[实时计算flink]Flink SQL作业快速入门
本文通过简单的示例,带您快速体验Flink SQL作业的创建、部署和启动等操作,以了解Flink SQL作业的操作流程。
前提条件
-
如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
-
已创建Flink工作空间,详情请参见开通实时计算Flink版。
步骤一:创建作业
-
进入SQL作业创建页面。
-
登录实时计算控制台。
-
单击目标工作空间操作列下的控制台。
-
在左侧导航栏,单击数据开发 > ETL。
-
-
单击新建后,在新建作业草稿对话框,选择空白的流作业草稿,单击下一步。
Flink也为您提供了丰富的代码模板和数据同步,每种代码模板都为您提供了具体的使用场景、代码示例和使用指导。您可以直接单击对应的模板快速地了解Flink产品功能和相关语法,实现您的业务逻辑,详情请参见代码模板和数据同步模板。
-
填写作业信息。
作业参数
说明
示例
文件名称
作业的名称。
说明
作业名称在当前项目中必须保持唯一。
flink-test
存储位置
指定该作业的代码文件所属的文件夹。
您还可以在现有文件夹右侧,单击

图标,新建子文件夹。
作业草稿
引擎版本
当前作业使用的Flink引擎版本。
建议使用带有推荐、稳定标签的版本,这些版本具有更高的可靠性和性能表现,引擎版本详情请参见功能发布记录和引擎版本介绍。
vvr-8.0.8-flink-1.17
-
单击创建。
步骤二:编写SQL作业
拷贝如下SQL到SQL编辑区域。本SQL示例使用Datagen连接器生成随机的数据流,并通过Print连接器将计算结果打印到实时计算开发控制台上。支持的更多连接器请参见支持的连接器。
--创建临时源表datagen_source。
CREATE TEMPORARY TABLE datagen_source(randstr VARCHAR
) WITH ('connector' = 'datagen' -- datagen连接器
);--创建临时结果表print_table。
CREATE TEMPORARY TABLE print_table(randstr VARCHAR
) WITH ('connector' = 'print', -- print连接器'logger' = 'true' -- 控制台显示计算结果
);--将randstr字段截取后打印出来。
INSERT INTO print_table
SELECT SUBSTRING(randstr,0,8) from datagen_source;说明
-
本SQL示例给出了用
INSERT INTO写入一个Sink,INSERT INTO也可以写入多个Sink,有关详情请参见INSERT INTO语句。 -
在实际生产作业中,建议您尽量减少临时表的使用,直接使用元数据管理中已经注册的表,详情请参见管理元数据。
步骤三:查看配置信息
在SQL编辑区域右侧页签,您可以查看或上传相关配置。
| 页签名称 | 配置说明 |
| 更多配置 |
|
| 代码结构 |
|
| 版本信息 | 您可以在此处查看作业版本信息,操作列下的功能详情请参见管理作业版本。 |
(可选)步骤四:进行深度检查
深度检查能够检查作业的SQL语义、网络连通性以及作业使用的表的元数据信息。同时,您可以单击结果区域的SQL优化,展开查看SQL风险问题提示以及对应的SQL优化建议。
-
在SQL编辑区域右上方,单击深度检查。
-
在深度检查对话框,单击确认。
(可选)步骤五:进行作业调试
您可以使用作业调试功能模拟作业运行、检查输出结果,验证SELECT或INSERT业务逻辑的正确性,提升开发效率,降低数据质量风险。
-
在SQL编辑区域右上方,单击调试。
-
在调试对话框,选择调试集群后,单击下一步。
如果没有可用集群则需要创建新的Session集群,Session集群与SQL作业引擎版本需要保持一致并处于运行中,详情请参见步骤一:创建Session集群。
-
配置调试数据,单击确定。
配置详情请参见步骤二:作业调试。
步骤六:作业部署
在SQL编辑区域右上方,单击部署,在部署新版本对话框,可根据需要填写或选中相关内容,单击确定。
说明
Session集群适用于非生产环境的开发测试环境,通过部署或调试作业提高作业JM(Job Manager)资源利用率和提高作业启动速度。但不推荐您将生产作业提交至Session集群中,可能会导致业务稳定性问题。
步骤七:启动作业并查看结果
-
在左侧导航栏,单击运维中心 > 作业运维。
-
单击目标作业名称操作列中的启动。
选择无状态启动后,单击启动。当您看到作业状态变为运行中,则代表作业运行正常。作业启动参数配置,详情请参见作业启动。
-
在作业运维详情页面,查看Flink计算结果。
-
在运维中心 > 作业运维页面,单击目标作业名称。
-
在作业日志页签,单击运行Task Managers页签下的Path, ID的任务。
-
单击日志,在页面搜索PrintSinkOutputWriter相关的日志信息。
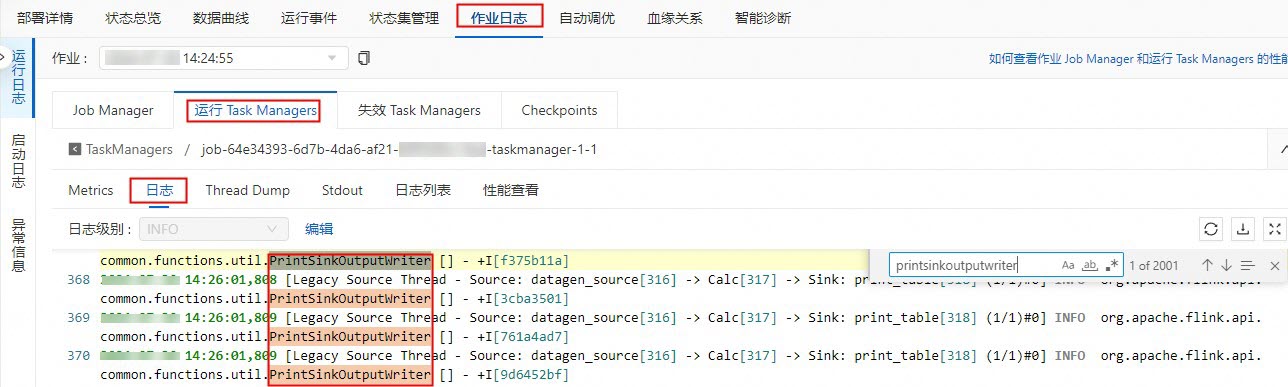
-
(可选)步骤八:停止作业
如果您对作业进行了修改(例如更改代码、增删改WITH参数、更改作业版本等),且希望修改生效,则需要重新部署作业,然后停止再启动。另外,如果作业无法复用State,希望作业全新启动时,或者更新非动态生效的参数配置时,也需要停止后再启动作业。作业停止详情请参见作业停止。