100、Python并发编程:保护临界资源的最简单方式,加锁
引言
前面的文章中已经提到了并发编程中能够带来性能提升的同时,也带来了一些问题,比如对共享资源/临界资源的竞争,可能会导致状态的不一致。最终的结果是虽然性能提升了,但是结果却是错误的……
所以,并发编程中一个更加核心的板块是同步机制。通过同步机制的引入,可以确保临界资源的安全性。
并发编程中,一个最简单的同步机制,就是锁。本文就来简单介绍一下Python中对锁的支持。
本文的主要内容有:
1、为什么要使用锁
2、锁的底层原理
3、Python中的互斥锁
4、Python中的可重入锁
为什么要使用锁
在并发编程中,多个线程可能会同时访问和修改同一个共享资源,也就是临界资源。如果没有对共享资源进行保护,可能会导致数据不一致、数据竞争以及其他难以调试的并发错误。
例如,当多个线程同时读取和修改一个全局变量时,可能会出现不可预知的结果,破坏数据的完整性。
以实际代码为例:
from threading import Thread
import timelines = 0def code(name, n):global linesprint(f'{name}开始写代码')for i in range(n):lines += 1print(f'{name}代码编写完成')if __name__ == '__main__':frontend_coder = Thread(target=code, args=('前端', 1000000))backend_coder = Thread(target=code, args=('后端', 1000000))start_time = time.time()frontend_coder.start()backend_coder.start()frontend_coder.join()backend_coder.join()print(f'总共写了{lines}行代码, 共计耗时{time.time() - start_time}秒')
使用Python3.11执行的结果:

使用Python3.13移除了GIL的解释器执行的结果:

通过对比,有以下内容需要说明:
1、Python中由于GIL的存在,在一定程度上能够保证线程的安全。但是,GIL只是保证的同一个时刻只有一个线程执行字节码指令,并没有承诺线程安全,所以,在涉及到字节码指令行数的设定、IO操作等,还是会导致线程安全性的问题,也就是GIL并不能保证线程安全。
2、Python3.13中,我们使用了移除了GIL的实验特性,很容易就触发了线程安全性的问题,本来应该对全局变量累加到2000000的,结果却是一个错误的数字。
3、需要特别说明的是,在使用了移除GIL的实验特性中,程序执行的性能反而有所下降。因为,该演示代码计算量比较小,反而线程上下文频繁切换的开销,占据了大量的CPU时间。
从上面代码的演示中,可以看到,应该尽量少用全局变量在多线程中进行共享。如果确实需要,应该考虑使用相关同步机制来保证线程安全性。
锁的底层原理
锁是一种同步机制,通常在操作系统的内核层面实现,通常使用原子操作来确保锁的获取和释放。这点应该很好理解,使用锁本身就是要保证临界区执行的原子性、隔离性。如果锁本身不能保证原子性,则锁本身也是存在线程安全问题的,又怎么能够解决线程安全的问题呢。
当一个线程尝试获取一个锁时,如果锁是可用的,线程将成功获得它并进入临界区。如果锁不可用,则线程将被阻塞,直至锁被释放。
所以,从本质上来说,所有的同步机制,都是将对临界区的执行从并行化转变化串行化,从而保证线程安全。所以,临界区应当尽量小,否则,并发编程不仅没有实现并行提效,反而变成了完全串行执行。
锁的底层实现中,一般会涉及到如下几个关键概念,需要说明的是这几个概念与编程语言无关,更多的是操作系统内核层面的设计:
1、原子操作:要确保锁的操作是不可中断的。
2、上下文切换:当线程被阻塞时,通常应当切换执行其他线程。
3、自旋锁:由于上下文切换存在相应的性能开销,有些场景中,需要实现短期低开销的锁,这种锁不会导致上下文切换,而是通过持续检查锁直至锁可用,适合临界区非常短的场景。
在Python多线程编程中,对于锁的支持,主要涉及到两种锁:互斥锁和可重入锁,接下来分别来看下这两种锁的使用。
Python中的互斥锁
互斥锁,是一种最简单的锁,在threading模块中,直接使用Lock即可完成互斥锁的创建。
以下是互斥锁的简单说明:

可以看到,关于互斥锁主要有3个常用的方法:
1、acquire()方法:用于申请获取锁,如果锁已经被别的线程获取并没有被释放的话,则当前现成阻塞。
2、release()方法:用于释放该锁对象。
3、locked()方法:用于测试锁对象当前的状态。
下面通过代码验证下互斥锁的使用。
from threading import Thread, Lock
import timelines = 0lock = Lock()def code(name, n):global linesglobal lockprint(f'{name}开始写代码')for i in range(n):lock.acquire()lines += 1lock.release()print(f'{name}代码编写完成')if __name__ == '__main__':frontend_coder = Thread(target=code, args=('前端', 1000000))backend_coder = Thread(target=code, args=('后端', 1000000))start_time = time.time()frontend_coder.start()backend_coder.start()frontend_coder.join()backend_coder.join()print(f'总共写了{lines}行代码, 共计耗时{time.time() - start_time}秒')
通过Python3.13t执行的结果:
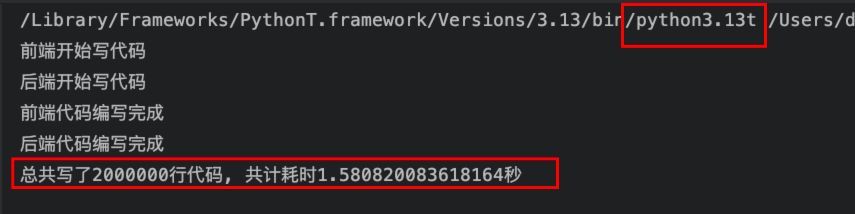
可以看到,加上锁之后,执行的更加慢了……
需要说明的是,互斥锁同一个线程中,只能申请一次,释放之后才能再次申请,否则就会导致死锁。所以,在某些场景中,互斥锁就不能满足需求了,这时就需要可重入锁了。
Python中的可重入锁
针对一些复杂场景,同一个现成需要多次获取锁,这时候,互斥锁的多次申请会导致死锁,所以,引出了可重入锁——RLock。
可重入锁的可能会在以下场景中被用到:
1、递归函数
递归函数中,函数体可能会多次进入同一个临界区,使用互斥锁会导致死锁,而使用可重入锁可以避免这种情况。
2、多个方法需要共用锁
在复杂的类设计中,多个方法可能需要同一个锁,如果这些方法在同一个线程中互相调用,使用互斥锁也会导致死锁。
3、拦截器或者装饰器模式
在某些设计模式中,比如拦截器或者装饰器模式中,方法调用可能会导致同一个线程多次请求同一个锁。可重入锁可以使得这些模式在多线程环境中依然能够平稳运行。
总的来说,可重入锁的优势在于当同一个线程多次进入同一临界区时不会导致死锁,非常适合复杂的用户场景,了解这些适用场景,有助于更好地选择适合的锁类型,从而确保逻辑正确和线程安全。
以下是Python中对可重入锁的支持:

可重入锁内部维持了一个owner属性和count属性,用于保存当前锁的所属线程,以及重入次数。关于可重入锁的实现,可以通过以下几点简化的描述来有个整体上的理解:
1、拥有者线程标识:用于记录当前持有该锁的线程,只有持有该锁的线程才能递归地再次获取该锁。
2、计数器管理:记录当前线程获取该锁的次数,每获取一次,计数器+1,每释放一次,计数器-1。计数器归零之后,锁才被真正释放,从而允许其他线程获取。
3、底层基础锁Lock:使用一个基本的互斥锁来实现实际的锁定和解锁操作,控制锁资源的管理。
简单来说,RLock = Lock + Owner + Counter。
下面,通过代码示例来演示RLock的使用:
from threading import Thread, RLock
import randomclass Project:def __init__(self):self.lock = RLock()self.lines = 0def code(self):for i in range(5):with self.lock:print('普通模式,一行一行写代码')self.lines += 1if random.randint(0, 10) % 3 == 0:print('进入心流模式,生产力提升')self.flow()def flow(self):with self.lock:self.lines += 100if __name__ == '__main__':proj = Project()coders = []for _ in range(3):coder = Thread(target=proj.code)coders.append(coder)coder.start()for coder in coders:coder.join()print(f'总共写了{proj.lines}行代码')
执行结果:

下面对Lock和RLock的使用做一个简单的总结:
1、Lock、RLock的使用,需要注意acquire()和release()方法,要注意成对的调用,否则会导致死锁。
2、由于锁对象实现了__enter__()方法和__exit__()方法,所以,可以通过with语法块进行上下文的管理,从而简化锁对象的申请和释放。
3、通常场景中,可以使用简单的互斥锁来满足常规的需求。如果涉及到复杂的场景,可能在同一个线程中多次申请同一个锁,则需要使用可重入锁。
3、可重入锁是基于普通的互斥锁来实现的,通过维持一个互斥锁对象来保证基本的锁资源管理,通过维持一个owner属性来管理锁的持有者线程标识,通过维持一个counter计数器属性来标识当前持有者进程重入的次数。
总结
本文简单介绍了使用锁的必要性、锁的底层实现原理,以及Python中关于互斥锁、可重入锁的支持,并通过具体的代码示例,演示了两种的锁的基本使用。
以上就是本文的全部内容,感谢您的拨冗阅读。
