MedSAM微调版,自动生成 Prompt 嵌入实现图像分割!
最近提出的Segment Anything Model (SAM)等基础模型在图像分割任务上取得了显著的成果。
然而,这些模型通常需要通过人工设计的 Prompt (如边界框)进行用户交互,这限制了它们的部署到下游任务。
将这些模型适应到具有完全 Token 数据的特定任务也需要昂贵的先验用户交互以获取真实标注。
本工作提出了一种替换输入 Prompt 条件的方法,该方法使用一个轻量级的模块直接从图像嵌入中学习 Prompt 嵌入,然后由基础模型使用这两个嵌入分别输出分割 Mask 。
作者的可学习 Prompt 的基础模型可以自动对任何特定区域进行分割,1)通过一个由简单模块预测的 Prompt 嵌入修改输入,2)使用弱标签(紧密边界框)和少样本监督(10个样本)。
作者的方法在MedSAM(SAM在医学图像上的微调版本)上进行了验证,并在MR和超声成像的三个医学数据集上获得了结果。作者的代码已在https://github.com/Minimel/MedSAMWeakFewShotPromptAutomation上发布。
1 Introduction
标注是医学影像中一个众所周知的人力密集型和耗时任务。经过训练用于识别特定感兴趣区域的有监督分割模型对新领域或类别的泛化性能不佳,在考虑新任务时需要更多的数据和再训练。这增加了解决多个任务分割模型的成本。因此,在训练后能够适用于各种任务的通用模型在医学影像分析中的需求正在增长。
像最近推出的Segment Anything Model (SAM) [10]这样的图像分割基础模型的出现,以及其针对医学影像的版本,如适应医学影像的MedSAM [12],在计算机视觉和医学图像分析领域产生了重大影响。这些模型在各种分割任务上表现出色。然而,它们仍然是需要用户交互才能获得目标目标分割 Mask 的即时模型。
此外,它们的零样本性能取决于用户 Prompt 的质量。对用户交互的依赖性阻碍了它们集成到自动 Pipeline 中,并限制了它们在大规模使用中的效用。
最近,人们尝试自动化SAM(Segmentation, Association, and Mapping)的 Prompt 生成[20; 17; 22]。然而,这些方法通常需要具有 GT 分割 Mask 的样本,这在医学领域获取起来是昂贵的。
这篇论文提出了一种轻量级的附加 Prompt 模块,该模块可以直接从SAM的图像嵌入中学习生成 Prompt 嵌入。作者的端到端方法使SAM模型能够专门针对特定区域进行分割,并只需要少量弱标注的样本。这降低了开发专门分割模型的交互成本。作者的验证结果表明,在仅用紧密框标注少量训练样本的情况下, Prompt 基础模型可以有效地生成目标区域的分割 Mask ,而无需手动 Prompt 输入。
医学图像分割的基础模型医学图像分割的基础模型通过大规模预训练在计算机视觉任务中取得了巨大的成功。特别是,基于视觉 Transformer 的Segment Anything Model (SAM) [10]最近被引入作为医学图像分割的 Prompt 驱动基础模型,它基于10亿张图像和1亿张 Mask 进行了预训练。
在自然图像上训练的SAM在医学数据上的表现不均匀[7; 13; 18],导致其适应医学领域[4; 12; 17]。特别是,MedSAM [12],一种用于通用医学图像分割的基础模型,是在10种成像模式下,基于150万图像- Mask 对进行预训练的。这些模型在零样本性能上令人印象深刻,但仍然需要用户交互进行推理。
Prompt 自动化对SAM的影响。 由于在自然语言处理领域的出色表现 [2], Prompt 调优已成功应用于大型视觉模型 [8]。因此,专注于专门化SAM(可 Prompt 模型)的方法自然地探索了 Prompt 生成。在极少完全标注的样本情况下,文献[20]中的自 Prompt 单元自动从SAM的图像嵌入中生成一个实际点及其边界框。AutoSAM用谐波密集网络取代SAM的 Prompt 编码器,以适应医学图像的分割 [17]。
最近一种无需训练的方法,PerSAM [22]将正负位置先验编码为 Prompt Token ,以从单个参考图像和 Mask 中生成特定物体的自动分割。与作者的方法不同,所有这些方法都需要具有完全分割 Mask 的样本。
基于边界框标注的分割。边界框已成为标注麻烦的替代方案。大多数方法将边界框作为目标区域的初始伪标签。经典的迭代图割算法GrabCut [16]在给定边界框的情况下将前景与背景分离。
DeepCut [14]使用现有的启发式方法将GrabCut扩展到神经网络。最近,边界框紧度先验被适应到基于深度学习的模型,通过针对预测施加一组约束[9],并与多实例学习和平滑最大近似[19]相结合。
2.1.1 Our contribution.
这项工作旨在高效地自动化医学领域的SAM(单细胞自动标注)变体MedSAM,通过使用少量的弱 Token 样本即可分割任何目标区域。作者的方法通过将原始 Prompt 编码器替换为增强的轻量级可调整 Prompt 学习模块来实现创新改进:
自动生成输入图像的 Prompt 嵌入
仅使用弱标签(紧密的边界框)进行训练,以及少样本学习
易于在MedSAM顶部添加(无需微调) 接下来几节作者将介绍作者为MedSAM提出的 Prompt 模块,并展示其在各种医学图像分割任务上的实用性。
2 Methodology
Preliminaries: MedSAM architecture
作者的方法基于MedSAM [12],这是一种针对医疗数据的SAM [10]变体微调的模型。该模型包含三个主要组件:一个大型图像编码器 ,一个 Prompt 编码器 和一个轻量级的 Mask 解码器 。
尽管图像编码器计算输入图像x的嵌入,但 Prompt 编码器会从提供的 Prompt 集[pr]中分别输出两个稀疏和密集的嵌入:分别是点或边界框(BB),以及一个 Mask 。网络通过将x和 Prompt 嵌入Z_{pr}=E_{pr}([pr])相乘来产生一个概率图:
σ 是 sigmoid 函数。
作者提出了一个端到端的方法,该方法无需修改预训练的MedSAM网络,即可移除对用户定义 Prompt 的典型依赖。
Lightweight prompt module
作者的方法包括一个用于直接计算由MedSAM提供的图像嵌入的 Prompt 模块(见图1b)。该模块输出与MedSAM生成的嵌入相同形状的两个嵌入(见图1a)。最初,密集的 Prompt 嵌入具有与图像的空间对应关系,可以被视为低质量的分割图,而稀疏嵌入是坐标的空间编码。因此,作者的 Prompt 模块通过卷积层生成一个密集嵌入,通过全连接(FC)层生成一个稀疏嵌入。

Learning with tight box annotations
定义一个3通道输入图像 ,其中 对应于图像的每个通道,且高度为 ,宽度为 。此外,令 是 的真实二值分割 Mask 。假设作者只拥有目标紧边界框 的信息。 和 分别定义在边界框内部和外部的区域,且 。这导致了一个由边界框标注 产生的约束优化问题 [9]。
《的虚无》
由于中定义的边界框必须包含目标目标,因此中只能包含前景。因此,作者可以对中的所有像素应用交叉熵损失:
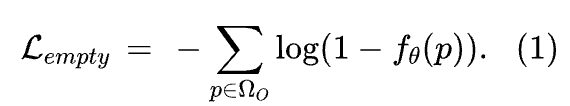
紧边界框约束在中。边界框的紧致性表明,至少有一个前景像素必须穿过弱标签中的每一条水平和垂直线。如同[9]中所述,作者通过考虑宽度为的段而不是单个线来软化这一条件,并通过对输出概率而不是预测 Mask 进行考虑来确保可导性。该条件可表述为:
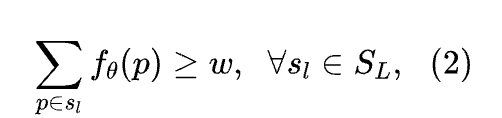
所有宽度为的垂直和水平分段构成了边界框。作者将式(2)的不等式约束转换为损失函数,得到:
惩罚函数可以被建模为一种简单的缩放ReLU函数,即 。在本工作中,作者转而采用一个伪对数屏障函数,它在多个相互竞争的约束下提供了更稳定的优化。当 时,函数 表现为一个硬屏障,当 时,,否则 。在作者的方法中,作者发现固定 是最优的。
前景框大小约束。 边界框 也限制了预测 Mask 的目标大小。同样,作者考虑输出概率而不是单个预测以确保可区分性。通过在来自 的 个像素(其中 )上应用先验,作者得到:
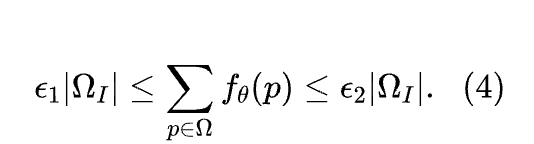
正如之前,作者使用将这些不等式约束转换为以下损失:
给定(1),(3)和(5),以及权重和,最终的损失变为:
3 Results
Datasets
作者的实验在三个公开数据集上验证了作者的方法:头围数据集2(HC18)[6],多结构超声分割心脏采集(CAMUS)[11]和自动心脏诊断挑战(ACDC)[1]。对于心脏数据集,作者使用的是舒张末期图像。对于HC18,作者从周长标注中过滤出不能由OpenCV自动生成的真实 Mask 样本,并将超声数据集分为507张训练图像、77张验证图像和148张测试图像。对于CAMUS,作者专注于左心室(LV)和左心房(LA)分割,并使用50张图像进行验证,100张图像进行测试,剩下的350张图像用于训练。
对于ACDC,作者专注于右心室(RV)和左心室(LV)分割,并使用10名患者进行验证(78张图像),50名患者进行测试(470张图像),剩下的90名患者(765张图像)用于训练。所有实验中的每个样本都有最小的前景大小。
参考[12],作者的预处理包括将每个2D图像(HC18,CAMUS)或每个3D体积(ACDC)的强度值在0.5百分位数和99.5百分位数之间截断,并将其重缩放到[0, 255]范围内。作者还把每个ACDC的3D体积划分成2D图像,并将其重新采样到固定的1mm×1mm分辨率。
对每个样本进行中心裁剪和填充,使其大小为640×640(HC),512×512(CAMUS)或256×256(ACDC)。
为了满足MedSAM的要求,作者在将其输入模型之前,将所有图像都调整为固定的3×1024×1024大小。
Implementation details
3.2.1 Model.
作者的 Backbone 模型是基于ViT-B的MedSAM,这是SAM的最小版本。在训练过程中, Backbone 模型保持冻结。作者通过使用较少的层来保持 Prompt 模块的轻量。首先,一个1x1卷积层将通道数减少。然后,通过一个3x3卷积得到稠密嵌入,通过一个1x1卷积层、池化层和全连接层得到稀疏嵌入。所有卷积层后跟ReLU激活函数。因此,作者的 Prompt 模块有2.4M可训练参数。
3.2.2 Loss parameters.
作者使用 训练 Prompt 模块,其中 ,。对于作者的紧密边界约束,作者遵循 [9] 并使用 的段。作者假设前景区域至少是其紧密边界框的一半大小,并设置 。与使用完整分割 Mask 的比较训练使用二进制交叉熵 Dice 损失,每个项具有相同的权重。
3.2.3 Training.
作者使用批量大小4,学习率(LR)为0.001,使用多步调度器,在完成一半的epoch后,LR降低0.1,权重衰减为0.0001。为了降低计算复杂性,作者没有使用数据增强。这使得作者在初始迭代时保存图像嵌入后,可以丢弃MedSAM的图像和 Prompt 编码器,从而将总参数数量从96.1M减少到6.5M(仅2.4M可训练)。
在10-shot设置中,作者重复实验9次,每次随机选择3个初始种子和3个训练子集。结果对这些实验进行平均。所有实验都使用Python 3.8.10在NVIDIA RTX-A6000 GPU上使用PyTorch实现。
3.2.4 Baselines.
对于每个类别,作者将作者的方法与两种专门的任务单一模型进行比较:一个标准的UNet [15] 和一个TransUNet [3]。作者还验证了作者的方法与PerSAM [22]进行比较,它使用1-shot监督自动实现SAM,以及AutoSAM [17]使用谐波密集网络(41.6M参数)学习 Prompt 嵌入。
作者将UNet、TransUNet和AutoSAM在完整的分割 Mask 上进行训练,使用标准的交叉熵Dice损失。为了提高 Baseline 模型的性能,使用了更长的训练时间(200个周期)和更大的批量大小(24个)的TransUNet(遵循[3])。
同样,PerSAM的最佳结果是通过使用ViT-H Backbone 获得的。当 Prompt 使用最紧的边界框(没有噪声)时,MedSAM的结果也包含在内。
Validation on multiple medical segmentation tasks
作者使用骰子相似度得分(DSC)作为作者的评估标准。作者在三个数据集上评估作者的方法:CAMUS,MedSAM的内部验证集,以及HC18和ACDC,这两个数据集在MedSAM的训练期间从未见过。
这使作者能够验证 Prompt 模块在域内和跨域数据上有效学习哪个区域进行分割的能力。训练在完整的训练集和困难的10-shot模式上进行。
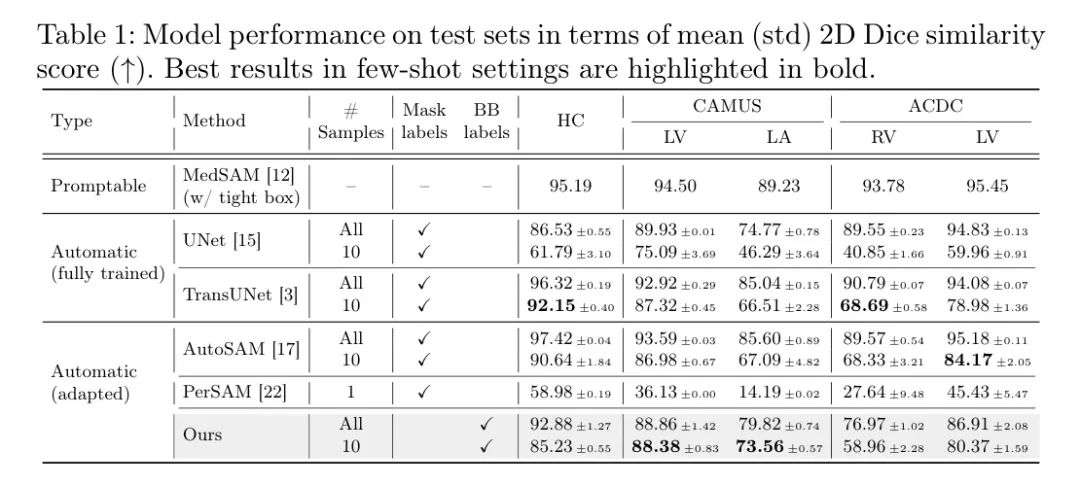
作者的结果如表1和图2所示。首先,仅使用紧检测框(BB)标注,作者的方法在两个不同的任务(HC和LA)上超过了在真实分割 Mask 上训练的UNet。最显著的结果出现在10-shot设置下。在仅使用1.3% (ACDC),2% (HC18) 和2.9% (CAMUS) 的总训练样本的情况下,作者的方法(除RV分割外)与全数据设置相比性能仅略有下降。这与UNet和TransUNet在多个分割任务中观察到的显著性能下降形成对比,即使这两种方法都使用真实 Mask 标签进行训练。因此,作者的基于模块的方法不仅在计算效率上比专业模型更高,而且只需要较弱的标签,在少样本设置下表现更强大。AutoSAM的测试dice分数略好于作者的方法,但AutoSAM需要完整的真实 Mask ,并且使用更重的模型来学习 Prompt ,导致训练时间增加了3倍。
此外,PerSAM使用只有一个参考图像,无法生成令人信服的分割。它在医学数据集上的性能不佳可能是因为PerSAM生成的点 Prompt 被SAM使用,这些 Prompt 更有可能引入歧义[12]。
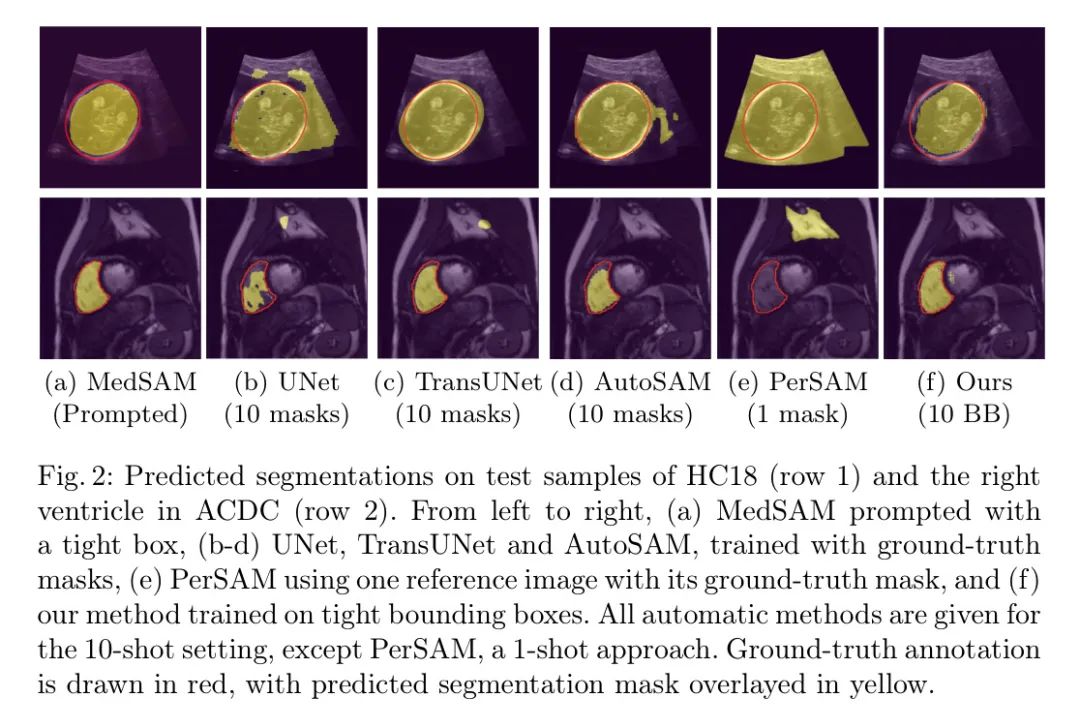
作者提出的方法的优点在图2中得到了视觉支持。作者的模块在10个训练样本和紧密的边界框上进行训练,产生的分割比使用真实 Mask 训练的UNet更具有说服力。
在训练数据较少的情况下,UNet在背景区域产生了大量假象。作者的方法还可以生成比AutoSAM和PerSAM两种现有的基于 Prompt 的适应方法对SAM更忠诚的分割 Mask 。
4 Conclusion
这项工作提出了一种自动化基于 Prompt 的全域模型(如MedSAM)的方法,该方法通过直接从基础模型的图像嵌入生成任务特定的 Prompt 嵌入。
作者可以将其集成到MedSAM中的附加模块直接去除对用户输入的依赖。
更重要的是,通过应用紧密性和大小约束,作者的模块可以仅使用边界框标注进行有效训练,同时让MedSAM保持不变。
此外,作者的10-shot实验表明,在不需要显著降低模型性能的情况下,可以大大减少训练模型所需的样本数量。
通过添加一个轻量级的 Prompt 模块,可以有效地使用少数弱标签进行训练,从而在最小化标注障碍的情况下,使MedSAM针对特定任务高效自动化。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。