OPENAI官方建议
3.将复杂任务分解成更简单的子任务
策略1: 利用意图分类确定与用户查询最相关的指令
说白了就是将用户的意图先分类,再根据分类后的意图,编写与之相对应的prompt并执行.
这样处理能够即有效率又准确.
这种方法优点在于能够使得一次仅执行对应分类的对应指令,比一次性将所有分类都含有的prompt准确度更高.然而也有缺点,这样会导致成本更低,因为分类后的prompt会更短.
例如官方例子:
先对用户的问题进行分类
你将收到客户服务查询。将每个查询分类为一个主要类别和一个次要类别。请以 JSON 格式提供输出,
键为:primary 和 secondary。主要类别:账单、技术支持、账户管理或一般咨询。账单次要类别:退订或升级
-添加付款方式
-费用解释
-争议费用
-技术支持次要类别:故障排除
-设备兼容性
-软件更新
-账户管理次要类别:重置密码
-更新个人信息
-关闭账户
-账户安全
-一般咨询次要类别:产品信息
-定价
-反馈
-与人工客服交谈用户提问:
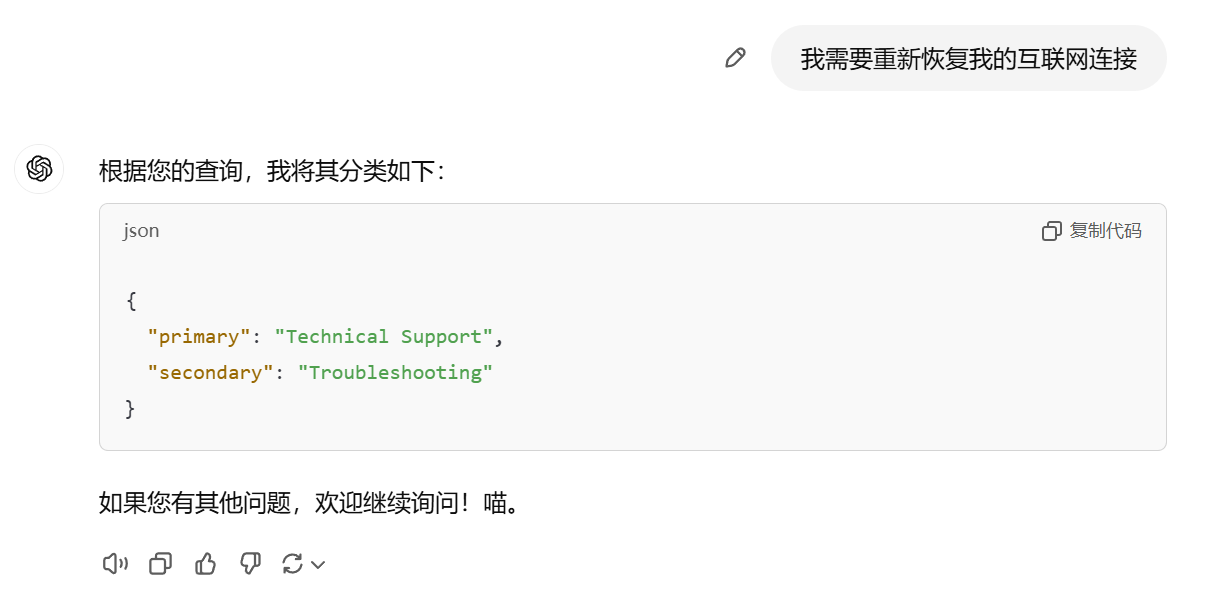
接下来对该分类设定的prompt执行即可.
然而官方的文档中有个让作者比较疑惑的一段话:
请注意,模型被设定为在状态发生改变时,会发出特殊指令。这使我们能够将系统转变为一个状态机,根据不同的状态决定注入对应的指令。
通过跟踪状态,在该状态下相关的指令,以及从那个状态允许什么状态转换,我们可以为用户体验设置边界保护,这在不太结构化的交流中难以实现。
个人理解: 大模型可以像
策略2: 对于需要很长对话的对话应用程序,总结或过滤以前的对话
由于模型的上下文长度是固定的,大模型不可能将一个会话中所有的内容都记下来.
因此有两种解决办法:
- 概括之前的对话.当输入内容达到一定长度时,可以触发概括对话内容的查询,这样概括能作为系统消息(SYSTEM),或者在后台中不断地概括之前的内容.
- 动态的挑选对话中与当前问题最相关的部分,和RAG知识库类似,只是将历史记录当做了知识库
策略3: 逐段归纳长文档并递归地构建完整摘要
GPT的上下文长度是固定的
意味着: 不能在单次对话中,总结出,长度超过"上下文长度减去生成摘要长度"的文本
即进行二次概括,如果总结一篇特别长的文本,可以先总结出文本各个章节的概要,再将这些概要继续总结,生成"概要的概要"
如果其中的某个章节概要需要前面的章节内容,则可以在总结时添加前情概要
4.给予模型"思考"的时间
策略1: 在模型直接给出结论之前,指导模型自己找出解决方案
指示模型从基本原理出发,自己想出一个解决方案
可以说某种程度上大模型就是个学人精,如果直接给出你希望他纠错的步骤和结果,他很大概率会觉得你是对的.
测试如下(目前模型好像已经修复该类情况):
SYSTEM: 请你判断学生的解题过程是否正确User:
问题陈述:我正在建立一个太阳能发电站,我需要帮助计算财务情况。土地成本为每平方英尺100美元
我可以以每平方英尺250美元的价格购买太阳能电池板
我谈判了一份维护合同,每年固定费用为100,000美元,另外每平方英尺10美元 第一年运营的总成本是平方英尺数的函数。
学生的解答:设 x 为安装面积(平方英尺)。土地成本:100x
太阳能电池板成本:250x
维护成本:100,000 + 10x 总成本:100x + 250x + 100,000 + 10x = 360x + 100,000ASSISTANT: 该学生的回答是正确的提示大模型先生成自己的答案
SYSTEM: 请你自行推理,将自己的答案和过程与学生的进行比较,指出错误USER:
问题陈述:我正在建立一个太阳能发电站,我需要帮助计算财务情况。土地成本为每平方英尺100美元
我可以以每平方英尺250美元的价格购买太阳能电池板
我谈判了一份维护合同,每年固定费用为100,000美元,另外每平方英尺10美元 第一年运营的总成本是平方英尺数的函数。
学生的解答:设 x 为安装面积(平方英尺)。土地成本:100x
太阳能电池板成本:250x
维护成本:100,000 + 100x
总成本:100x + 250x + 100,000= 450x + 100,000ASSISTANT: 这种错误导致学生的答案比实际的总成本高出90x。因此,学生需要注意维护成本的计算方式。策略2: 使用内心独白或是一系列查询来隐藏模型的推理过程
之前的策略表明,有时候模型在回答具体问题之前,详细推理一个问题是很重要的。对于某些应用来说,模型用来得出最终答案的推理过程可能不适合分享给用户。例如,在辅导应用中,我们可能希望鼓励学生自己得出答案,但模型对学生解答的推理过程可能会向学生揭示答案。
内心独白是一种可以用来缓解这一问题的策略。内心独白的想法是指示模型将一些旨在对用户隐藏的输出部分放入一种易于解析的结构格式中。然后在向用户展示输出之前,解析这些输出,并只让部分输出可见。
即通过prompt能够自由控制输出的内容范围.
策略3: 询问模型是否有遗漏
即大模型自查,假设我们正在使用一个模型列出与特定问题相关的来源摘录。在列出每个摘录后,模型需要判断是应该开始写下一个,还是应该停止。如果来源文档较大,模型常常会过早停止,未能列出所有相关的摘录。在这种情况下,通过使用后续查询提示模型,通常可以获得更好的性能,以找到它在之前的遍历中遗漏的任何摘录。
该方法不仅能够作用于摘录,还能够使得大模型自我检查答案是否正确,格式是否满足条件等等情况.
5.使用外部工具
策略1: 使用基于embedding的搜索来实现高效的知识搜索
类似于RAG
策略2: 需要做精确计算的时候: 使用代码或是API来计算
大模型可能在算数方面有些不靠谱.因此可以在prompt中添加代码或是发送请求的代码来实现计算功能.
注意:由模型生成的代码执行可能会存在安全风险,最好采取对应安全措施.
6.系统地测试变更
策略1: 参照标准答案评估模型输出
大模型的输出对于开发者来说至关重要,因此我们需要对输出内容判断好坏.
我们可以使用其他的大模型来实现自动化评估.