手把手教程:使用 Fluentbit 采集夜莺日志写入 ElasticSearch
Fluentbit 是非常流行的日志采集器,作为 Fluentd 的子项目,是 CNCF 主推的项目,本文以夜莺的日志举例,使用 Fluentbit 采集,并直接写入 ElasticSearch,最终使用 Kibana 查看。借此实践过程,让读者熟悉 Fluentbit 的使用。
测试环境介绍
- Macbook M1 芯片
- ElasticSearch、Kibana 7.15.0,使用 Docker compose 启动
- Nightingale 7.5.0,使用 Docker compose 启动
- Fluentbit 3.1.9,使用 Homebrew 安装
如果你使用 X86 的 Linux,整个过程会更简单,而我这里使用的是 Macbook M1 芯片,有些镜像就不太好搞。下面,我们开始准备环境。
准备 ElasticSearch 和 Kibana
下面是我使用的 docker-compose.yml 文件:
networks:elk:driver: bridgeservices:elasticsearch:networks:- elkimage: docker.elastic.co/elasticsearch/elasticsearch:7.15.0container_name: elk-esrestart: alwaysenvironment:# 开启内存锁定- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"# 指定单节点启动- discovery.type=single-nodeulimits:# 取消内存相关限制 用于开启内存锁定memlock:soft: -1hard: -1volumes:- ./data:/usr/share/elasticsearch/data- ./logs:/usr/share/elasticsearch/logs- ./plugins:/usr/share/elasticsearch/plugins- ./config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.ymlports:- 9200:9200kibana:networks:- elkimage: docker.elastic.co/kibana/kibana:7.15.0container_name: elk-kibanavolumes:- ./config/kibana.yml:/usr/share/kibana/config/kibana.ymlrestart: alwaysenvironment:ELASTICSEARCH_HOSTS: http://elk-es:9200I18N_LOCALE: zh-CNports:- 5601:5601
这个 Docker compose 文件是从网上随便找的,唯一做了一个修改是把 elasticsearch.yml 和 kibana.yml 挂载到了本地,方便修改配置。
elasticsearch.yml 内容如下:
cluster.name: "docker-cluster"
network.host: 0.0.0.0
xpack.security.enabled: true
kibana.yml 内容如下:
server.host: "0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
elasticsearch.username: "kibana_system"
elasticsearch.password: "MhxzKhl"
这里设置了一个用户名和密码,怎么配置这些密码呢?进入 elasticsearch 容器,执行如下命令:
bin/elasticsearch-setup-passwords interactive
然后,根据提示设置密码即可。
之后,通过 elastic 账号登录 Kibana 做个测试,比如进入 DevTools,看一下索引信息:
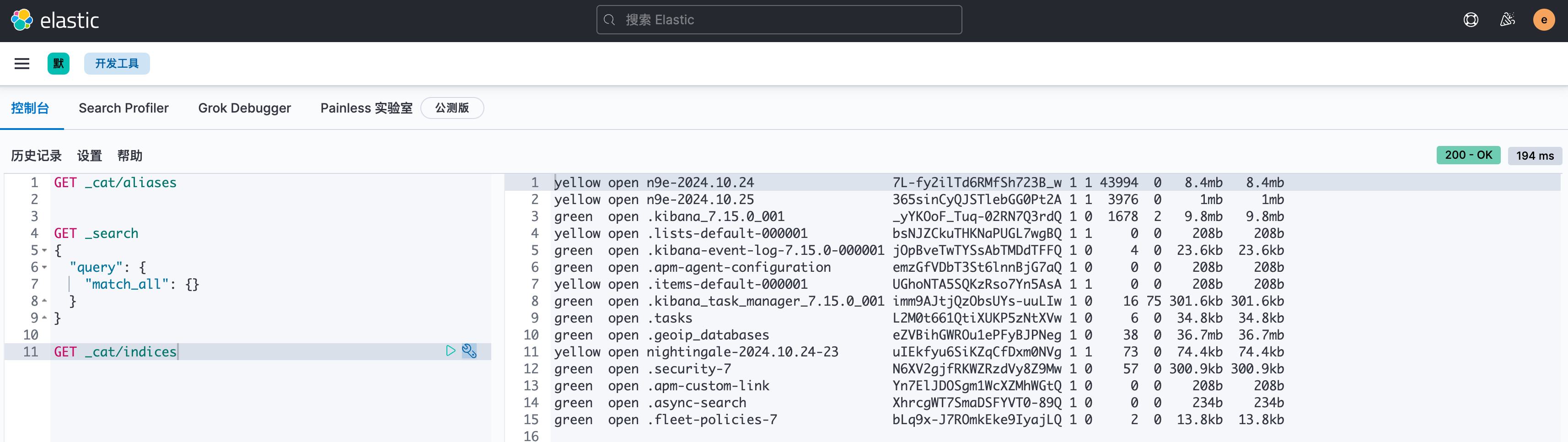
说明都是正常的。
准备 Nightingale
从 Nightingale 的 github releases 页面下载 7.5.0 版本的 release 包,解压后,进入 docker/compose-bridge 目录。
本来呢,直接使用 docker-compose up -d 就启动了,夜莺的日志会默认打到 stdout,但是这次为了测试演示 Fluentbit,这里我会调整一下配置,让夜莺的日志打到具体的文件中。然后通过 volume 挂载到宿主上。
- 在
docker/compose-bridge目录下创建一个 n9e-logs 目录 - 修改 docker-compose.yaml,调整 nightingale 这个 service,增加 volume 挂载:
nightingale:image: flashcatcloud/nightingale:latestcontainer_name: nightingalehostname: nightingalerestart: alwaysenvironment:GIN_MODE: releaseTZ: Asia/ShanghaiWAIT_HOSTS: mysql:3306, redis:6379volumes:- ./etc-nightingale:/app/etc- ./n9e-logs:/app/logsnetworks:- nightingaleports:- "17000:17000"- "20090:20090"depends_on:- mysql- redis- victoriametricscommand: >sh -c "/app/n9e"
volumes 下面本来只是挂载了一个配置文件目录,现在增加了一个 n9e-logs 目录。
- 修改
etc-nightingale/config.toml配置文件,调整 Log 部分如下所示:
[Log]
# log write dir
Dir = "/app/logs"
# log level: DEBUG INFO WARNING ERROR
Level = "DEBUG"
# stdout, stderr, file
Output = "file"
# # rotate by time
KeepHours = 4
# # rotate by size
# RotateNum = 3
# # unit: MB
# RotateSize = 256
Output 从 stdout 改为 file,这样日志就会写到文件中。写到哪个目录呢?由 Dir 指定。日志文件会按小时切割,最多保留 KeepHours 个小时的日志。
- 启动 Nightingale:
cd docker/compose-bridge
docker-compose up -d
这样,Nightingale 就启动了,日志会写到 n9e-logs 目录中。我的环境如下:
ulric@ulric-flashcat n9e-logs % ll
total 29088
drwxr-xr-x 32 ulric staff 1024 10 25 09:00 .
drwxr-xr-x 9 ulric staff 288 10 25 09:23 ..
-rw-r--r-- 1 ulric staff 0 10 25 09:00 ALL.log
-rw-r--r-- 1 ulric staff 0 10 25 05:00 ALL.log.2024102505
-rw-r--r-- 1 ulric staff 0 10 25 06:00 ALL.log.2024102506
-rw-r--r-- 1 ulric staff 0 10 25 07:00 ALL.log.2024102507
-rw-r--r-- 1 ulric staff 0 10 25 08:00 ALL.log.2024102508
-rw-r--r-- 1 ulric staff 1325106 10 25 09:26 DEBUG.log
-rw-r--r-- 1 ulric staff 3054850 10 25 06:00 DEBUG.log.2024102505
-rw-r--r-- 1 ulric staff 3037797 10 25 07:00 DEBUG.log.2024102506
-rw-r--r-- 1 ulric staff 3038315 10 25 08:00 DEBUG.log.2024102507
-rw-r--r-- 1 ulric staff 3037741 10 25 09:00 DEBUG.log.2024102508
-rw-r--r-- 1 ulric staff 0 10 25 09:00 ERROR.log
-rw-r--r-- 1 ulric staff 0 10 25 05:00 ERROR.log.2024102505
-rw-r--r-- 1 ulric staff 0 10 25 06:00 ERROR.log.2024102506
-rw-r--r-- 1 ulric staff 0 10 25 07:00 ERROR.log.2024102507
-rw-r--r-- 1 ulric staff 0 10 25 08:00 ERROR.log.2024102508
-rw-r--r-- 1 ulric staff 0 10 25 09:00 FATAL.log
-rw-r--r-- 1 ulric staff 0 10 25 05:00 FATAL.log.2024102505
-rw-r--r-- 1 ulric staff 0 10 25 06:00 FATAL.log.2024102506
-rw-r--r-- 1 ulric staff 0 10 25 07:00 FATAL.log.2024102507
-rw-r--r-- 1 ulric staff 0 10 25 08:00 FATAL.log.2024102508
-rw-r--r-- 1 ulric staff 17394 10 25 09:26 INFO.log
-rw-r--r-- 1 ulric staff 44614 10 25 06:00 INFO.log.2024102505
-rw-r--r-- 1 ulric staff 40707 10 25 06:59 INFO.log.2024102506
-rw-r--r-- 1 ulric staff 40815 10 25 07:59 INFO.log.2024102507
-rw-r--r-- 1 ulric staff 41242 10 25 08:59 INFO.log.2024102508
-rw-r--r-- 1 ulric staff 0 10 25 09:00 WARNING.log
-rw-r--r-- 1 ulric staff 0 10 25 05:00 WARNING.log.2024102505
-rw-r--r-- 1 ulric staff 0 10 25 06:00 WARNING.log.2024102506
-rw-r--r-- 1 ulric staff 0 10 25 07:00 WARNING.log.2024102507
-rw-r--r-- 1 ulric staff 0 10 25 08:00 WARNING.log.2024102508
配置 Fluentbit
我是 Macbook 的环境,直接通过 Homebrew 安装 Fluentbit:
brew install fluent-bit
接下来我们准备 Fluentbit 的配置文件,希望达成的效果是:Fluentbit 从 Nightingale 的日志文件中读取日志,做 ETL,然后写入 ElasticSearch。这里我会拆成两个配置文件:
- fluent-bit-n9e.conf Fluentbit 主配置文件
- fluent-bit-n9e-parser.conf Fluentbit Parser 配置文件
Fluentbit Parser 配置文件
fluent-bit-n9e-parser.conf 内容如下:
[MULTILINE_PARSER]name multiline-regex-n9etype regexflush_timeout 1000## Regex rules for multiline parsing# ---------------------------------## configuration hints:## - first state always has the name: start_state# - every field in the rule must be inside double quotes## rules | state name | regex pattern | next state# ------|---------------|--------------------------------------------rule "start_state" "/\d+-\d+-\d+ \d+\:\d+\:\d+\.\d+(.*)/" "cont"rule "cont" "/^[a-z]+.*$/" "cont"[PARSER]Name regex-n9eFormat regexRegex /^(?<time>[^ ]* [^ ]*) (?<level>[^ ]*) (?<location>[^ ]*) (?<message>.*)/m# 2024-10-24 16:54:24.257468Time_Key timeTime_Format %Y-%m-%d %H:%M:%S.%LTime_Offset +0800
这里配置了一个普通 PARSER,一个 MULTILINE_PARSER。用于解析 Nightingale 的日志。为了让大家有个直观的感受,我们贴几行 Nightingale 的日志:
ulric@ulric-flashcat n9e-logs % tail -n 1 INFO.log; tail -n 1 DEBUG.log
2024-10-25 09:33:43.194922 INFO memsto/target_cache.go:182 timer: sync targets done, cost: 2ms, number: 2
2024-10-25 09:33:40.905035 DEBUG process/process.go:464 rule_eval:alert-1-28 event:&{Id:0 Cate:prometheus Cluster:vm01 DatasourceId:1 GroupId:3 GroupName:云平台-DevOps Hash:bbbfba0fecf94cd8a517998234b97535 RuleId:28 RuleName:test RuleNote: RuleProd:metric RuleAlgo: Severity:2 PromForDuration:0 PromQl:diskio_io_time != -1 RuleConfig:{"queries":[{"keys":{"labelKey":"","metricKey":"","valueKey":""},"prom_ql":"diskio_io_time != -1","severity":2}]} RuleConfigJson:map[queries:[map[keys:map[labelKey: metricKey: valueKey:] prom_ql:diskio_io_time != -1 severity:2]]] PromEvalInterval:10 Callbacks: CallbacksJSON:[] RunbookUrl: NotifyRecovered:1 NotifyChannels:dingtalk email NotifyChannelsJSON:[dingtalk email] NotifyGroups:1 NotifyGroupsJSON:[1] NotifyGroupsObj:[] TargetIdent:categraf01 TargetNote: TriggerTime:1729820020 TriggerValue:0 TriggerValues: Tags:__name__=diskio_io_time,,ident=categraf01,,name=zram0,,rulename=test,,source=categraf TagsJSON:[__name__=diskio_io_time ident=categraf01 name=zram0 rulename=test source=categraf] TagsMap:map[__name__:diskio_io_time ident:categraf01 name:zram0 rulename:test source:categraf] OriginalTags: OriginalTagsJSON:[] Annotations:{} AnnotationsJSON:map[] IsRecovered:false NotifyUsersObj:[] LastEvalTime:1729820020 LastSentTime:0 NotifyCurNumber:0 FirstTriggerTime:0 ExtraConfig:<nil> Status:0 Claimant: SubRuleId:0 ExtraInfo:[] Target:0x400441c140 RecoverConfig:{JudgeType:0 RecoverExp:}} fire
上面是读取了一行 DEBUG 日志,一行 INFO 日志。可以看出来,夜莺的日志第一个字段是时间,第二个字段是日志级别,第三个字段是位置(打印日志的文件和行号),第四个字段是日志内容。
我们要使用正则表达式来解析这个日志,使之从一行原始文本变成一个结构化的 JSON 对象,后面才方便检索分析。按理说,只需要如下这么一行正则就可以了:
^(?<time>[^ ]* [^ ]*) (?<level>[^ ]*) (?<location>[^ ]*) (?<message>.*)
但是,夜莺的告警引擎在做查询的时候,可能会打印多行日志,所以不得已,我们还需要一个 MULTILINE_PARSER,用于处理多行日志,即上面的 MULTILINE_PARSER 部分的配置。MULTILINE_PARSER 关键是配置首行正则和次行正则,并且给这两个正则分别取个名字,一般首行正则取名为 start_state,次行正则取名为 cont。
整个逻辑就变成了,Fluentbit 逐行读取日志内容,先使用 MULTILINE_PARSER 做多行匹配,这个 MULTILINE_PARSER 仅仅是把原本放到多行的日志内容拼接成一行,然后再使用 PARSER 做结构化解析,从中提取出时间、日志级别、位置、日志内容等字段。其中 PARSER 的正则后面加了一个 /m,表示启用多行模式。
由于日志中没有体现时区信息,所以我们在 PARSER 配置中指定了时区为东八区:Time_Offset +0800。
Fluentbit 主配置文件
fluent-bit-n9e.conf 内容如下:
[SERVICE]flush 1log_level infoparsers_file /Users/ulric/works/tmp/fluent-bit-n9e-parser.conf[INPUT]Name tailTag log.n9ePath /Users/ulric/works/n9e.tarball/n9e-v7.4.0-linux-arm64/docker/compose-bridge/n9e-logs/*.logRead_from_head trueDB /Users/ulric/works/tmp/tail_n9e.dbmultiline.parser multiline-regex-n9e[FILTER]name parsermatch log.n9ekey_name logparser regex-n9e[OUTPUT]Name esMatch log.n9eHost 127.0.0.1Port 9200Index n9e-%Y.%m.%d# Logstash_Format On# Logstash_Prefix nightingale# Logstash_DateFormat %Y.%m.%d-%HHTTP_User elasticHTTP_Passwd MhxzKhl[OUTPUT]Name stdoutMatch log.n9e
首先走 INPUT,INPUT 先采用 multiline-regex-n9e 做多行匹配,然后再走 FILTER,通过 regex-n9e 做结构化解析,最后走 OUTPUT,将解析后的日志写入 ElasticSearch。
multiline-regex-n9e 和 regex-n9e 是我们在 fluent-bit-n9e-parser.conf 中定义的两个 parser。
那个 stdout 的 OUTPUT 不用关注,是我做测试用的。
启动 Fluentbit
fluent-bit -c fluent-bit-n9e.conf
因为有两个 OUTPUT,一个是写往 ElasticSearch,一个是写往 stdout,所以一旦启动 Fluentbit,你会看到日志不断地打印到 stdout,同时,你可以在 Kibana 中看到索引 n9e-2024.10.25 已经创建,里面有我们解析后的日志。去 Kibana 创建一个 n9e* 的索引模式,然后在 Discover 中查看日志。
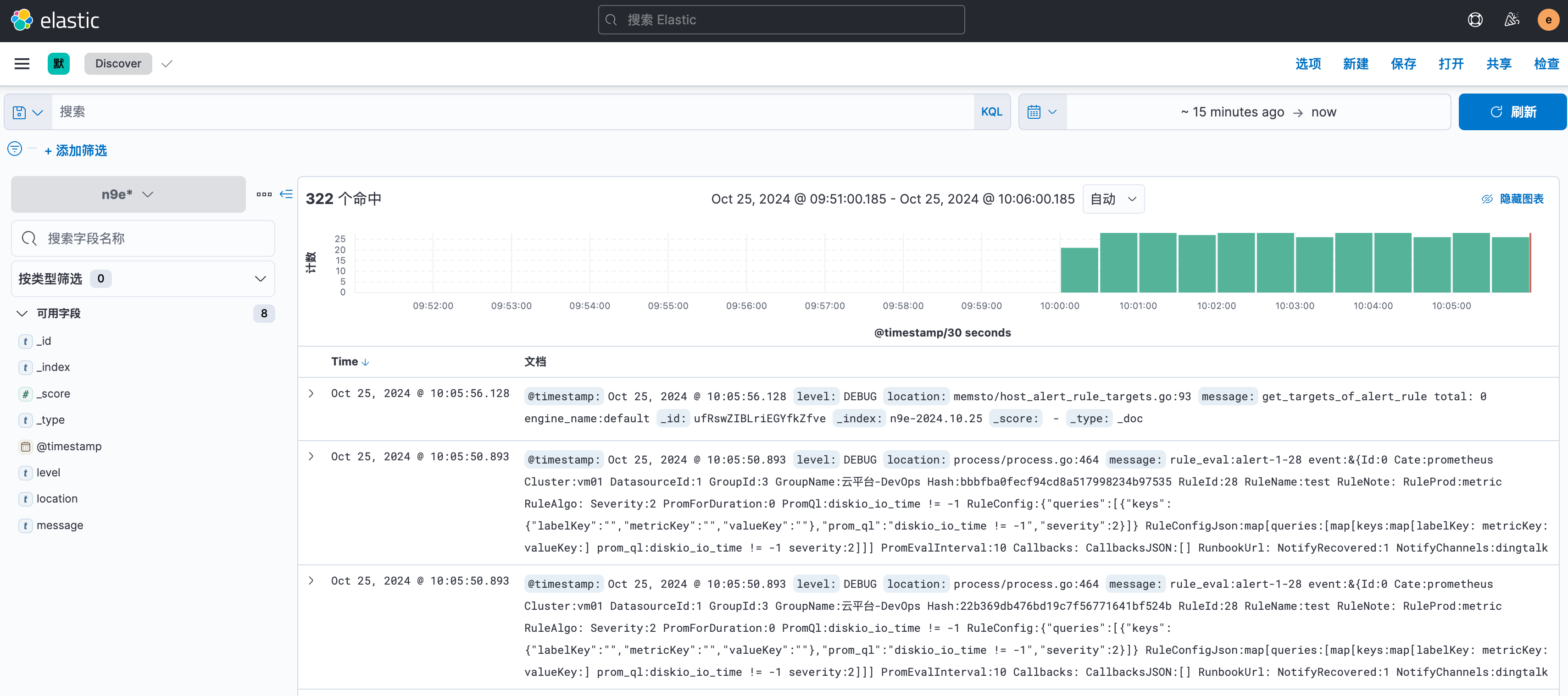
一切正常!
总结
本文介绍了如何使用 Fluentbit 采集夜莺的日志,并写入 ElasticSearch,最终通过 Kibana 查看。Fluentbit 是一个非常流行的日志采集器,本文通过实践,让读者熟悉了 Fluentbit 的使用。