o1背后的秘密:6种推理模式解析!
OpenAI的o1模型展示了在测试时计算方法(Test-time Compute methods)可以显著提升LLMs的推理能力,但其背后的机制尚未被充分探索。
通过与现有的测试时计算方法(BoN、Step-wise BoN、Agent Workflow和Self-Refine)进行比较,研究了o1模型在三个领域(数学、代码和常识推理)的一般推理基准上的表现:
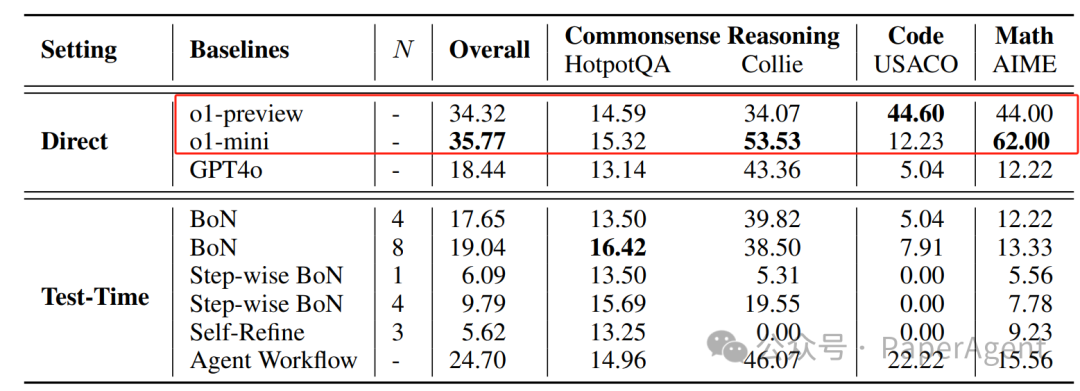
OpenAI的o1模型、GPT4o以及一些测试时计算方法在选定的四个基准测试(即HotpotQA、Collie、USACO、AIME)上的结果。表中的‘-’表示该方法不搜索多个响应以生成答案。“直接”指的是让大型语言模型(LLMs)直接从输入文本生成响应,而“测试时”指的是基于GPT-4o使用测试时计算方法。
-
Best-of-N (BoN):让LLMs为给定的输入生成多个N个输出,然后选择最合适的响应作为输出。
-
Step-wise BoN:使LLMs分析问题并将其分解为几个子问题。对于每一步,模型基于之前的子问题和答案生成N个响应,然后使用奖励模型来选择最佳响应。这个过程迭代进行,直到获得原始问题的最终答案。
-
Self-Refine:通过迭代反馈和细化来改进LLMs的初始输出。
-
Agent Workflow:LLM代理将复杂任务分解为更小的子任务,通过结构化的工作流程规划它们的执行,并使用各种工具来实现目标。对于常识推理数据集,研究者利用现有的最先进的代理框架进行评估。对于代码和数学数据集,选择了GPTs中的顶级代理,分别是代码 copilot和数学求解器。
实验结果:
-
o1模型在大多数数据集上表现最佳,特别是在编程和数学任务上。
-
自我完善方法的性能提升不显著。
-
BoN在HotpotQA上表现相对较好,但在Collie上性能下降。
-
Step-wise BoN在复杂任务上受限。
-
Agent Workflow在所有基准测试中表现显著提升,但仍与o1模型有差距。
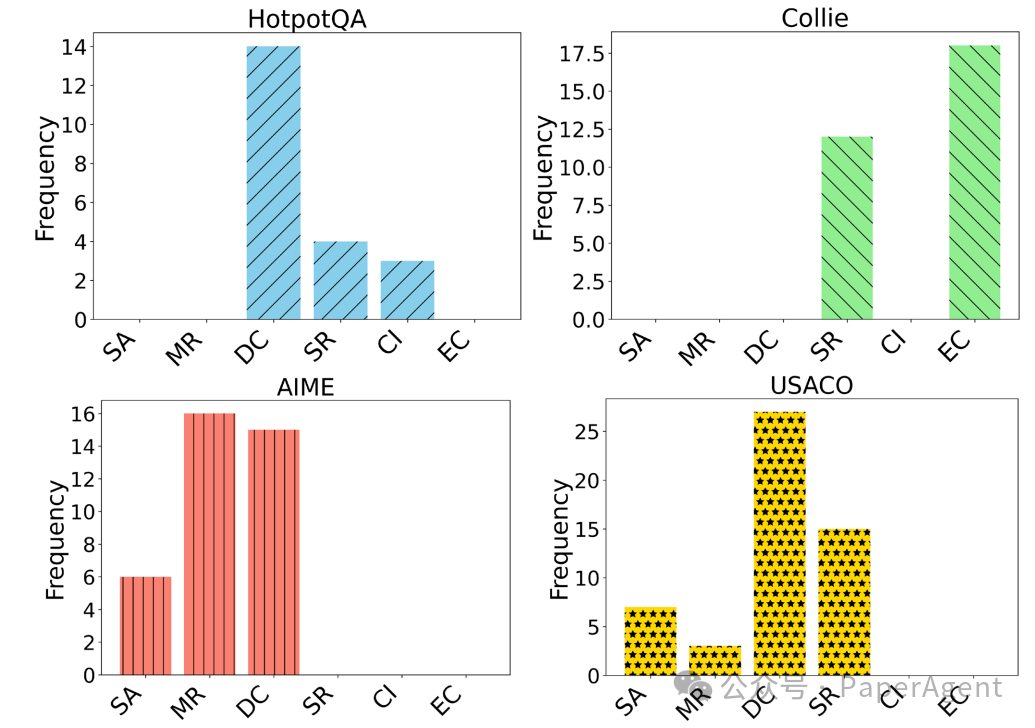
尽管o1模型总体上比其他模型表现得更好,但在某些特定任务中,一些测试时计算方法仍然能够取得与o1相近的结果。为此,分析了o1在不同任务中的推理模式,并总结了6种跨不同基准测试的推理模式,其中,DC和SR是最常用的推理模式,可能是o1成功的关键。
不同基准测试上不同推理模式的统计数据
-
系统分析(SA)。从问题的整体结构开始,o1首先分析输入和输出以及约束条件,然后决定算法的选择和数据结构的使用。
-
方法重用(MR)。对于一些可以转化为经典问题的问题(例如最短路径或背包问题),o1可以快速重用现有方法来解决它们。
-
分而治之(DC)。它将复杂问题分解为子问题,并通过解决子问题来构建整体解决方案。
-
自我完善(SR)。o1在推理过程中评估其推理过程,以确定是否存在任何问题并纠正任何错误。
-
上下文识别(CI)。对于一些需要额外信息输入的数据集(例如HotpotQA),o1首先总结与查询相关的上下文的不同方面,然后给出相应查询的响应。
-
强调约束(EC)。对于一些对生成文本有约束的数据集(例如Collie),o1通常在推理过程中强调相应的约束。
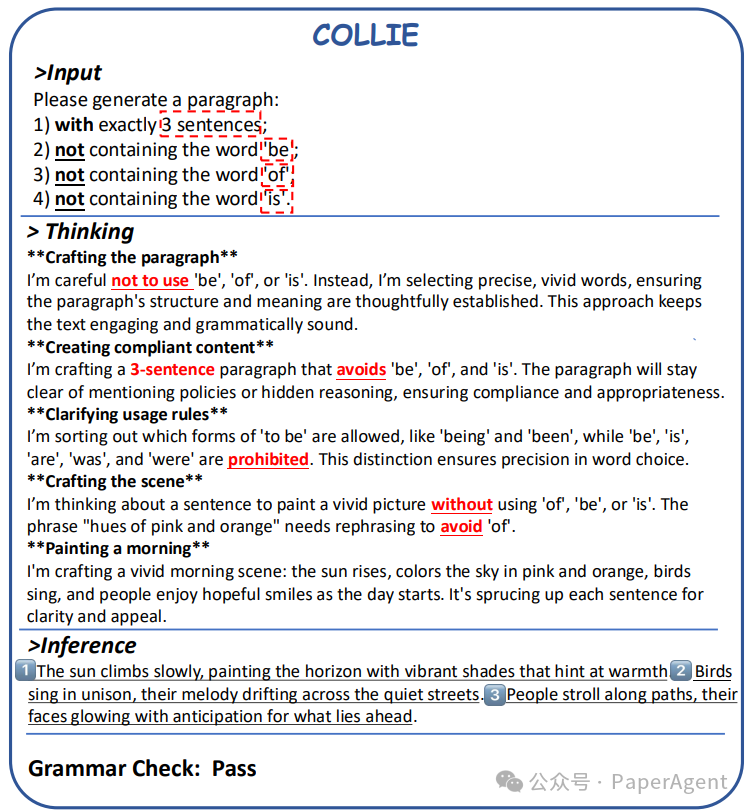
在COLLIE任务中,模型需要生成一个段落,这段落不仅要遵守特定的文本生成约束,还要确保内容的准确性和相关性。o1模型通过多次强调指令,强化了对这些约束的遵循,这对于需要严格控制生成内容的任务至关重要。
o1模型在美国计算机奥林匹克(USACO)竞赛中的表现,该竞赛专注于算法和问题解决技能。o1模型通过建立基础框架开始,定义关键变量和数据结构,然后应用算法逻辑进行状态转换,逐步产生最优解。此外,o1模型不仅考虑了所有可能的路径和场景,还使用了循环、递归等方法来严格验证每一步,这有助于o1全面覆盖问题的多个方面,并有效生成正确的解决方案。

https://arxiv.org/pdf/2410.13639A COMPARATIVE STUDY ON REASONING PATTERNS OF OPENAI’S O1 MODELhttps://github.com/Open-Source-O1/o1_Reasoning_Patterns_Study
来源 | PaperAgent
LLM热点Paper22
LLM热点Paper · 目录
上一篇一篇大模型数据合成和增强技术最新综述