“聚类+Transformer”俩搭档配享太庙!这方向发A会根本不用忧!
最近发现CVPR、ICCV、Neurips等顶会上有关聚类+Transformer的论文还真不少,而且基本都是效果很好,创新点很值得参考的成果。
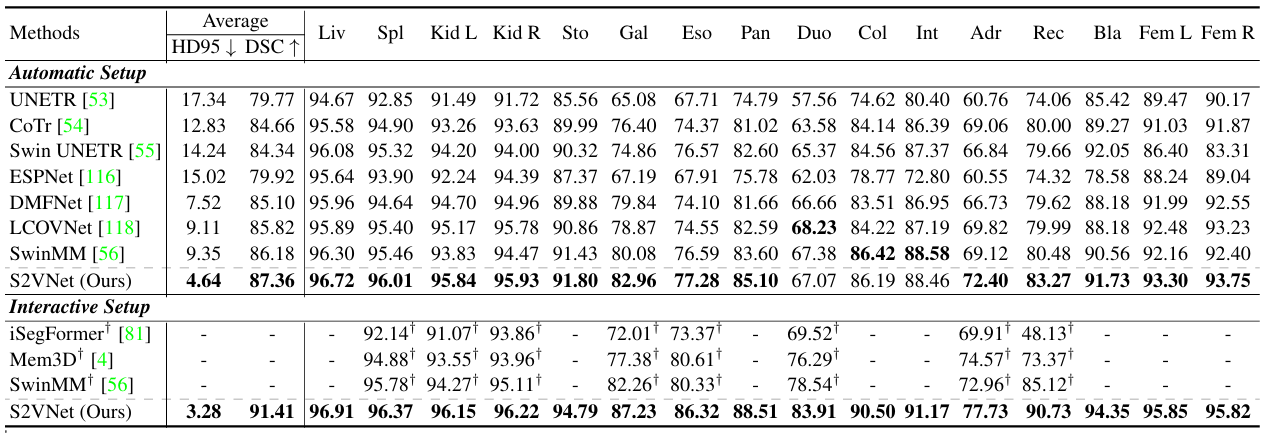
比如CVPR2024的S2VNet新型框架,结合了聚类方法和Transformer架构来实现通用的医学图像分割,性能在多个数据集上超越了SOTA,且推理速度提升近15倍,内存使用减少48.2%。
可见聚类+Transformer这个处理序列/文本数据的创新方法确实有很高的研究价值,再加上它本身就有很多优势,不仅能增强特征表示和模型性能,还能优化计算效率,提高模型的可解释性,为图像分割等聚类任务提供新的解决方案。
因此这也是个很值得发表论文的主题,我这边为了方便大家找思路找idea,已经整理好了12篇最新的聚类+Transformer论文,全部都有代码,想发论文的朋友别错过呀。
论文原文+开源代码需要的同学看文末
Clustering propagation for universal medical image segmentation
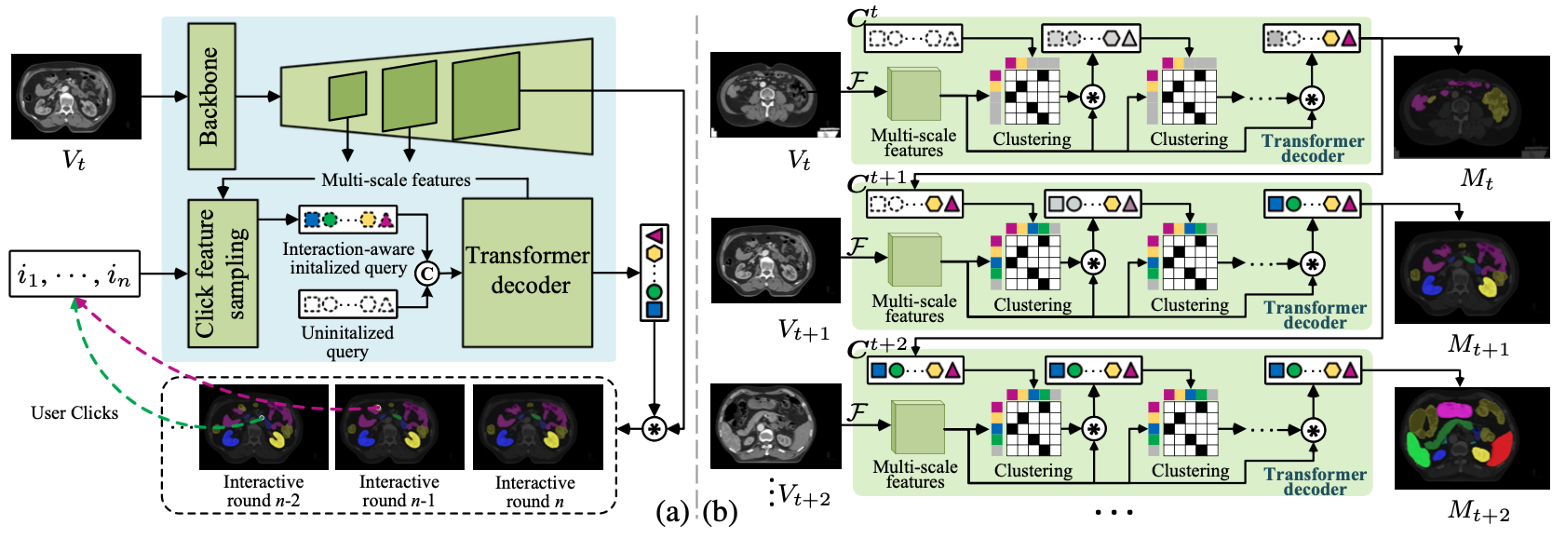
方法:论文提出了一种名为S2VNet的通用分割框架,通过切片到体积的传播策略,利用聚类方法来统一处理自动和交互式医学图像分割任务,克服了现有解决方案在慢速推理、远程切片联系不足等方面的局限性,显著提高了分割精度和效率。
创新点:
-
提出了一种切片到体积的传播机制,通过聚类的方法将前一切片的聚类结果(即聚类中心)传递到下一切片。
-
该框架在不改变网络架构的情况下,通过用户交互指导整个体积的分割,并支持任意数量的类,每个类都可以用来初始化一个聚类中心。
-
利用用户输入的点击位置初始化聚类中心,从而实现了基于聚类的交互式分割策略。
ClusterFomer: Clustering As A Universal Visual Learner
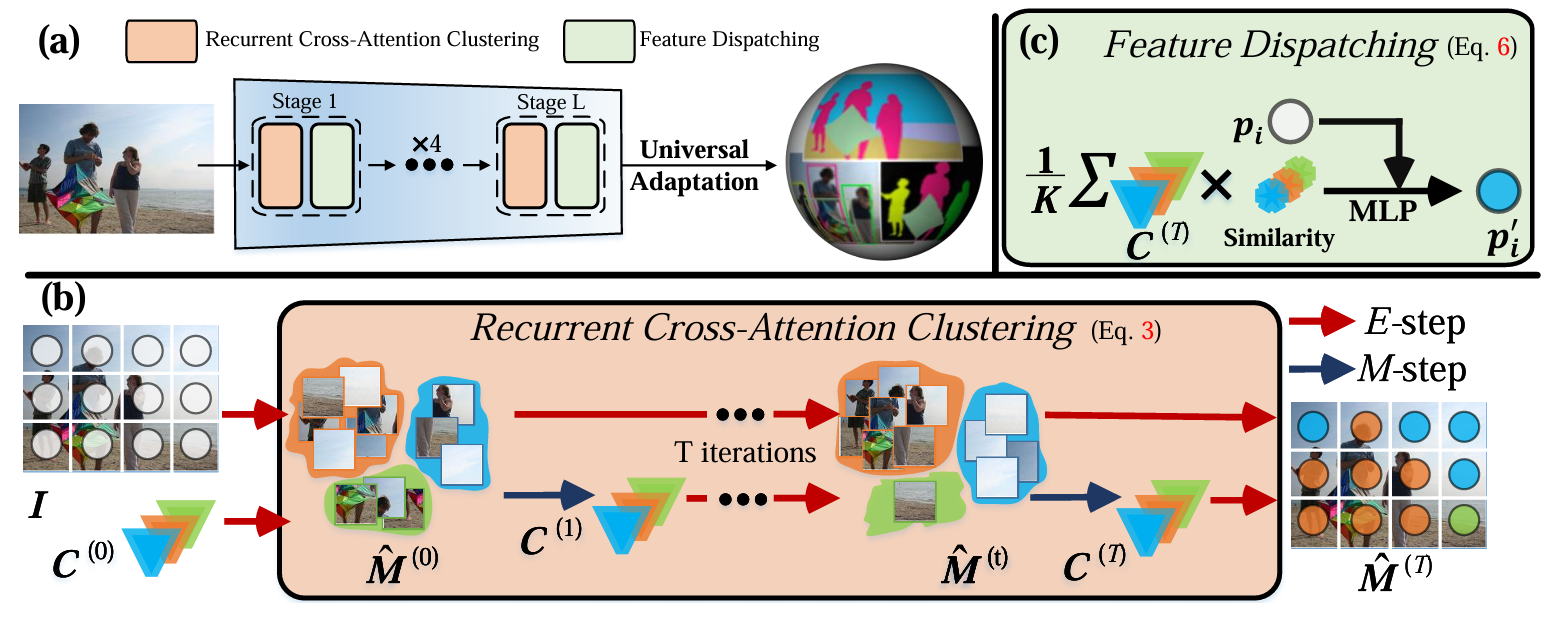
方法:论文提出了一种名为CLUSTERFORMER的通用视觉模型,基于聚类和Transformer范式,通过递归交叉注意力聚类和特征分派的新颖设计,解决图像分类、目标检测和图像分割等异构视觉任务。
创新点:
-
通过重新定义Transformer中的交叉注意力机制,实现了聚类中心的递归更新,增强了表示学习的能力。
-
通过更新后的聚类中心,以基于相似性的度量重新分配图像特征,从而实现透明的工作流程。
-
提出了一种基于聚类的统一视觉框架,能够在不同聚类粒度上处理异构视觉任务。

Tore: Token reduction for efficient human mesh recovery with transformer
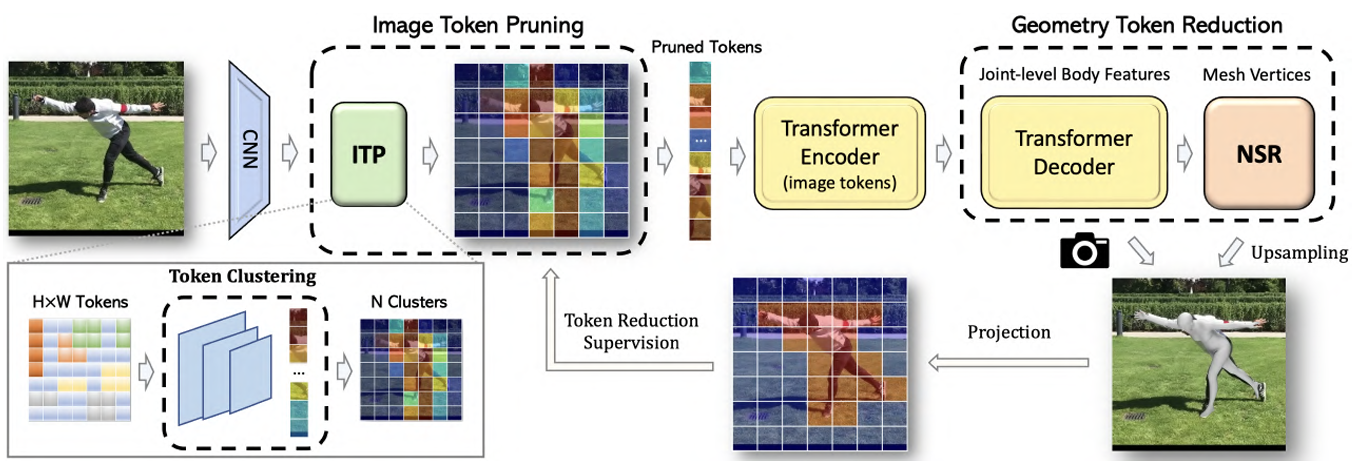
方法:论文提出了一种简单而有效的令牌减少(TORE)策略,通过结合3D几何结构和2D图像特征来减少Transformer中的冗余令牌。这种方法通过体结构的先验信息逐步恢复网格几何,并进行令牌聚类,以传递更少但更具辨识力的图像特征令牌。
创新点:
-
提出了减少Transformer中冗余token的策略,以降低计算复杂度。
-
引入了基于聚类的新型注意力机制,提高了模型效率和可解释性。
-
开发了适用于自动和交互式医学图像分割的统一框架,提升了性能和实用性。
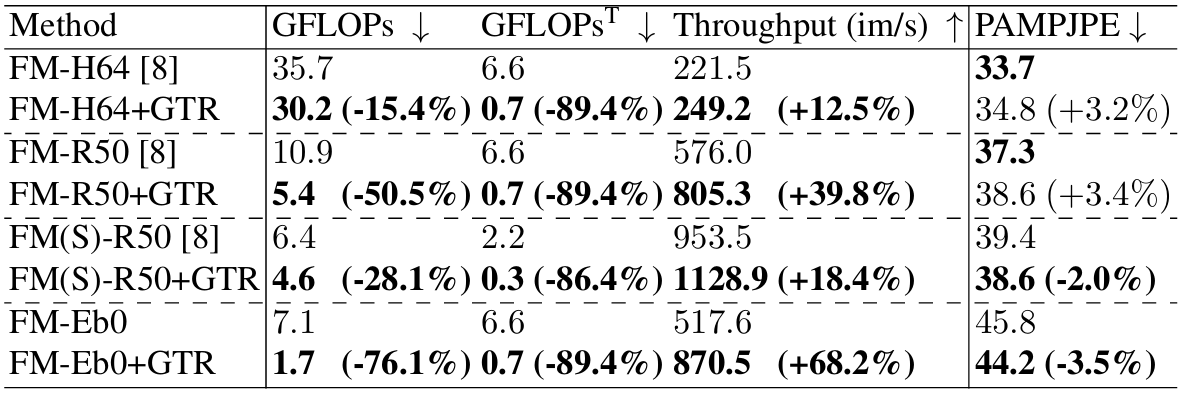
PaCa-ViT: learning patch-to-cluster attention in vision transformers
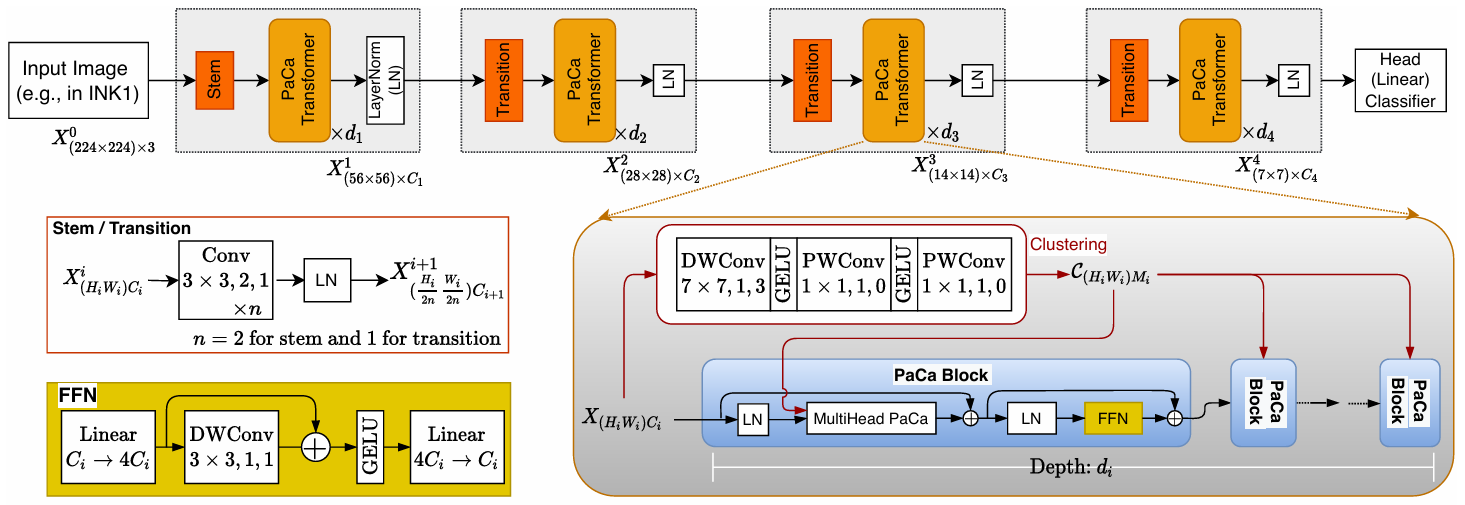
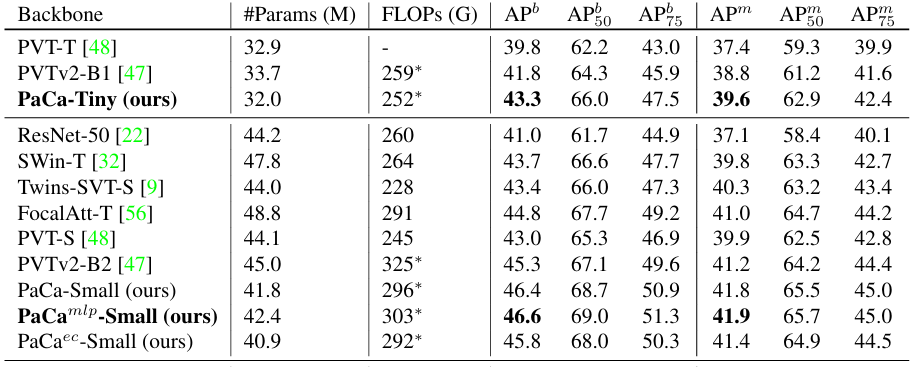
方法:论文介绍了一种名为PaCa-ViT的方法,它结合了聚类和Transformer技术来提高视觉任务中的效率和可解释性,通过学习Patch-to-Cluster Attention来减少传统patch-to-patch注意力机制中的二次复杂度问题,并利用聚类来捕捉图像中更有意义的视觉token。
创新点:
-
从传统的Patch-to-Patch注意力机制转变为Patch-to-Cluster的注意力机制,实现了从二次复杂度到线性复杂度的提升,显著提高了计算效率。
-
PaCa模块允许通过热图直观地可视化学到的聚类分配,为解释模型提供了一种直接的前向解释器,与传统的仅依赖注意力分数的方法形成互补。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“聚类结合”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏