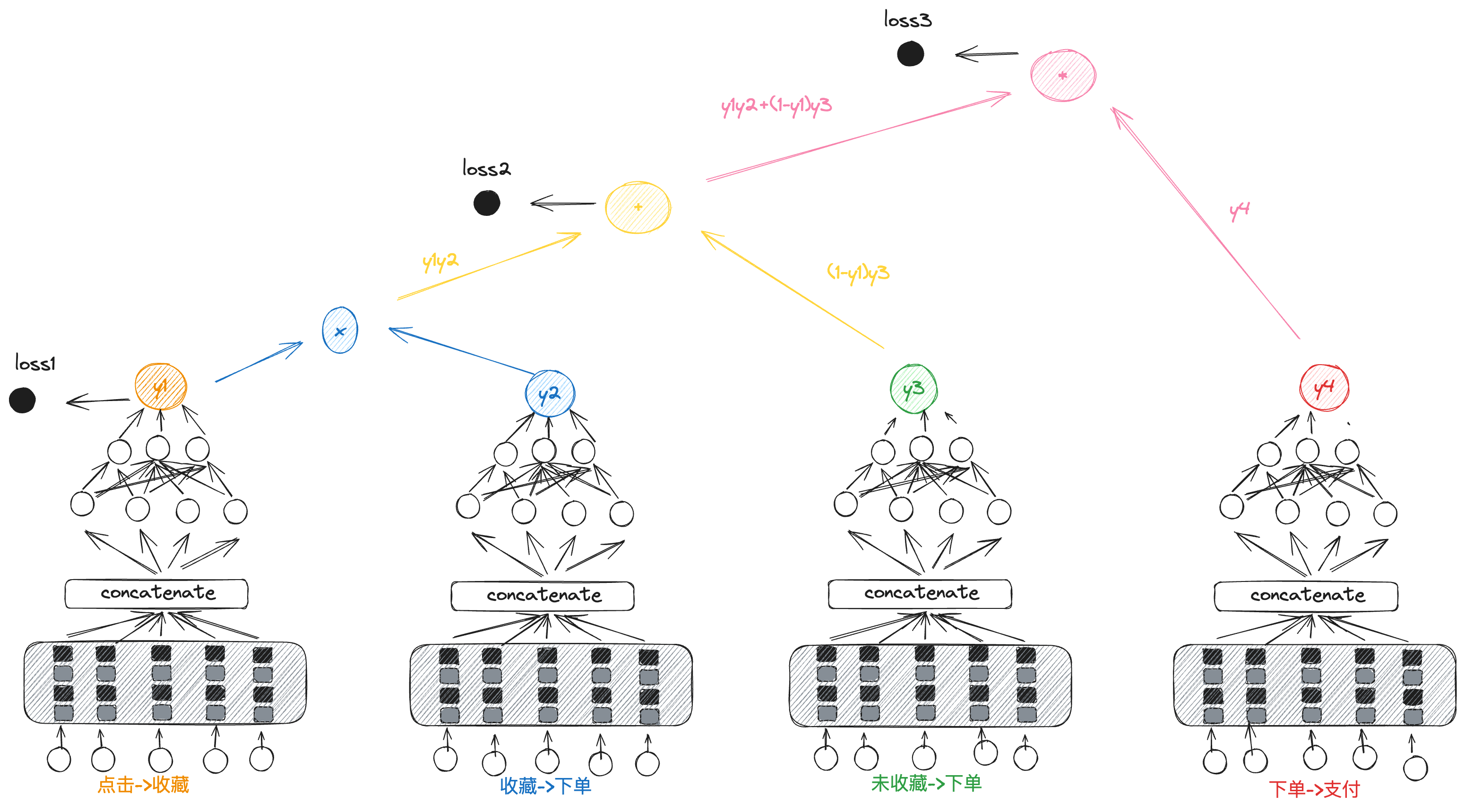
做出这样选的的主要考量在于,这三个task之间存在的路径依赖。需要注意的是,输出为 y 2 y_2 y2、 y 3 y_3 y3 和 y 4 y_4 y4 的塔均是通过隐式学习的方式实现的,并没有单独的label来指导这几个塔的参数更新。其输出所代表的含义仅限于概率层面,反映的是在模型中通过隐式关联所学习到的潜在信息,而非直接通过明确的标签进行的监督学习。模型对“点击->下单”环节的预测概率( p 下单 p_{下单} p下单)可以使用如下的公式进行表示:
p 下单 = y 1 ∗ y 2 + ( 1 − y 1 ) ∗ y 3 p_{下单}=y_1*y_2+(1-y_1)*y_3 p下单=y1∗y2+(1−y1)∗y3
模型在线上预测时其对整个链路的预测结果 y y y如下所示:
y = [ y 1 ∗ y 2 + ( 1 − y 1 ) ∗ y 3 ] ∗ y 4 y=[y_1*y_2+(1-y_1)*y_3]*y_4 y=[y1∗y2+(1−y1)∗y3]∗y4
3.2 未来规划
未来计划为模型引入attention机制为用户行为序列进行建模,样本层面考虑加入用户APP其他场景的行为数据,对于泛意图搜索探索多个类目的结果更好的融合方式。
参考文献
[1] 多目标优化概论及基础算法ESMM与MMOE对比: https://www.cnblogs.com/whu-zeng/p/14111888.html
[2] FunRec-多任务学习概述: https://datawhalechina.github.io/fun-rec/
[3] 多目标|样本权重:GradNorm和DWA利用学习速度调权: https://zhuanlan.zhihu.com/p/542296680
[4] Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate: https://arxiv.org/abs/1804.07931
[5] Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction: https://arxiv.org/abs/1910.07099
[6] A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation: http://ofey.me/papers/Pareto.pdf
[7] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts: https://dl.acm.org/doi/pdf/10.1145/3219819.3220007
关于作者
徐劲夫,转转算法工程师,主要负责搜索场景排序相关工作。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~