97、Python并发编程:多线程实现的两种方式
引言
从这篇文章开始,我们开始把Python中的并发编程模型的支持来逐一介绍。首先是Python中关于多线程编程的支持,也就是基于threading模块来介绍如何进行多线程编程。
本文的主要内容有:
1、Thread类的常用方法
2、实现自定义线程的两种方式
Thread类的常用方法
在Python中要实现多线程编程,最简单的方式就是基于threading模块的Thread类来实现,首先来看下该类中的常用方法。
1、__init__()方法
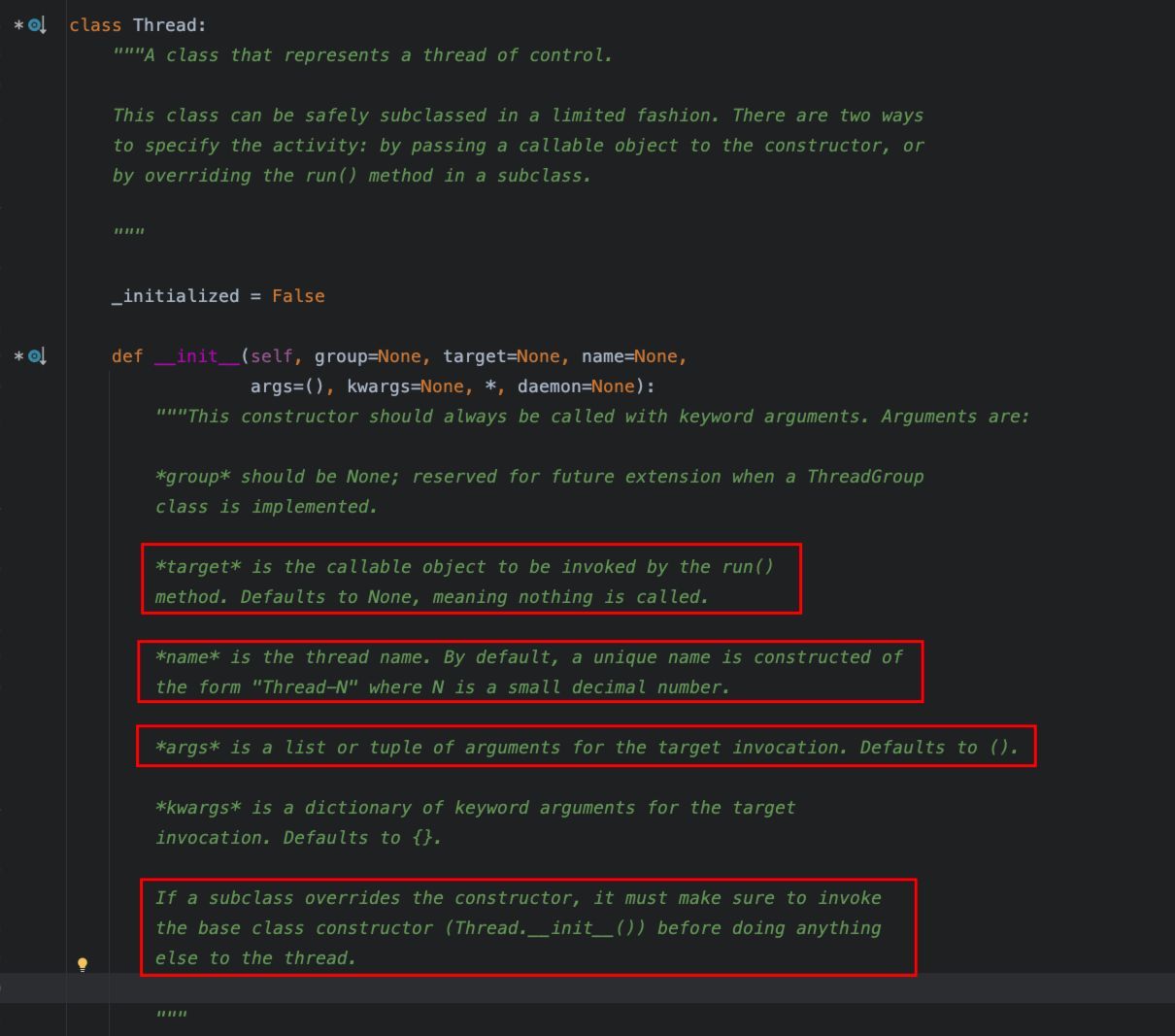
关于Thread类的初始化方法__init__(),从定义中可以看到:
1、参数target:是一个很核心的参数,用于实现线程要执行的主体业务逻辑,该参数接收一个可调用对象,通常可以是一个函数的引用。
2、参数args:是线程在执行时调用target参数时,需要传入的参数列表,必须是一个元组。
3、参数name:用于自定义线程的名称,默认情况下,每个线程都会有一个形式为“Thread-N"的唯一的名称,为了更好地辨别执行的每个自定义线程,建议指定自定义名称。
4、当我们通过继承Thread类来实现自定义线程类,重载__init__()方法时,必须首先调用Thread类的__init__()方法。
2、run()方法
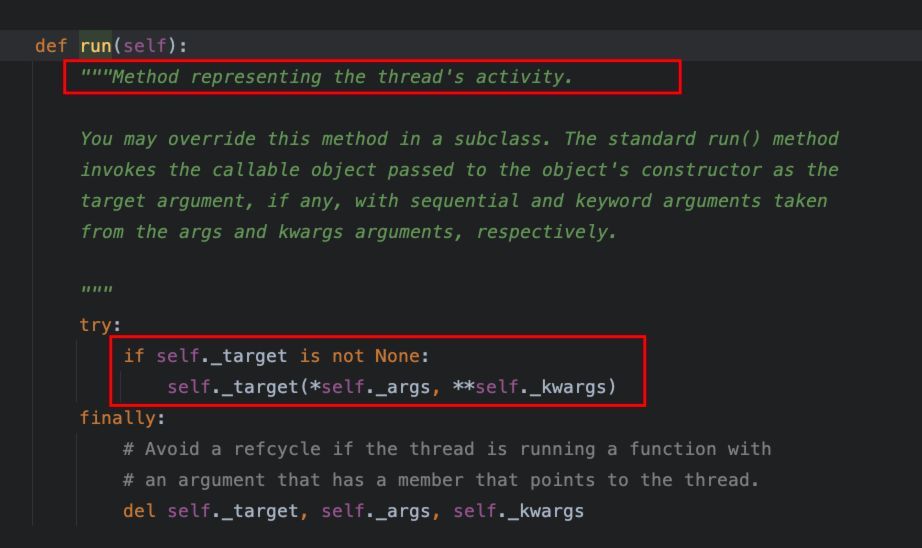
run()方法是线程中的核心方法,该方法的逻辑代表了线程所承载的业务行为。从文档中可以看出,Thread类的默认run()方法,是实现__init__()方法中所传递的target这个可调用对象的调用操作,同时将args作为参数传递。
如果自定义Thread的子类,通常应该实现该方法的重载,通常的做法是在run()方法中直接编写线程所要实现的业务功能。
需要注意的是,run()方法不应该被直接调用,而是通过Thread对象的start()方法来进行间接调用,否则只是简单的方法在当前线程中的执行,而非新建线程。
3、start()方法
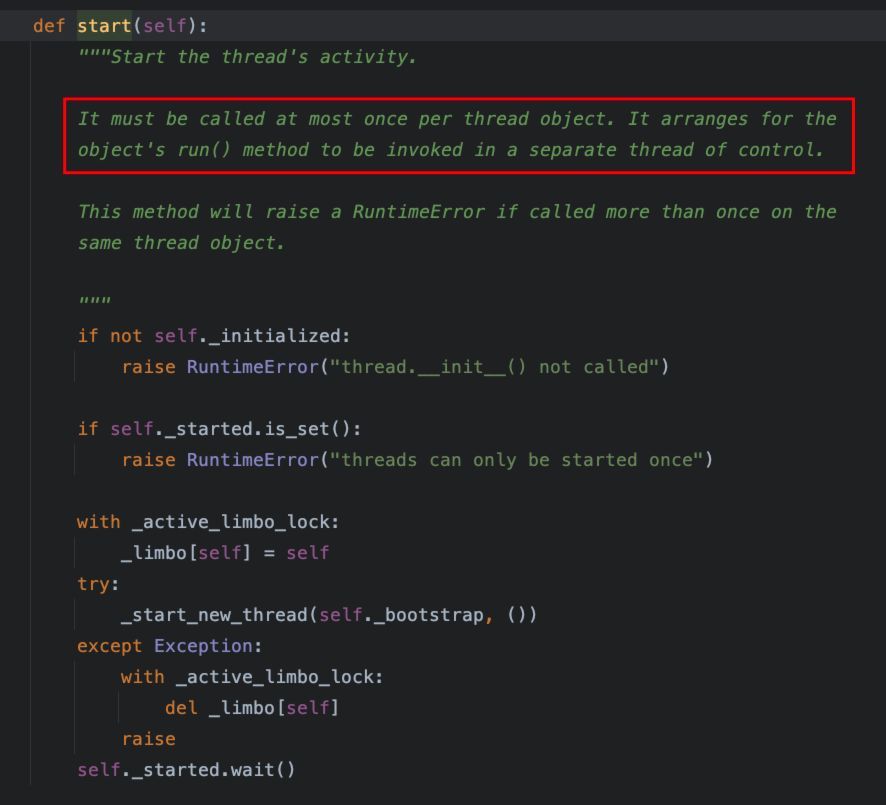
start()方法,用于启动一个线程对象的执行,需要注意的是,该方法最多只能被调用一次,该方法的调用,会将该线程对象的run()方法安排在一个控制线程中等待被调用。
4、join()方法
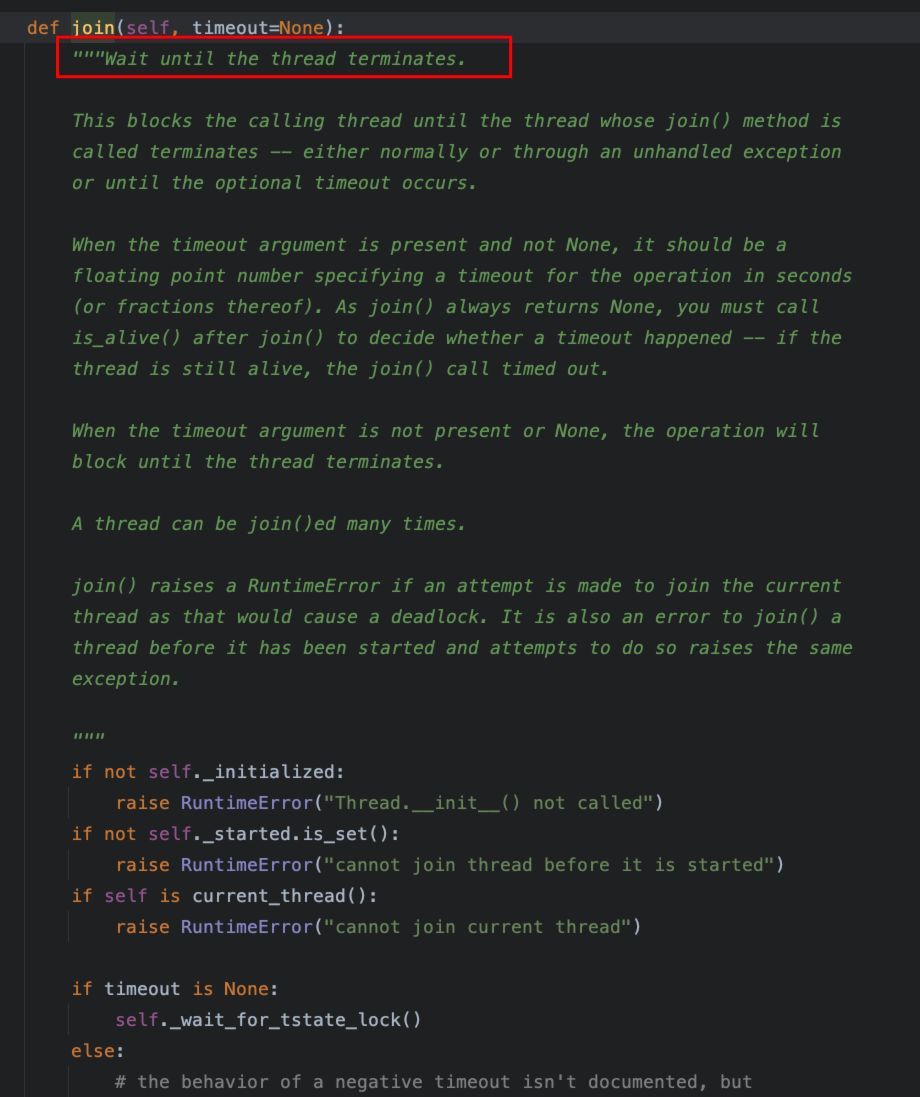
当某个线程对象的join()方法被调用时,则当前正在执行的线程的执行会被阻塞,直到调用了join()方法的线程对象执行完成才会继续执行。
该方法通常用于进行多个线程之间执行的组织、编排。
5、setDaemon()方法
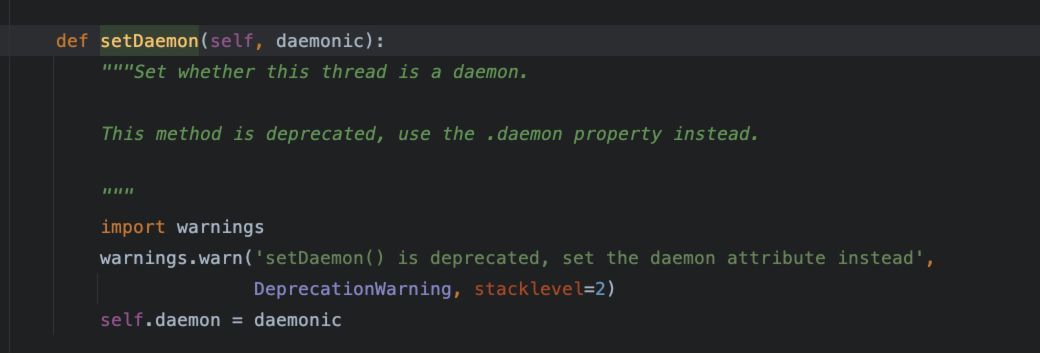
该方法用于将一个线程设置为守护线程。从文档中,可以看到该方法已经被标记废弃了,后续应当使用daemon这个属性来进行守护线程的设置。
需要说明的有:
1)所谓守护线程是指在后台运行的线程,它存在的目的是为其他非守护线程(也就是用户线程)提供一些支持和服务。
2)当所有的非守护线程都终止时,守护线程会自动终止。
实现自定义线程的两种方式
了解了Thread类中常用的方法之后,我们来看看在Python中实现多线程编程的两种方式(在其他语言中,也基本是类似的方式)。
1、直接使用Thread来实例化线程对象
这种方式主要通过以下步骤来实现:
1)自定义函数封装线程要实现的业务行为。
2)将自定义函数作为target参数,相应的函数实参作为args参数,调用Thread的__init__()方法,来实例化线程对象。
3)调用线程对象的start()方法来启动子线程的执行。
直接看代码:
from threading import Thread
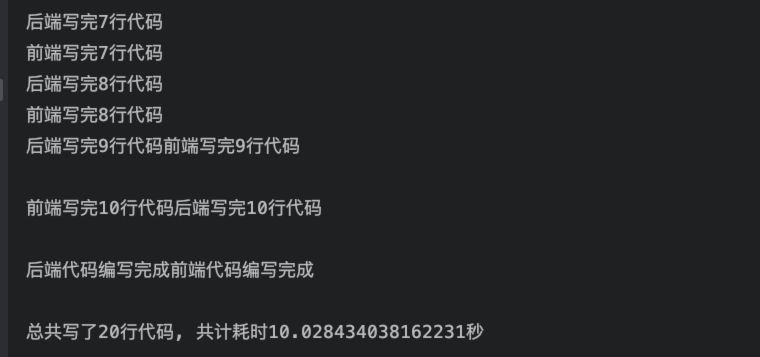
import timelines = 0def code(name, n):global linesprint(f'{name}开始写代码')for i in range(n):print(f'{name}写完{i + 1}行代码')lines += 1time.sleep(1)print(f'{name}代码编写完成')if __name__ == '__main__':frontend_coder = Thread(target=code, args=('前端', 10))backend_coder = Thread(target=code, args=('后端', 10))start_time = time.time()frontend_coder.start()backend_coder.start()frontend_coder.join()backend_coder.join()print(f'总共写了{lines}行代码, 共计耗时{time.time() - start_time}秒')
代码的执行结果:
2、自定义Thread类的子类来自定义线程对象
这种方式来实现多线程主要有以下步骤:
1)自定义类继承自Thread类
2)重载__init__()方法,用于实现相关自定义属性、参数的初始化。在__init__()方法中,记得要首先调用Thread类的__init__()方法。
3)重载run()方法,实现自定义线程的业务功能主体。
直接看代码:
from threading import Thread
import timelines = 0class CoderThread(Thread):def __init__(self, coder, line):super().__init__()self.coder = coderself.line = linedef run(self):global linesprint(f'{self.coder}开始写代码')for i in range(self.line):print(f'{self.coder}写完{i + 1}行代码')lines += 1time.sleep(1)print(f'{self.coder}代码编写完成')if __name__ == '__main__':frontend_coder = CoderThread('前端', 10)backend_coder = CoderThread('后端', 10)start_time = time.time()frontend_coder.start()backend_coder.start()frontend_coder.join()backend_coder.join()print(f'总共写了{lines}行代码, 共计耗时{time.time() - start_time}秒')
执行结果与第一种方式完全一样,这里就不贴出来了。
3、两种方法的比较
直观来看,第一种方式似乎更加简洁,所以,初学者通常会更倾向于使用第一种方式。其实,两种方式各有其适用的场景。
实例化Thread对象的方式,更加适用于简单的并发任务,不需要进行复杂的状态管理。语法简单、代码量少、能够快速实现并发任务。但是,缺点是对于复杂的逻辑或者状态管理不够灵活。
通过继承Thread类来实现多线程的方式,更加适用于需要封装复杂逻辑或者状态管理的并发任务。灵活性高、易于扩展和重用、代码的组织更加模块化。但是,缺点就是语法相对复杂,需要编写一些样板代码。
总结
本文简单介绍了threading模块中的Thread类中的常用方法,介绍了在Python中基于threading模块实现多线程编程的两种方式,并对这两种方式做了一个简单的比较。在多种方法的选择中,我们要遵循的首要原则还是”选择最适合当前业务场景的方法“。没有最好,只有更适合。
以上就是本文的全部内容了,感谢您的拨冗阅读,希望对您学习Python并发编程有所帮助。
