Android 字节飞书面经
Android 字节飞书面经
文章目录
- Android 字节飞书面经
- 一面
- 二面
一面
1. 线程是进程的一部分,一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
2. 根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
3. 在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
4. 所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
5. 内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
6. 操作系统管理了系统的有限资源,当有多个进程(或多个进程发出的请求)要使用这些资源时,因为资源的有限性,必须按照一定的原则选择进程(请求)来占用资源。**这就是调度。**
7. CPU的核和线程执行关系:通常情况下,一个核心对应一个物理线程,但通过超线程技术,一个核心可以对应两个线程,也就是说它可以同时运行两个线程。**在待执行线程数很多时,CPU核心数越高,多线程执行效率也就越高,但当执行线程数低于CPU核心数时,多线程执行效率其实与CPU核心数关系不大,而是更多的取决于线程访问其他资源的速度。**
8. **推荐阅读:**[**深度好文|面试官:进程和线程的所有知识点**](https://zhuanlan.zhihu.com/p/317144739)
扩展:
- 为什么要设计线程?
调度与执行的基本单位是线程,资源所有权(包括程序、数据、文件等资源。一个进程拥有对这些资源的所有权)是进程
线程的设计就是为了提高CPU、内存、I/O 设备的利用率,CPU、内存、I/O 设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异
- 执行与调度的基本单位是线程,这样设计有什么好处?
为了并发和隔离,并发是为了尽量让硬件利用率提高,线程是为了系统层面做到并发,线程上下文切换效率比进程上下文切换会高很多,这样可以提高并发效率。
隔离也是并发之后要解决的重要问题,计算机的资源一般是共享的,隔离要能保障崩溃了这些资源能够被回收,不影响其他代码的使用。所以说一个操作系统只有线程没有进程也是可以的,只是这样的系统会经常崩溃而已,操作系统刚开始发展的时候和这种情形很像。
程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。
- 一个线程有哪些数据段?
- 个人觉得这个问题有点不对,我没有查到相应的答案,我感觉面试官是想问内存的分段
- 内存分段情况:
- **代码段(正文段):**代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
- 数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
- BSS段:BSS段(bsssegment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
- 堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
- 栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
- 死锁的形式有其他的几种吗?(除了多个线程同时挣抢资源)
- 资源死锁:每个进程都在等待其他进程释放资源,而其他资源也在等待每个进程释放资源,这样没有进程抢先释放自己的资源,这种情况会产生死锁,所有进程都会无限的等待下去。
- 通信死锁:两个或多个进程在发送消息时出现的死锁。进程 A 给进程 B 发了一条消息,然后进程 A 阻塞直到进程 B 返回响应。假设请求消息丢失了,那么进程 A 在一直等着回复,进程 B 也会阻塞等待请求消息到来,这时候就产生死锁。通信中一个非常重要的概念来避免:超时(timeout) 如果超时时间到了但是消息还没有返回,就会认为消息已经丢失并重新发送,通过这种方式,可以避免通信死锁。
- 怎么在程序上解决死锁
- 这个问题只需要破解四种死锁形成的条件之一就OK了,互斥,循环等待,保持和等待,非抢占式
- 比如给每个线程设置一个占有资源的时间,时间一到必须释放锁
- 给线程设置优先级,允许高优先级的抢占低优先级的线程
- Java栈和堆区别
- 什么是原子变量,原子变量的代码实现
- 原子变量保证了该变量的所有操作都是原子的,不会因为多线程的同时访问而导致脏数据的读取问题。
- 源码实现:
public class AtomicInteger extends Number implements java.io.Serializable {private static final Unsafe unsafe = Unsafe.getUnsafe();private static final long valueOffset;static {try {//用于获取value字段相对当前对象的“起始地址”的偏移量valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));} catch (Exception ex) { throw new Error(ex); }}private volatile int value;//返回当前值public final int get() {return value;}//递增加detlapublic final int getAndAdd(int delta) {//三个参数,1、当前的实例 2、value实例变量的偏移量 3、当前value要加上的数(value+delta)。return unsafe.getAndAddInt(this, valueOffset, delta);}//递增加1public final int incrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;}
...
}
我们可以看到 AtomicInteger 底层用的是volatile的变量和CAS来进行更改数据的。
- volatile保证线程的可见性,多线程并发时,一个线程修改数据,可以保证其它线程立马看到修改后的值
- CAS 保证数据更新的原子性。
- TCP和UDP的区别吗
- Java四种引用
- 注解是干嘛的?几种常用的注解
- 注解是用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解,主要作用
- 生成文档,通过代码里标识的元数据生成javadoc文档。
- 编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
- 编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
- 运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例。
- Java自带的标准注解,包括@Override、@Deprecated和@SuppressWarnings,分别用于标明重写某个方法、标明某个类或方法过时、标明要忽略的警告,用这些注解标明后编译器就会进行检查。
- 元注解,元注解是用于定义注解的注解,包括@Retention、@Target、@Inherited、@Documented,@Retention用于标明注解被保留的阶段,@Target用于标明注解使用的范围,@Inherited用于标明注解可继承,@Documented用于标明是否生成javadoc文档。
- 推荐阅读:JAVA 注解的基本原理
- 注解是用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解,主要作用
- 线程池有什么用,几种线程池说一下
- 线程池的作用:
- 重用存在的线程池,减少对象的创建,消亡的开销,性能佳
- 可有效控制最大的并发线程数,提高系统资源的使用率,同时避免过多的资源竞争,避免堵塞
- 提供定时执行,定期执行,单线程,并发数控制等功能
- 线程池的优先级:核心线程池>阻塞队列>非核心线程池
- 各任务队列:
- ArrayBlockingQueue:内部维护了一个由固定大小的数组构成的数据缓冲队列,数组大小在队列初始化的时候就需要制定,可以制定访问策略ArrayBlockingQueue(int capacity, boolean fair) fair==true 则按照FIFO的顺序访问阻塞队列,若为false ,则访问顺序是不确定的
- LinkedBlockingQueue:基于单向链表的阻塞队列,内部维护了一个由单向链表构成的数据缓冲队列,区别于ArrayBlockingQueue,LinkedBlockingQueue在初始化的时候可以不设置容量大小,其默认大小为**Ineger.MAX_VALUE **
- PriorityBlockingQueue:基于优先级的阻塞队列,我们可以实现Comparable接口,我们实现Comparable接口,我们重写CompareTo就可以定义优先级顺序。队列容量是无限的,当线程数达到最大值时,会对任务队列扩容。
- DelayQueue:基于延迟时间优先级的阻塞队列,DelayQueue必须实现Delayed接口,(Delayed继承自Comparable接口),我们需重写Delayed.getDelay方法为元素的释放(执行任务)设置延迟(getDelay方法的返回值是队列元素被释放前的保持时间,如果返回0或一个负值,就意味着该元素已经到期需要被释放,因此我们一般用完成时间和当前系统时间作比较)。
- SynchronousQueue:基于同步的阻塞队列,他内部并没有数据缓存空间,元素只是会在试图取走的时候才有可能存在,也就是说,如果没有在插入元素时没有后续没有执行取出的操作,那么插入的行为就会被阻塞。
- 系统预设的线程池:
- CachedTheadPool:
- CachedThreadPool只有非核心线程池,当任务提交后,都会开辟一个非核心线程池来执行。
- 闲置线程超过60s后都会被回收
- 所有提交的任务都会被立即执行,(使用SynchronousQueue)
- CachedTreadPool在执行大量短生命周期异步任务事,可以显著提高程序性能。
- FixedThreadPool:
- 线程数固定,核心线程数==最大线程数,线程闲置时间是0,任务队列是LinkedBlockingQueue
- 核心线程池没有超时限制,任务队列容量没有大小限制
- FixedTreadPool使用于需要快速响应的场景
- SingleTreadExecutor:
- 核心线程池只有一个,最大线程数也是1,线程闲置时间为0,任务队列为LinkedBlockingQueue,任务数量没有大小限制
- 如果单个线程在执行过程中因为某些错误而终止,会创建新的线程代替他执行后续的任务
- CachedTheadPool:
- 推荐阅读:
- 大话Android多线程(五) 线程池ThreadPoolExecutor详解
- 线程池的作用:
- 说说反射
- Android事件分发机制
- 讲一下Android的handler
二面
二面忘记录音了,有些问题只记得一半
- RecycleView的局部刷新机制,我们往RecycleView进行差异化更新应该注意什么?
- 线程死锁后怎么解决,当时我回答的是破坏死锁形成的四个条件,比如设置时间片,但是下一次怎么恢复现场?
- 操作系统的跨进程通信的方式你知道几种实现细节
- ANR的触发原理
- 输入事件超时5s
- 广播类型超时(前台15s,后台60s)
- 服务超时(前台20s,后台200s)
- Activity的生命周期超时不会ANR
- 导致ANR的原因:
- 应用层耗时导致的ANR
- 函数阻塞:如死循环,主线程IO,处理大量数据
- 锁出错:线程对锁的挣抢
- 内存紧张:系统分配给一个应用的内存是用上限的,内存紧张会导致一些应用操作导致耗时
- 系统层ANR
- CPU被抢占
- 内存紧张
- 分析堆栈信息trace文件,查看CPU负载,内存信息,看主线程执行耗时操作,线程被锁争抢
- 应用层耗时导致的ANR
- 卡顿优化方案
- 布局优化
- 减少冗余或者嵌套的布局来降低视图的层级,比如使用约束布局代替线性布局和相对布局
- 使用ViewStub替代在启动过程中不需要显示的UI控件
- 使用自定义View代替复杂的View叠加
- 减少主线程耗时操作
- 主线程不要直接操作数据库,数据库的操作应该放在子线程中进行
- Sharedpreferences尽量使用apply操作,少使用commit
- 网络请求放在子线程,
- 不要在activity的OnResume和OnCreate,View的OnDraw中进行耗时操作,比如大量的计算
- 减少过度绘制
- 列表优化
- RecyclerView使用优化,使用DiffUtil和notifyItemDataSetChanged进行局部更新
- 减少小对象的分配和回收
- 布局优化
- Android四大组件如何实现跨进程通信?跨进程通信过程中如何实现数据共享?除了mmap还有吗?(当时自己想到了socket但是socket不太熟),给自己挖坑了
- **使用Bundle **,由于bundle实现了Parcelable接口,可以在不同进程间传输。
- **使用文件共享,**两个进程通过读一个文件来交换数据,Android是基于Linux,可以并发读写,并发读的话可能导致读出的数据不是最新的,并发写的话会把问题写错。文件共享适用于对数据同步要求不高的进程通信。多进程下不建议使用sharedpreferences,会有很大概率丢失数据,sharedpreferences是在一个个进程会有自己的缓存。
- **使用Messenger,是一种轻量级的IPC方案,底层是AIDL **,服务端需要创建一个Service,创建一个handler,并通过他来创建一个Messenger对象,然后在Service的OnBind的方法返回,客户端需要绑定Service,绑定成功后使用服务端返回的IBinder创建一个Messenger,这样客户端就可以和服务端发送消息了,消息类型是Messenger,如果希望服务端也能发送消息给客户端,在客户端创建一个handler用来处理服务端发送的消息,使用这个handler创建一个Messenger,将Messenger通过replyTo返回给服务器,服务器拿到客户端的Messenger就可以进行通信了。
- **使用AIDL,**服务端创建一个Service用来监听客户端的请求连接,创建一个AIDL文件,将暴露给客户端的接口在这个文件中声明,最后在Service中,声明实现AIDL的接口,客户端绑定服务端的Service,将服务端成功返回的Binder对象转为AIDL接口所属于的类型,接着可以调用AIDL的方法
- **ContentProvider,**可以理解为受约束的AIDL,主要提供数据源的CRUD
- **Socket,**服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了
- 自定义view,一定得重写measure layout draw 方法吗?你觉得那个过程最耗时?关于MeasureSpec你觉得我们可以自己手动去更改值吗?我回答可以,面试官反问:如何可以手动更改值,那岂不是MeasureSpec没什么用了吗?
- 不一定
- 自定义组合控件类型不需要重写这三个方法,只需要初始化UI,添加一些监听,对外暴露一些方法
- 继承系统的控件(textview),我们希望复用系统的onMeaseure 和 onLayout ,所以我们只要重写onDraw
- 继承View,我们得重写**onMeasure 和 onDraw **,在View的源码当中并没有对AT_MOST和EXACTLY两个模式做出区分,也就是说View在wrap_content和match_parent两个模式下是完全相同的,都会是match_parent,显然这与我们平时用的View不同,所以我们要重写onMeasure方法。
- 继承ViewGroup,我们得重写onMeasure和onLayout
- 推荐阅读:Android自定义View全解
- 在子线程中除了handler机制回到主线程更新数据,还有其他吗?
- Handler:
- 子线程(非UI线程)调用handler对象sendMessage(msg)方法,将消息发送给关联Looper,Looper将消息存储在MessageQueue消息队列里面。
- 然后轮巡取出MessageQueue中的消息给UI线程中handler处理,handler得到消息调用handleMessage方法处理消息,从而可以更新Ui。
- Activity.runOnUiThread
- Handler:
# Activity.runOnUiThread
/*** Runs the specified action on the UI thread. If the current thread is the UI* thread, then the action is executed immediately. If the current thread is* not the UI thread, the action is posted to the event queue of the UI thread.** @param action the action to run on the UI thread*/public final void runOnUiThread(Runnable action) {if (Thread.currentThread() != mUiThread) {mHandler.post(action);} else {action.run();}}
* 看源码很明显知道当前线程是主线程的时候,立马会执行run() 方法,当前线程非主线程会把action入队列MessageQueue
- **View.post(Runable r)**
public boolean post(Runnable action) {final AttachInfo attachInfo = mAttachInfo;if (attachInfo != null) {return attachInfo.mHandler.post(action);}// Postpone the runnable until we know on which thread it needs to run.// Assume that the runnable will be successfully placed after attach.getRunQueue().post(action);return true;
}
先看第一种情况,AttachInfo !=null
* <font style="color:#52C41A;">attachInfo.mHandler.post(action); </font>由此便知Runablle是交给attachInfo的handler去处理了* 我们得知道**attchInfo是什么**,AttchInfo是View的内部类,其内部持有一个 Handler 对象,从注释可知它是由 ViewRootImpl 提供的
final static class AttachInfo {/*** A Handler supplied by a view's {@link android.view.ViewRootImpl}. This* handler can be used to pump events in the UI events queue.*/@UnsupportedAppUsagefinal Handler mHandler;AttachInfo(IWindowSession session, IWindow window, Display display,ViewRootImpl viewRootImpl, Handler handler, Callbacks effectPlayer,Context context) {···mHandler = handler;···}···
}
* 看看**attchInfo**初始化时机:
# ViewRootImpl
final ViewRootHandler mHandler = new ViewRootHandler();public ViewRootImpl(Context context, Display display, IWindowSession session,boolean useSfChoreographer) {···mAttachInfo = new View.AttachInfo(mWindowSession, mWindow, display, this, mHandler, this,context);···}private void performTraversals() {···if (mFirst) {···host.dispatchAttachedToWindow(mAttachInfo, 0);···}···performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);performLayout(lp, mWidth, mHeight);performDraw();···}
可以跟踪到 ViewRootImpl 类。ViewRootImpl 内就包含一个 Handler 对象 mHandler,并在构造函数中以 mHandler 作为构造参数之一来初始化 mAttachInfo。ViewRootImpl 的performTraversals()方法就会调用 DecorView 的 dispatchAttachedToWindow 方法并传入 mAttachInfo,从而层层调用整个视图树中所有 View 的 dispatchAttachedToWindow 方法,使得所有 childView 都能获取到 mAttachInfo 对象
* **继续看dispatchAttachedToWindow(mAttachInfo, 0)方法**
@UnsupportedAppUsage(maxTargetSdk = Build.VERSION_CODES.P)void dispatchAttachedToWindow(AttachInfo info, int visibility) {mAttachInfo = info;···}
mAttachInfo 的赋值时机可以追踪到 View 的 dispatchAttachedToWindow 方法,至此,我们可以很清楚知道mAttachInfo的初始化流程
:::success
- ViewRootImpl的构造方法里面开始初始化 mAttachInfo = new View.AttachInfo(mWindowSession, mWindow, display, this, mHandler, this,context);这里传了mhandler,说mAttachInfol的引用是指向ViewRoot Impl的handler的。
- #ViewRootImpl.performTraversals()会调用#View. dispatchAttachedToWindow(mAttachInfo, 0);再看#View. dispatchAttachedToWindow方法,我们才发现真正的View.mAttachInfo赋值是在这里。
- 此外,performTraversals()方法也负责启动整个视图树的 Measure、Layout、Draw 流程,只有当 performLayout 被调用后 View 才能确定自己的宽高信息。而 performTraversals()本身也是交由 ViewRootHandler 来调用的,即整个视图树的绘制任务也是先插入到 MessageQueue 中,后续再由主线程取出任务进行执行。由于插入到 MessageQueue 中的消息是交由主线程来顺序执行的,所以 attachInfo.mHandler.post(action)就保证了 action 一定是在 performTraversals 执行完毕后才会被调用,因此我们就可以在 Runnable 中获取到 View 的真实宽高了
:::
* 看第二种情况:<font style="color:#F5222D;">getRunQueue().post(action);</font>* <font style="color:#F5222D;">getRunQueue() </font><font style="color:#000000;">方法返回的是</font><font style="color:rgba(46, 36, 36, 0.87);">HandlerActionQueue 我们先看一下代码</font>
public class HandlerActionQueue {private HandlerAction[] mActions;private int mCount;public void post(Runnable action) {postDelayed(action, 0);}public void postDelayed(Runnable action, long delayMillis) {final HandlerAction handlerAction = new HandlerAction(action, delayMillis);synchronized (this) {if (mActions == null) {mActions = new HandlerAction[4];}mActions = GrowingArrayUtils.append(mActions, mCount, handlerAction);mCount++;}}public void executeActions(Handler handler) {synchronized (this) {final HandlerAction[] actions = mActions;for (int i = 0, count = mCount; i < count; i++) {final HandlerAction handlerAction = actions[i];handler.postDelayed(handlerAction.action, handlerAction.delay);}mActions = null;mCount = 0;}}private static class HandlerAction {final Runnable action;final long delay;public HandlerAction(Runnable action, long delay) {this.action = action;this.delay = delay;}public boolean matches(Runnable otherAction) {return otherAction == null && action == null|| action != null && action.equals(otherAction);}}···}
很明显可以知道,HandlerActionQueue 可以看做是一个专门用于存储 Runnable 的任务队列,mActions 就存储了所有要执行的 Runnable 和相应的延时时间。两个post方法就用于将要执行的 Runnable 对象保存到 mActions中,executeActions就负责将mActions中的所有任务提交给 Handler 执行
* <font style="color:#000000;">现在看一下</font><font style="color:#F5222D;">executeActions </font><font style="color:#000000;">被谁调用</font>
#view@UnsupportedAppUsage(maxTargetSdk = Build.VERSION_CODES.P)void dispatchAttachedToWindow(AttachInfo info, int visibility) {mAttachInfo = info;···// Transfer all pending runnables.if (mRunQueue != null) {mRunQueue.executeActions(info.mHandler);mRunQueue = null;}···}
现在我们知道了,这个操做也是#View.dispatchAttachedToWindow ,从而使得 mActions 中的所有任务都会被插入到 mHandler 的 MessageQueue 中** 等到主线程执行完 performTraversals() 方法后就会来执行 mActions,所以此时我们依然可以获取到 View 的真实宽高**
* **推荐阅读:**[**一文读懂 View.Post 的原理及缺陷**](https://juejin.cn/post/6939763855216082974#heading-3)
- **AsyncTask*** 内部就是一个Handler和线程池的封装。在线程池中执行后台任务,并在执行过程中将执行进度传递给主线程,当任务执行完毕后,将最终结果传递给主线程。
- **<font style="color:rgb(51, 51, 51);">Rxjava</font>**
:::success
通过操作符切换线程
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
:::
- Android 什么时候会用到子线程?我当时回答的是可以考虑将耗时操作放在子线程的场景都可以,比如:网络请求,数据库的读写,热启动将耗时操作放在子线程进行,磁盘IO
- ApplicationContext和ActivityContext有什么区别?ApplicationContext启动Activity有什么要注意的?我当时回答:必须要加FLAG_ACTIVITY_NEW_TASK标志位,面试官反问:你觉得还有什么要注意的吗?
- Context是上下文环境,是应用程序环境信息的接口,使用Context的调用方法,比如启动Activity,访问资源,调用系统服务,传入Context,比如弹出Toast,创建Dialog
- Activity,Service和Application都是间接的继承自Context的,因此一个应用程序中Context的数量=Activity+Service+Application ,这个类的继承关系如下:
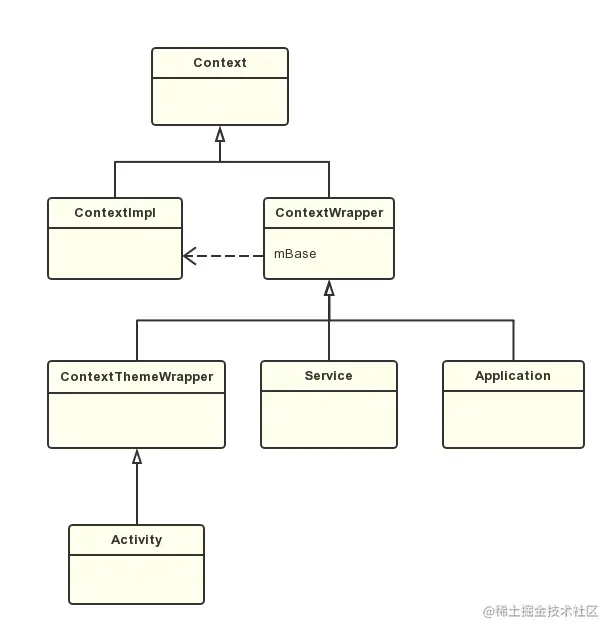
- ApplicationContext:生命周期与Application的生命周期一样长,全局唯一,与activity的生命周期无关
- Activity:生命周期与Activity相关,每一个Activity都会有一个对应的ActivityContext
- 凡事跟UI相关的,都应该使用Activity作为Context来处理,其他的一些操作,Service,Activity,Appliocation等实例都可以
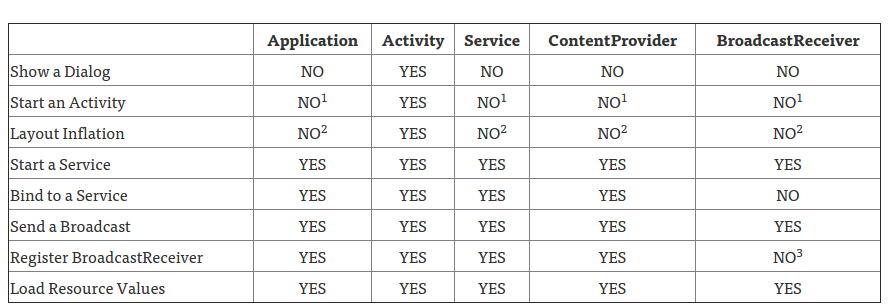
- 为了防止内存泄漏,使用context的时候特别注意:
- 不要让生命周期很长的引用activity context,即保证引用activity的对象要与activity生命周期一样长
- 生命长的对象引用使用ApplicationContext
- 为什么子线程不可以更新UI
- 其实子线程是可以更新UI的,只要在ViewRootImpl创建之前就行了,因为在更新UI操作的时候,我们会调用ViewRootImpl的checkThread方法,去判断mThread != Thread.currentThread() ,若为true,则会抛出异常
- ViewRootImpl的创建时机是什么时候呢?Activity.makeVisible---->WindowManagerImpl.addView---->WindowManagerGlobal.addView---->new ViewRootImpl() ,这个时候我们知道了ViewRootImpl的创建调用过程,那我们更加关注的是谁调用了Activity.makeVisible,从Acitivity声明周期handleResumeActivity会被优先调用到,也就是说在handleResumeActivity启动后(OnResume),ViewRootImpl就被创建了,这个时候,就无法在在子线程中访问UI了。
- 其实自线程更新UI,会导致UI显示的不确定性,线程共同访问更新操作同一个UI控件时容易发生不可控的错误但是若是我们加锁,耗时会比较多。
- 推荐阅读:Android 子线程更新UI了解吗?