AI GPU系统调试能力与实践
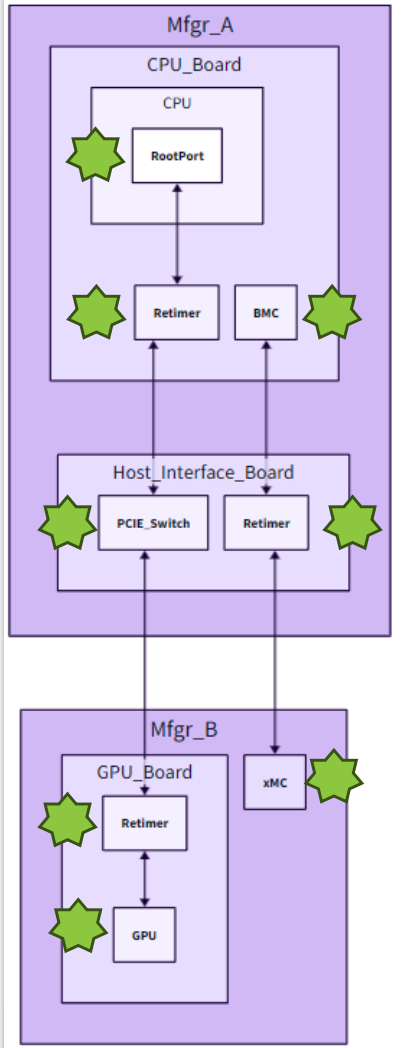
随着人工智能技术的迅猛发展,AI GPU服务器系统作为现代数据中心中最复杂且强大的组件之一,其重要性日益凸显。然而,由于不同制造商(如Mfgr_A和Mfgr_B)之间的组件集成问题不断出现,这给系统的可调试性带来了巨大挑战,影响了整体系统的稳定性。
调试方法论
- 识别可复现与不可复现场景
-
- 加速问题复现:通过使用LTSSM(PCIe链路训练状态机)循环等方法,能够更快地复现问题,从而加速日志收集和调试过程。
- 交换硬件/固件:通过互换不同节点上的硬件或固件,以确定问题是否特定于某个硬件或固件版本。
- 预先对齐并收集失败日志
-
- 在问题发生前与组件所有者协调,制定合适的日志收集计划。
- 确定所需日志及其收集方式,确保即使系统运行数小时后仍能捕获有意义的日志。
- 针对系统挂起等情况,开发相应的日志收集策略。
- 日志相关性分析与调整
-
- 对收集到的日志进行相关性分析,必要时进行调整,并尝试复现问题直至验证假设。
调试案例研究
案例1:PCIe Switch与Retimer间歇性PCIe开关下游SLD/降级—启动时间
- 问题复现:在特定的PCIe流程中复现问题,该流程会重置或配置某些PCIe设备。此外,使用开关特殊地址访问工具也可复现问题。
- 日志收集:利用PCIe开关调试dongle收集开关日志,发现开关固件卡住;使用带外通道收集重定时器日志,未见PCIe错误。
- 日志分析与调整:验证调试固件后发现,固件获取更多寄存器数据,同时阻止了某些地址访问。
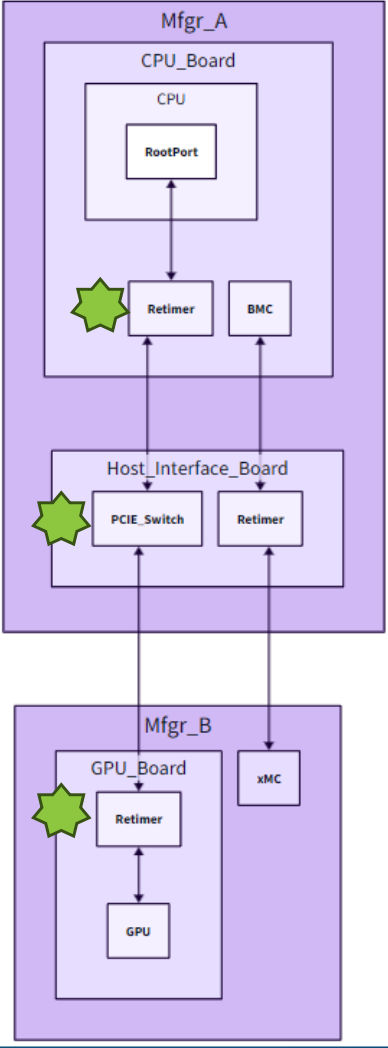
案例2:PCIe Switch Root Port CTO—运行时间
- 问题复现:问题在多个节点上容易复现。
- 日志收集:使用xMC控制台收集UBB启动日志,信号接收和设置正确;使用BMC控制台收集BMC日志,信号接收正确但发送过早或错误。
- 日志分析与调整:验证调试固件后确认,UBB电源开启序列发生变化,BMC电源按钮按下逻辑也有所改变。
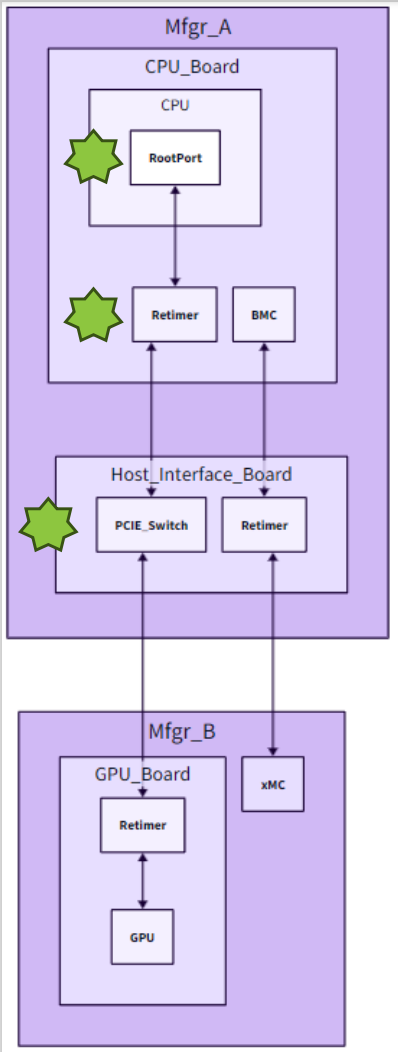
案例3:BMC/UBB间歇性GPU缺失——启动时间
- 硬件调试器的可访问性和速度:硬件调试器必须易于访问,日志收集应迅速,避免长时间延迟。
- 客户/合作伙伴的调试日志收集:允许客户和合作伙伴直接下载二进制日志,而不限制此功能仅为组件所有者。
- PCIe分析仪连接性:确保能够连接PCIe分析仪对于全面分析和监控PCIe相关问题至关重要。
- 远程调试的安全例外简化流程:实施简化的安全例外流程以支持高效的远程调试,而非禁止远程调试或每次会话都需要特殊解锁的固件。
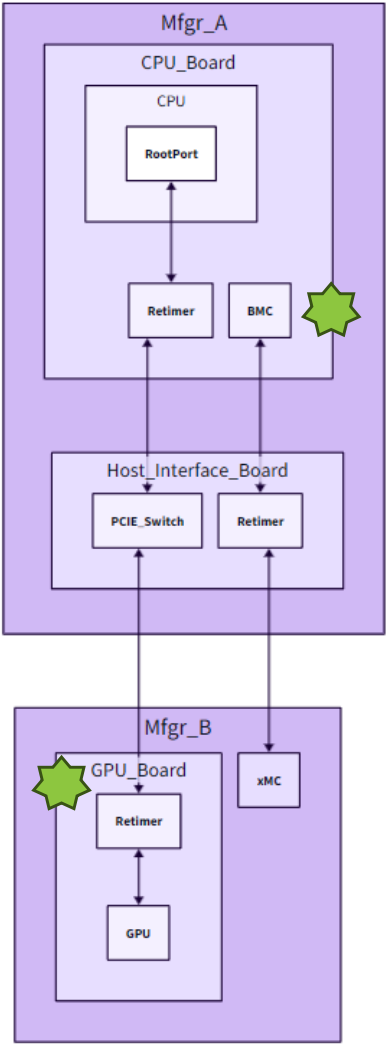
设计具有更好可调试性的AI GPU系统是一个复杂的过程,需要多方面的努力。从识别问题场景到收集和分析日志,再到最终解决问题,每一步都至关重要。通过上述案例的研究,我们不仅可以看到调试实践中面临的挑战,也能学到有效的解决策略。为了提高系统的稳定性和性能,我们需要持续关注并优化调试流程,同时也鼓励更多人参与到项目社区中来,共同推动AI GPU系统的发展。