大模型~合集12
我自己的原文哦~ https://blog.51cto.com/whaosoft/12286764
#DISC-FinLLM
复旦大学团队发布中文智慧金融系统,采用多专家微调框架
金融领域为自然语言处理(NLP)模型带来了独特的挑战和机遇。当前,金融文本和数据的信息量和复杂性呈现爆炸式增长,一个强大、可靠的智慧金融系统可以满足多种不同用户群体的金融需要,例如辅助金融从业者完成行业分析、时事解读、金融计算、统计分析工作,为金融科技开发者完成情感分析、信息抽取任务,帮助学生解答金融问题等,从而有效地提高金融领域工作和学习的效率。
金融领域本身具有高度的专业性,语言模型一方面要处理复杂的金融语言,另一方面要保证知识储备的实时性和对金融文本内数据计算的准确性,故而过往的模型通常无法在该领域提供令人满意的服务。金融领域迫切需要准确、高效的人工智能解决方案来有效处理金融行业的各种任务。而最新出现的大语言模型(LLM)在语言交互及各类 NLP 任务展现出的出色能力,为智慧金融系统的进一步发展和普及提供了新的思路。
复旦大学数据智能与社会计算实验室(FudanDISC)发布金融领域的大语言模型 ——DISC-FinLLM。该模型是由面向不同金融场景的 4 个模组:金融咨询、金融文本分析、金融计算、金融知识检索问答构成的多专家智慧金融系统。这些模组在金融 NLP 任务、人类试题、资料分析和时事分析等四个评测中展现出明显优势,证明了 DISC-FinLLM 能为广泛的金融领域提供强有力的支持。课题组开源了模型参数,并且提供了翔实的技术报告和数据构建样例。
- 主页地址:https://fin.fudan-disc.com
- Github 地址:https://github.com/FudanDISC/DISC-FinLLM
- 技术报告:http://arxiv.org/abs/2310.15205
1. 样例展示

图1 金融咨询示例
用户可以通过金融咨询模组询问金融专业知识,提高学习效率,或是与模型展开金融主题的多轮对话,拓宽金融视野。
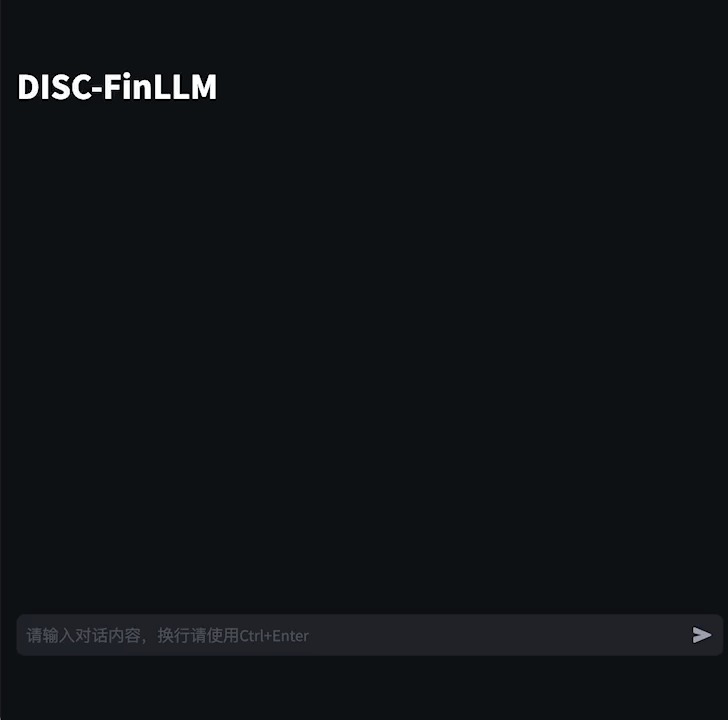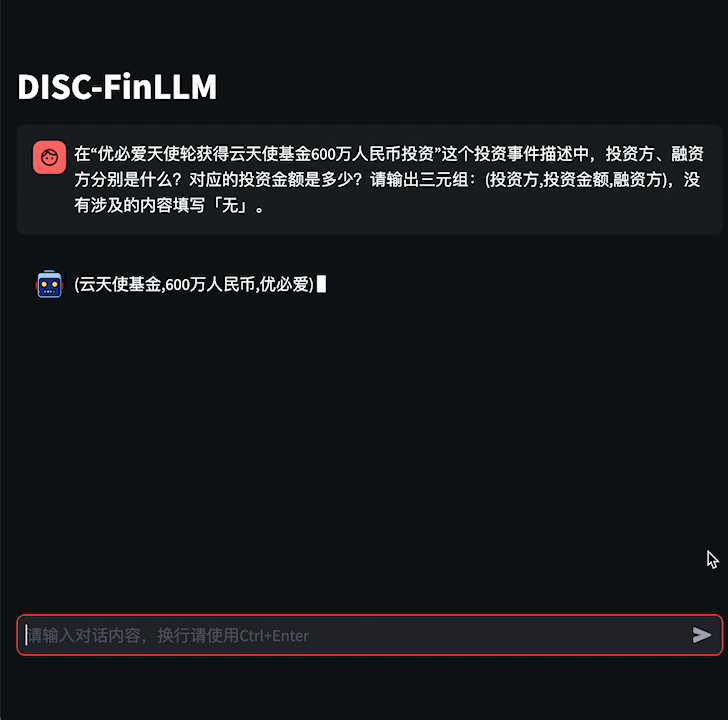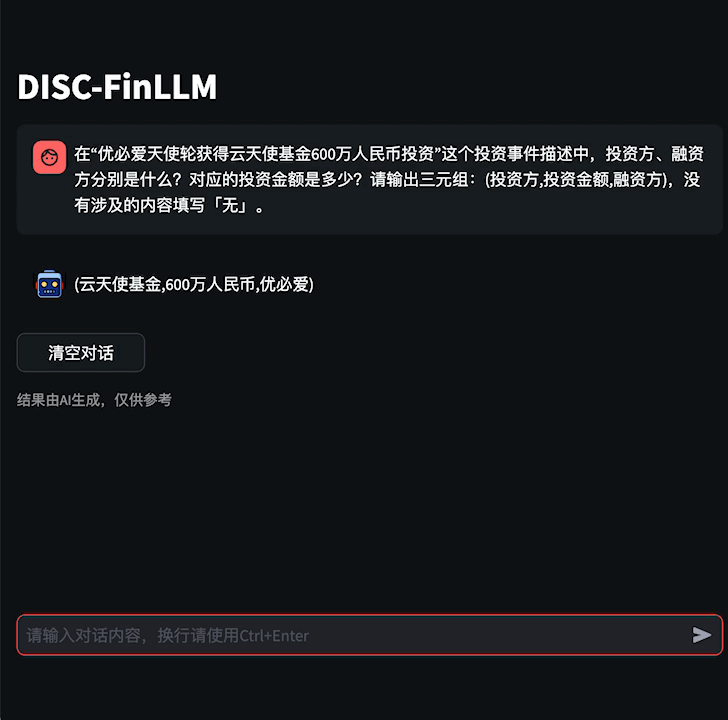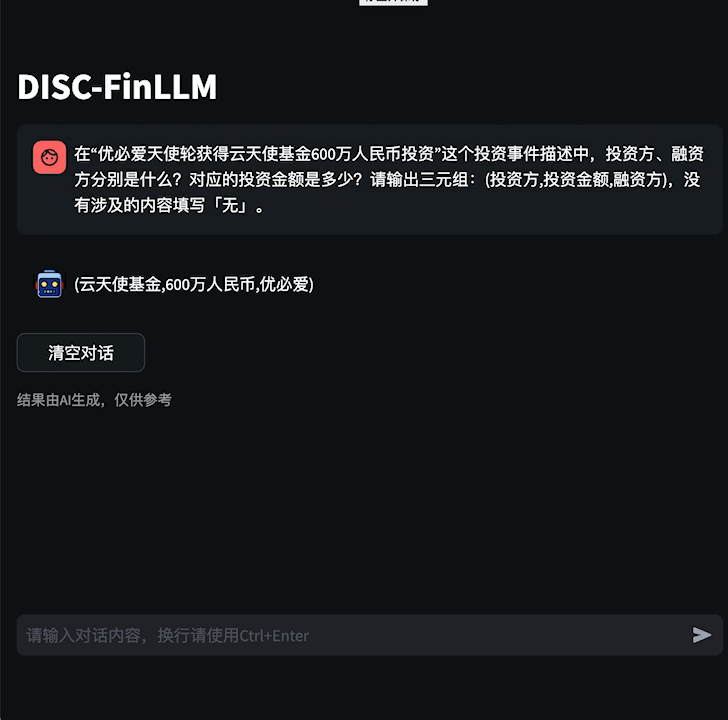
图2 金融文本分析示例
金融文本分析模组可以帮助金融科技领域中的开发者们高效完成各类 NLP 任务,如抽取金融文本中的投资关系、金融实体等信息,以及分析金融新闻、行业评论中的情绪倾向等。

图3 金融计算示例
金融计算模组可以帮助用户完成各类金融领域中的计算任务,如增长率、利率、平均值、BS 公式等,提高金融领域的数据分析效率。

图4 金融检索知识问答示例
在金融知识检索问答模组中,模型将根据用户问题检索最新的新闻、研报、政策文件,紧跟时事热点和政策变动,给出符合国内外的形势发展变化的行业分析、时事分析、政策解读。
2. DISC-FinLLM 介绍
DISC-FinLLM 是基于我们构建的高质量金融数据集 DISC-Fin-SFT 在通用领域中文大模型 Baichuan-13B-Chat 上进行 LoRA 指令微调得到的金融大模型。值得注意的是,我们的训练数据和方法也可以被适配到任何基座大模型之上。
DISC-FinLLM 包含四个 LoRA 模组,它们分别用于实现不同的功能:
1. 金融咨询:该模组可以在中国金融语境下,与用户展开关于金融话题的多轮对话,或是为用户解释金融专业的相关知识,是由数据集中的金融咨询指令部分训练而来。
2. 金融文本分析:该模组可以帮助用户在金融文本上完成信息抽取、情感分析、文本分类、文本生成等 NLP 任务,是由数据集中的金融任务指令部分训练而来。
3. 金融计算:该模组可以帮助用户完成与数学计算相关的任务,除了利率、增长率等基本计算,它还支持统计分析和包括 Black-Scholes 期权定价模型、EDF 预期违约概率模型在内的金融模型计算。这一模组是由数据集中的金融计算指令部分训练而来。
4. 金融知识检索问答:该模组可以检索与用户问题相关的金融新闻、研报和相关政策文件,结合这些检索文档,为用户提供投资建议、时事分析、政策解读。它是由数据集中的检索增强指令部分训练而来。
模型的整体功能框架如图 5 所示。
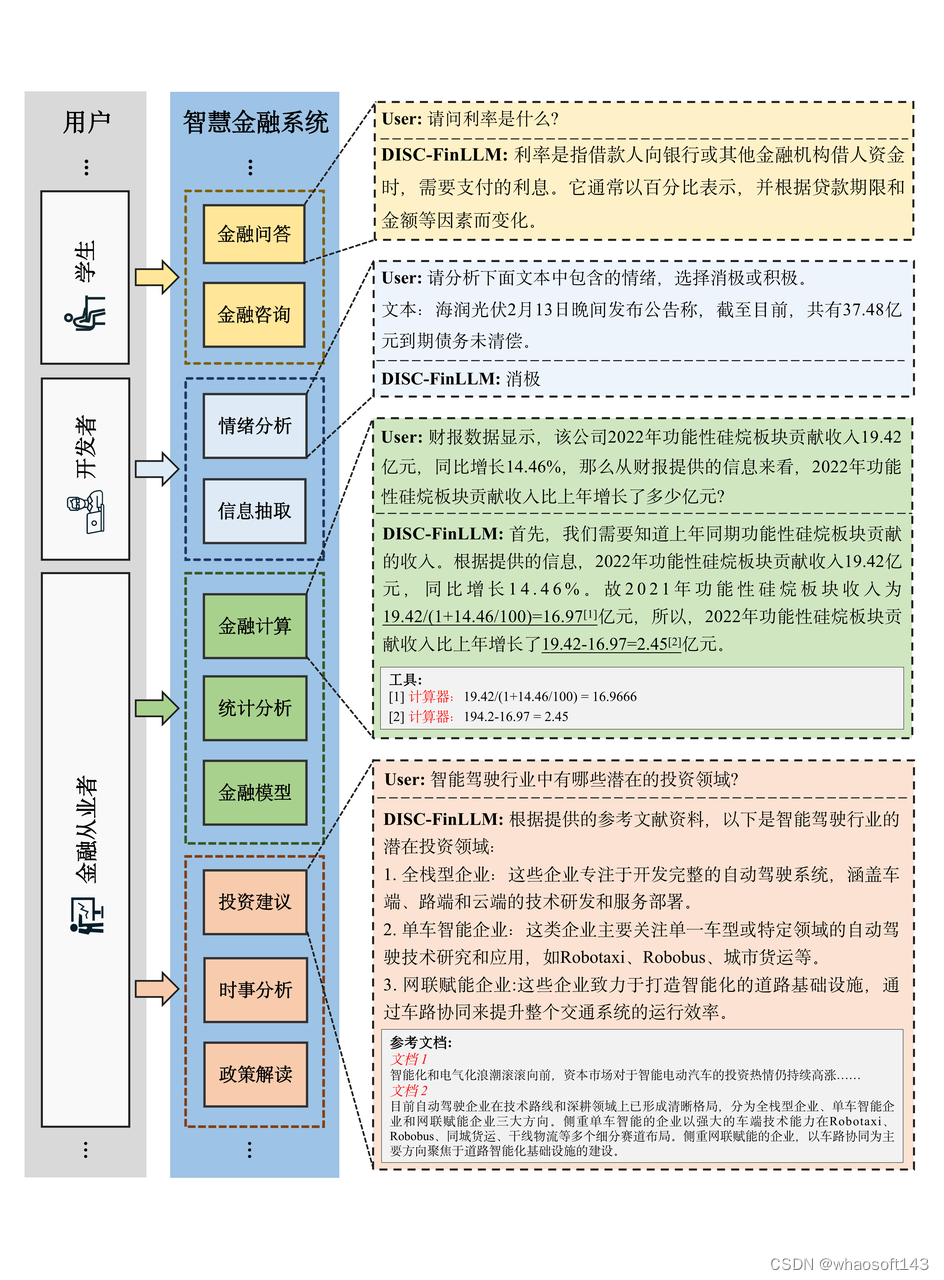
图5 模型在各种金融场景下服务于不同的用户群体
3. 方法:数据集 DISC-Fin-SFT 的构造
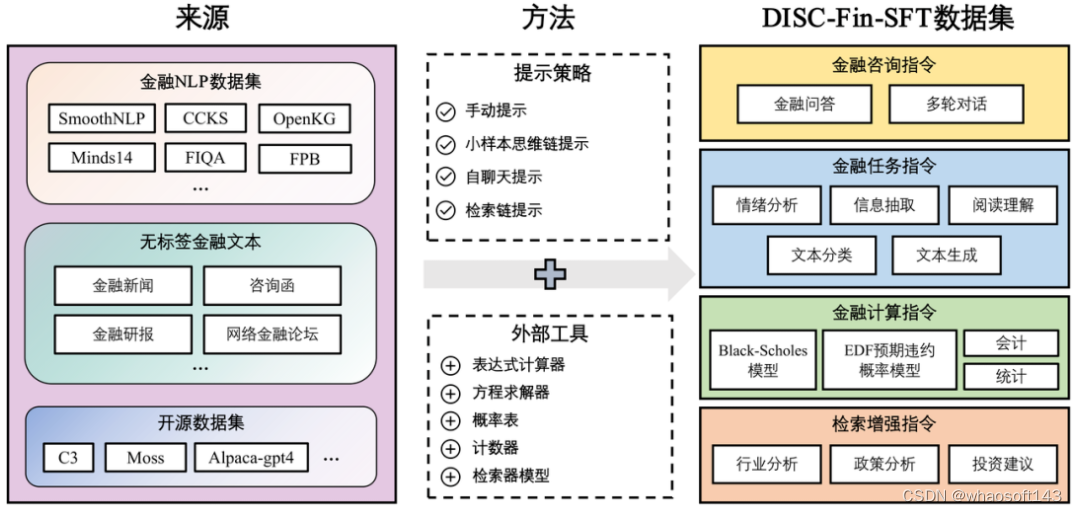
图6 DISC-Fin-SFT数据集的构造过程
DISC-Fin-SFT 数据集总共包含约 25 万条数据,分为四个子数据集,它们分别是金融咨询指令、金融任务指令、金融计算指令、检索增强指令。图 6 展示了数据集的整体构造过程,每个子数据集各有不同的构造方法和提示词(prompt)。表 1 展示了每个部分的构造的数据量和数据长度信息,其中输入和输出长度指的是输入和输出的文本经过分词后的平均词数。
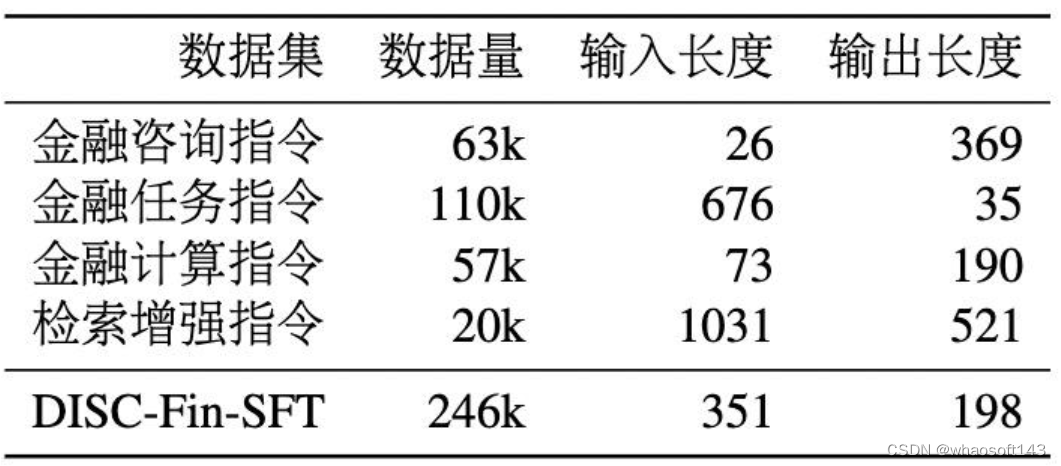
表1 DISC-Fin-SFT数据统计
3.1 金融咨询指令
金融咨询指令数据来源于三部分:
1. FiQA。这是一个英文的金融问答数据集,其中答案部分的质量参差不齐。因此我们将 FiQA 中的所有问题翻译成中文后,使用 ChatGPT 重新生成问题的答案,来提高这一数据集的质量,提示词如图 7 所示,上下文可根据需要选填。

图7 用于构造金融问答指令的零样本提示模板
2. 金融名词解释。我们在网上收集了 200 多个金融领域的专业术语(如:杠杆收购),然后使用图 8 中的提示词,令 ChatGPT 为这些专业词汇生成相应的问答对,用以训练模型对金融用语的理解。

图8 用于构造金融名词问答的小样本提示模板
3. 经管之家论坛上的公开发帖。我们采用自聊天提示(Self-chat Prompting)方法,按照图 9 中的提示词,引导 ChatGPT 围绕帖子主题生成多轮的问答。

图9 用于构造多轮对话指令的零样本提示模板
在以上过程中,我们精心设计的提示词使得 ChatGPT 可以生成符合中国国情、立场、态度和语言风格的问答,这确保 DISC-FinLLM 能够提供符合中国金融语境的咨询服务。
3.2 金融任务指令
金融任务指令数据分为两个部分:
1. 金融 NLP 数据集。该部分是通过手动提示(Manually Prompting)方法,从已有的金融 NLP 数据集改编而来的,图 10 就是一个改编的例子。我们搜集了十余个开源的 NLP 中文数据集,任务上可以分为情绪分析、信息抽取、文本生成、文本分类和翻译等几类。具体的 NLP 数据集信息参看表 2。

图10 用于构造NLP任务指令的零样本和小样本提示模板
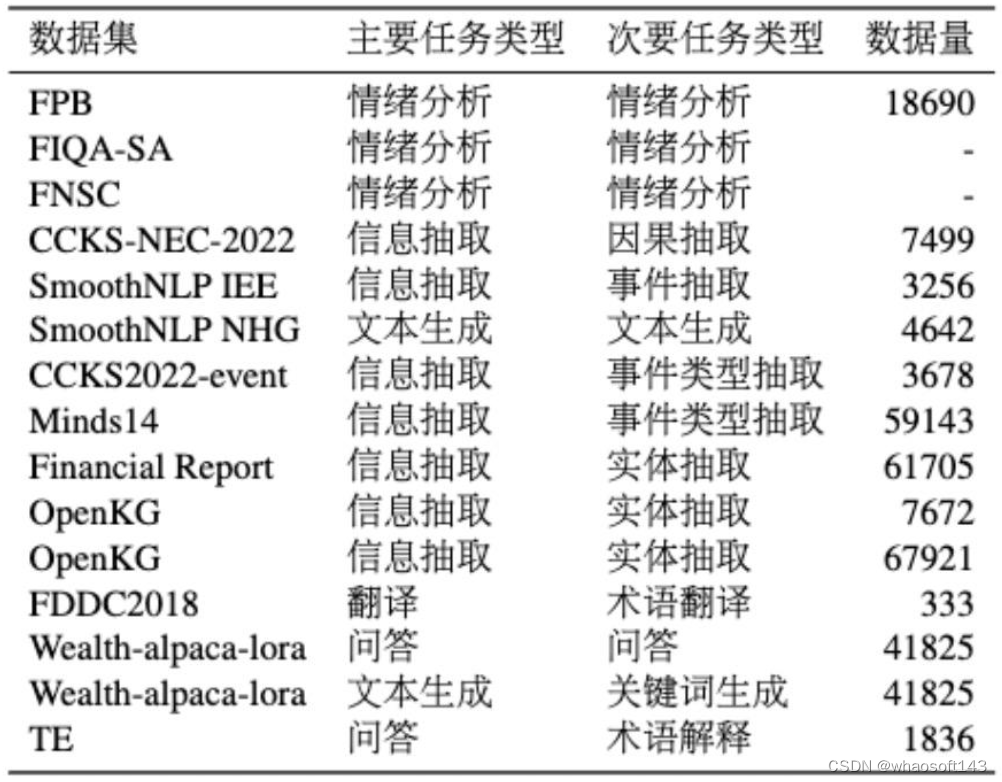
表2 金融NLP数据集统计
2. 金融无标签文本数据集。这是一个金融文本的阅读理解数据集。首先,我们从东方财富网收集了共 87k 个文章,包括金融新闻和研报摘要。然后,基于这些无标签文本中的段落,我们通过图 11 的提示词生成(段落、问题、答案)三元组。最后,将三元组套入不同的指令模板,得到 “输入 - 输出” 指令对。

图11 根据无标签金融文本构造任务指令的提示模板
3.3 金融计算指令
在金融计算中,表达式计算器、方程求解器、概率表、计数器四种工具可以帮助模型完成大多数的计算任务。四种工具的定义如表 3 所示,它们各有不同的调用命令、输入和输出。例如,计算器的命令是 [Calculator (expression)→result]。在这一部分,构建金融计算指令的目的就是训练模型在合适的时候调用这些工具解决数学问题。

表3 计算工具的定义
我们首先构建了一个种子任务库,其中的种子任务由三部分组成:根据金融考试人工改写的计算题、带有研报上下文的数据计算题、BELLE 数据集中校园数学部分的通用数学题。特别地,根据 Toolformer 的方法,这些问题的答案中插入着上述四个工具的调用命令,它们代表着调用工具的方法和时机。随后,为了增加数据的数量和多样性,我们通过小样本思维链提示(Few-shot Chain-of-Thought Prompting)方法,让 ChatGPT 在图 12 中提示词的引导下,根据种子任务生成超过 5 万个新问答对,其中的答案也带有插件命令。

图12 用于构造金融计算指令的提示模板
3.4 检索增强指令
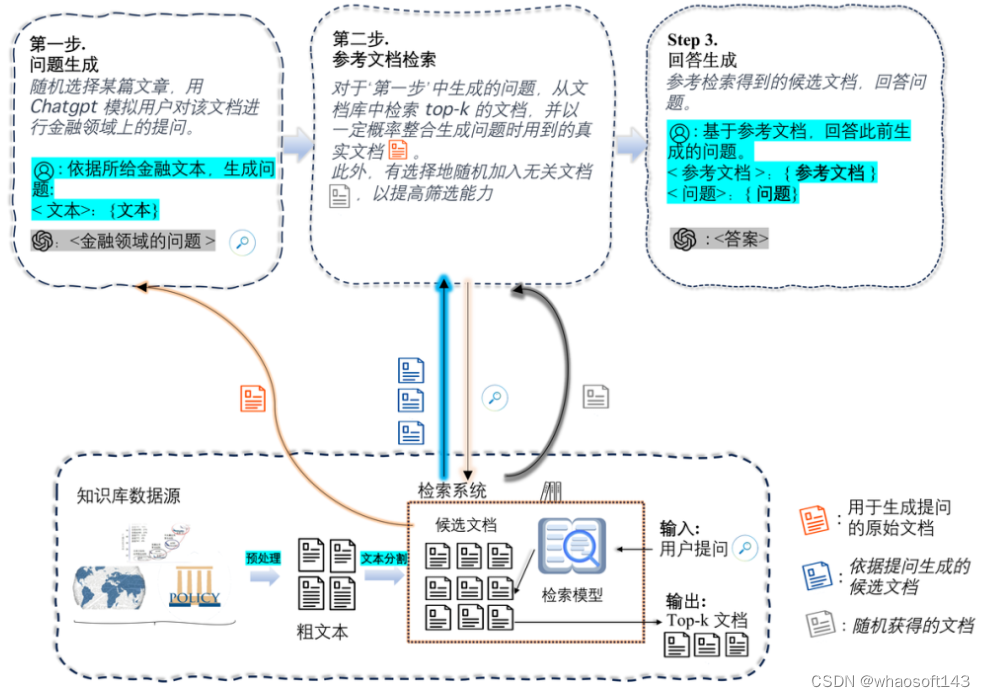
图13 检索增强指令的构造过程
如图 13 所示,检索增强指令的构造分为三步。第一步,我们根据新闻和研报等金融文本构造金融分析问题。第二步,我们在知识库中检索与问题有关的若干文档,并随机加入一些无关文档,以训练模型对有效信息的甄别能力,这些参考文档源于我们构建金融知识库,包含 18k 研报和 69k 金融新闻。第三步,我们将问题和参考资料结合在一起,生成问题的答案。在这个过程中,问题和答案是由 ChatGPT 通过检索链提示(Chain-of-Retrieval Prompting)方法生成的。
最终我们构建了一个包含 20k 条检索增强指令的数据集,其中的指令涵盖了金融领域中主要的分析形式,包括行业分析、政策分析、投资建议、公司战略规划等。
4. 实验
4.1 多专家训练框架
针对金融领域的不同功能,我们采用了多专家微调的训练策略。我们在特定的子数据集上训练模型的各个模组,使它们彼此互不干扰,独立完成不同任务。为此,我们使用 DDP 技术的 Low-rank adaption(LoRA)方法高效地进行参数微调。
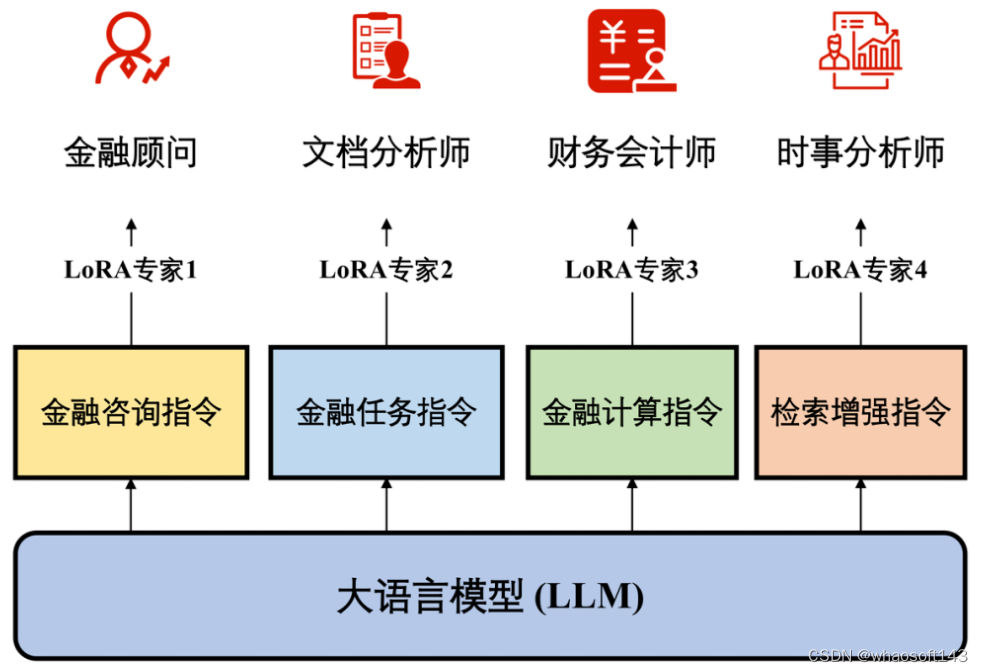
图14 DISC-FinLLM的多专家微调框架
具体来说,我们以 Baichuan-13B 为基座模型,通过数据集的四个部分,分别训练 4 个 LoRA 专家模组,如图 14 所示。部署时,用户只需更换在当前基座上的 LoRA 参数就可以切换功能。因此用户能够根据使用需求激活 / 停用模型的不同模组,而无需重新加载整个模型。4 个 LoRA 专家模组分别如下:
1. 金融顾问:该模型用于多轮对话。由于我们的金融咨询指令数据十分丰富,该模型可以在中国的金融语境下做出高质量的回答,为用户解答金融领域的专业问题,提供优质的咨询服务。
2. 文件分析师:该模型主要用于处理金融自然语言处理领域内的各种任务,包括但不限于金融文本中的信息抽取、情绪分析等。
3. 财务会计师:DISC-FinLLM 支持四种工具,即表达式计算器、方程求解器、计数器和概率表。这些工具支持我们的模型完成金融领域的大多数的计算任务,如金融数学建模、统计分析等。当模型需要使用工具时,它可以生成工具调用命令,然后中断解码,并将工具调用结果添加到生成的文本中。这样,DISC-FinLLM 就可以借助工具提供的准确计算结果,回答金融中的计算问题。
4. 时事分析师:我们在第四个 LoRA 中引入检索插件。DISC-FinLLM 主要参考了三类金融文本:新闻、报告和政策。当用户问及时事、行业趋势或金融政策等常见金融话题时,我们的模型可以检索相关文件,并像金融专家一样展开分析并提供建议。
4.2 评测
我们建立了一个全面的评估框架,从各个角度严格评估我们的模型。该评估框架包括四个不同的组成部分,即:金融 NLP 任务、人类试题、资料分析和时事分析。这一评估框架全面地证明了我们模型能力和训练数据的有效性。
4.2.1 金融 NLP 任务评测
我们使用 FinCUGE 评估基准测试模型处理金融 NLP 任务的能力。我们评估了其中的六项任务,包括情感分析、关系抽取、文本摘要、文本分类、事件抽取和其他任务,它们分别对应着 FinFE、FinQA、FinCQA、FinNA、FinRE 和 FinESE 六个数据集。我们通过提示模板将这个数据集改造为小样本(few-shot)形式,然后使用常用的准确度(Accuracy)、F1 和 Rouge 指标评价模型的表现,来衡量模型在金融领域中理解文本和生成相关回答的能力。
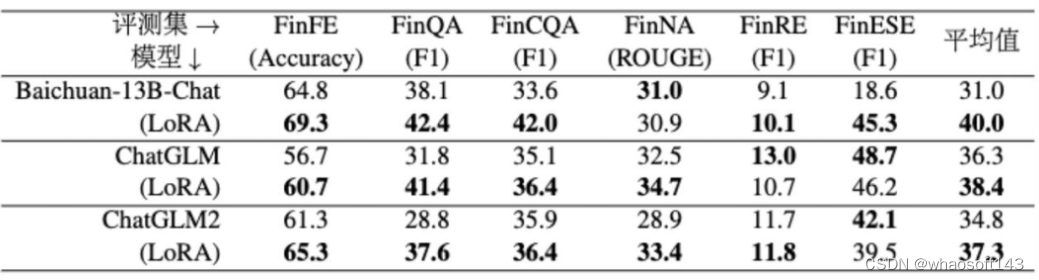
表4 BBT-FIN基准上的实验结果
表 4 中展示的是,使用我们的金融任务指令数据微调不同基线模型前后的评测结果。从 Baichuan-13B-Chat、ChatGLM1 和 ChatGLM2 模型上不难看出,微调后模型的平均成绩比未经训练的基座模型高 2~9 分不等,表现显然更加出色。特别地,我们的数据集没有涵盖评估集中包含的某些 NLP 任务,这更说明我们构建的数据可以有效增强模型金融领域任务中的表现,即使是面对没有训练过的任务的时候
4.2.2 人类试题评测
我们使用了 FIN-Eval 基准评估模型在回答真人生成问题上的能力,这个基准涵盖了金融、经济、会计、证书等学科的高质量多项选择题。我们以准确度为指标,来衡量模型的表现。
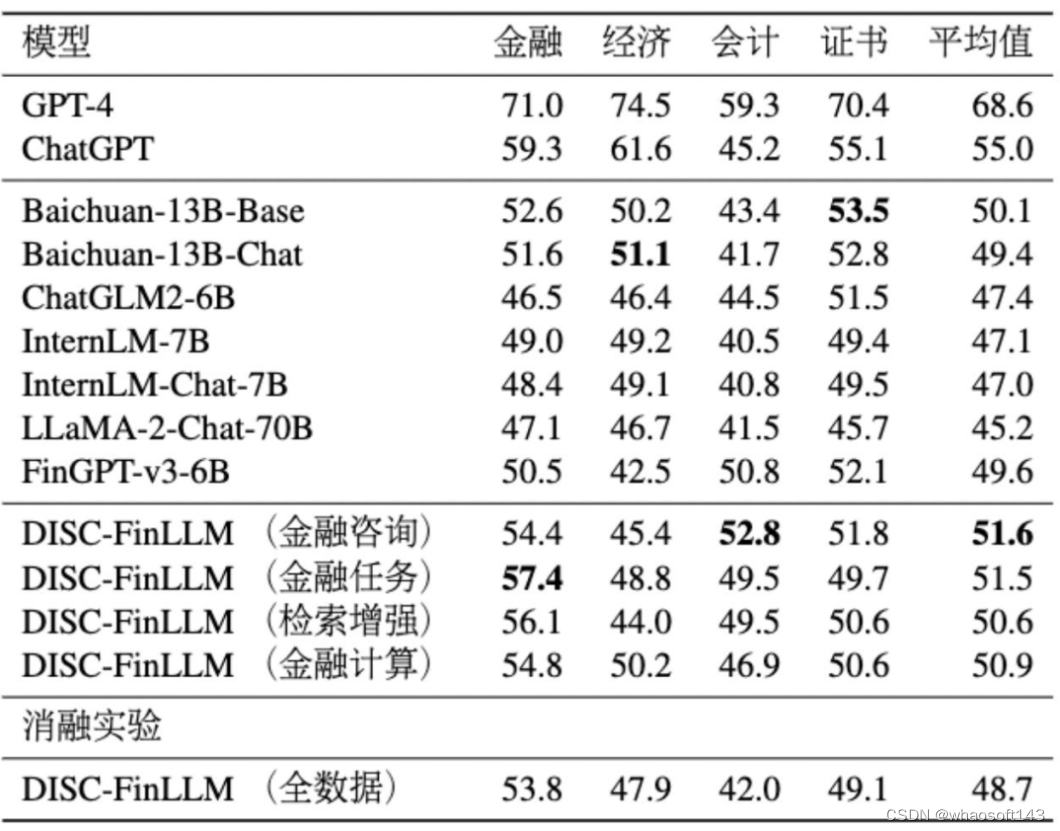
表5 FIN-Eval基准上的实验结果
我们对四个 LoRA 微调模型,和使用 DISC-Fin-SFT 全体数据微调的模型都进行了测试,比较模型包括 ChatGPT、GPT-4、Baichuan、ChatGLM2、FinGPT-v3 等。表 5 展示了各个模型在人类试题评测中的结果。相比之下,我们模型的平均结果仅次于 ChatGPT 和 GPT-4。与未经训练的 Baichuan-13B-Chat 模型相比较看,DISC-Fin-SFT 中的每一类指令,都有助于提高模型在人类试题评测上能力。从 FinGPT 的测评结果看,我们也比其他的金融大模型表现要好。从消融实验看,在 Baichuan-13B-Chat 模型上使用全部数据集微调后,获得的评测结果显著下降,这体现了对每个任务使用特定数据的 LoRA 微调的必要性。
4.2.3 资料分析评测
我们手动构造了一个由 100 个财经计算题组成的数据集,用于评估模型在计算任务中的能力。这些测评问题改编自中国行政职业能力测验中的材料分析计算题,包括计算同比增长率和产值比例等。我们根据模型给出计算公式和计算结果的正确率来评估模型的表现。
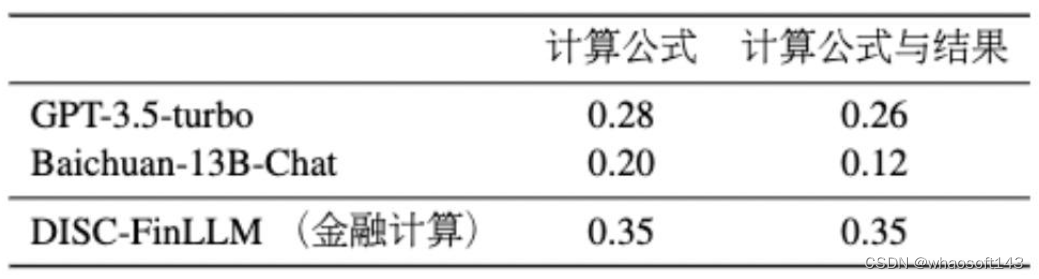
表6 计算插件的评估结果
表 6 展示了我们模型在计算任务方面取得的显著改进。与基线模型相比,我们的模型中添加了计算插件,显著提高了性能,评测结果超过 ChatGPT 0.09 分,突出了我们的方法在解决金融计算问题上的有效性。
4.2.4 时事分析评测
此方法基于 GPT-3.5 模型作出评估。我们构建了一个金融问题数据集,其中的问题需要模型使用最新信息来获得准确答案。然后我们在谷歌等搜索引擎中手动搜索与每个问题相关的多个参考文段。该数据集旨在评估出模型在回答金融问题时检索信息的相关性和准确性,我们用四个指标评价模型的表现:
1. 准确性:提供的建议或分析是准确的,没有事实错误(假设参考文本是正确的),结论不是随意给出的。
2. 实用性:模型可以结合参考文本,对金融领域的问题提供清楚、实用的分析。
3. 语言质量:模型可以正确理解问题,并在金融领域产生简洁、专业的答案。
4. 思考性:模型根据参考文献,由自己的思考分析得出结论,而不是简单地抄袭原文。

表7 检索插件的评估结果
表 7 表明我们模型的评测结果在所有指标上都明显更高,证明了检索增强指令数据训练为模型带来了明显的优势。
5. 总结
我们基于多专家微调框架构建了一个强大的中文智慧金融系统 ——DISC-FinLLM。我们根据四种特定任务的指令数据微调我们的模型,分别训练了四个面向不同金融场景的专家模组:金融咨询、金融文本分析、金融计算、金融知识检索问答,以提高其在金融 NLP 任务、人类试题、计算任务和检索任务中的性能。同时,我们的评估结果证明了我们模型在金融领域的可靠性。DISC-FinLLM 为大语言模型在金融咨询、投资分析和风险评估上的应用开辟了可能性,将为更为广泛的用户群体带来高效、可靠的金融服务支持。
#数据集分享3~
涵盖了水下图像视频、阴影去除、目标检测、跟踪分割、交互、超分辨率等领域。
视频背景音乐合成数据集
Video Background Music Generation: Dataset, Method and Evaluation
为了解决在编辑视频时可以根据视频输入自动生成背景音乐曲目,避免手动选择音乐时的耗时耗费。
本文介绍了一套完整的视频背景音乐生成方法,包括数据集、基准模型和评估指标。
其中,SymMV 是一个包含各种音乐标注的视频和符号音乐数据集。作者称,这是第一个具有丰富音乐标注的视频音乐数据集。
另外,V-MusProd 基准模型,利用了和弦、旋律和伴奏等音乐先验知识,结合了视频-音乐的语义、颜色和运动等特征关系,用于生成视频背景音乐。
为了解决视频音乐对应关系缺乏客观衡量标准的问题,设计一种基于检索的衡量标准 VMCP,它建立在一个强大的视频音乐表征学习模型之上。
实验表明,使用SymMV数据集,V-MusProd 在音乐质量和视频对应性方面都优于最先进的方法。
- 论文链接:https://arxiv.org/abs/2211.11248
- 项目链接(待):https://github.com/zhuole1025/SymMV
DiLiGenT-Pi
DiLiGenT-Pi: Photometric Stereo for Planar Surfaces with Rich Details - Benchmark Dataset and Beyond
DiLiGenT-Π 是一个新的真实世界数据集,旨在填补在光度立体照相技术中缺乏对富含细节的近平面表面的现实世界数据集的空白。包含了 30 个具有丰富表面细节的近平面物体。
- 论文链接:https://photometricstereo.github.io/imgs/diligentpi/paper.pdf
- 项目链接(开源):https://photometricstereo.github.io/diligentpi.html
水下视频数据集
Self-supervised Monocular Underwater Depth Recovery, Image Restoration, and a Real-sea Video Dataset
DRUVA(Dataset of Real-world Underwater Videos of Artifacts)是一个用于深海水域的真实世界水下视频数据集。包含 20 个不同文物(主要是尺寸为 0.5 米至 1 米的水下岩石)在浅水区的视频序列。每个文物一个视频,时长约 1 分钟,包含文物在距离摄像机 0.5 米至 4 米深处的近 360 ◦方位视角。
DRUVA 可供水下(UW)研究人员用于三维重建、使用神经辐射场(NeRFs)进行新型视图合成、视频插值和 extrapolation(外推法)等。
- 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Varghese_Self-supervised_Monocular_Underwater_Depth_Recovery_Image_Restoration_and_a_Real-sea_ICCV_2023_paper.pdf
- 项目链接:https://github.com/nishavarghese15/DRUVA

水生物数据集
FishNet: A Large-scale Dataset and Benchmark for Fish Recognition, Detection, and Functional Traits Prediction
FishNet 是一个大规模多样化的数据集,包含了来自 17357 种水生物的 94532 张精心整理的图像。这些图像根据水生物的生物分类学(目、科、属、种)进行了组织。旨在满足对能够识别、定位和预测物种及其功能特征的系统需求。
- 论文链接:https://openaccess.thecvf.com//content/ICCV2023/html/Khan_FishNet_A_Large-scale_Dataset_and_Benchmark_for_Fish_Recognition_Detection_ICCV_2023_paper.html
- 项目链接:https://fishnet-2023.github.io/
视觉与语言
Lecture Presentations Multimodal Dataset: Towards Understanding Multimodality in Educational Videos
Lecture Presentations Multimodal (LPM) Dataset是一个大规模的数据集,旨在作为测试视觉与语言模型在多模态理解教育视频方面能力的基准。该数据集包含了对齐的幻灯片和口头语言,涵盖了180多小时的视频和9000多张幻灯片,涉及来自不同学科(如计算机科学、牙科、生物学)的10名讲师。
- 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Lee_Lecture_Presentations_Multimodal_Dataset_Towards_Understanding_Multimodality_in_Educational_Videos_ICCV_2023_paper.pdf
- 项目链接(开源):https://github.com/dondongwon/LPMDataset
手部姿势
RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation
RenderIH是一个大规模的合成数据集,旨在提供准确和多样化的姿势标注,以用于交互手部研究。该数据集包含了100万张照片逼真的图像,具有各种不同的背景、视角和手部纹理。
在本次任务中,为了生成自然且多样化的交互姿势,提出一种新的姿势优化算法。以及为了提高姿势估计的准确性,引入基于Transformer的姿势估计网络TransHand,以利用交互手部之间的相关性,并验证了RenderIH在提升结果方面的有效性。
实验证明,在合成数据上进行预训练可以显著将误差从6.76mm降低到5.79mm,而TransHand超越了现有方法。
- 论文链接:https://arxiv.org/abs/2309.09301
- 项目链接(开源):https://github.com/adwardlee/RenderIH

超分辨率
A Large-Scale Multi-Reference Dataset for Reference-based Super-Resolution
LMR(Large-scale Multi-Reference)是一个大规模的多参考图像超分辨率(RefSR)数据集。包含 112,142 组300x300 的训练图像,是现有最大的 RefSR 数据集的 10 倍。图像的尺寸也大得多。更重要的是,每组图像配备了 5 个不同相似度级别的参考图像。
另外,提出一种新的多参考超分辨率基准方法:MRefSR,包括一个用于任意数量参考图像特征融合的多参考关注模块(MAM)和一个用于融合特征选择的空间感知过滤模块(SAFM)。
MRefSR 在定量和定性评估方面都比最先进的方法有显著改进。
- 论文链接:https://arxiv.org/abs/2303.04970
- 项目链接(待):https://github.com/wdmwhh/MRefSR

目标跟踪
360VOT: A New Benchmark Dataset for Omnidirectional Visual Object Tracking
360VOT 是一个新的大规模全景追踪基准数据集,旨在为全景视觉物体追踪提供支持。这个数据集包含了 120 个序列,总计超过 11.3 万张高分辨率帧,采用等距投影。追踪的目标涵盖了 32 个不同的类别,场景多样。
此外,还提供了 4 种无偏差的ground truth,包括(旋转)边界框和(旋转)边界视场,以及为 360° 图像量身定制的新指标,从而可以准确评估全景跟踪性能。
- 论文链接:https://arxiv.org/abs/2307.14630
- 项目链接(开源):https://360vot.hkustvgd.com/

细粒度物体理解
EgoObjects: A Large-Scale Egocentric Dataset for Fine-Grained Object Understanding
EgoObjects 是一个大规模的主观视角数据集,旨在进行细粒度物体理解,该领域被认为是主观视角视觉的一个基础研究课题。其试验版本包含了来自 50 多个国家的 250名参与者使用 4 种可穿戴设备收集的超过 9,000 个视频,以及来自 368 个物体类别的超过 650,000 个物体标注。与先前的数据集不同,EgoObjects 不仅仅包含了物体类别标签,还为每个物体提供了实例级别的标识,并包括了超过 14,000 个独特的物体实例。whaosoftの开发板商城aiot物联网设备
- 论文链接:https://arxiv.org/abs/2309.08816
- 项目链接:https://github.com/facebookresearch/EgoObjects

城市建模
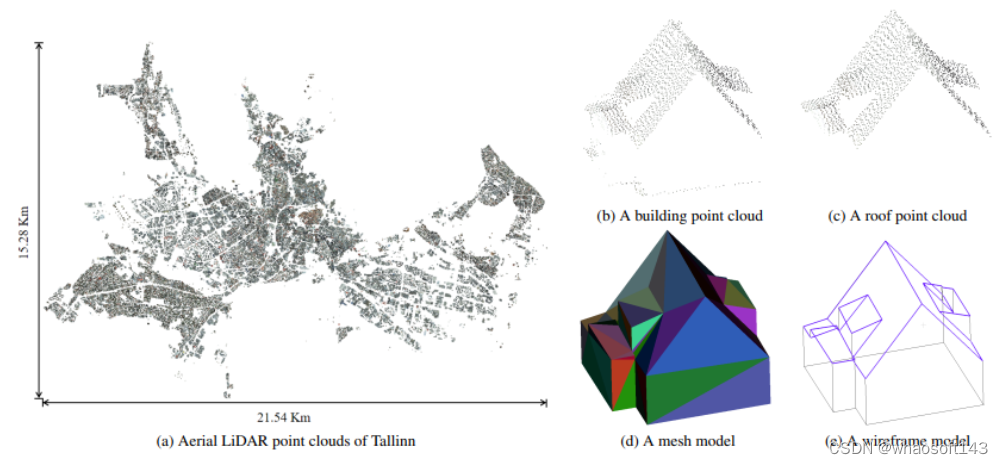
Building3D: A Urban-Scale Dataset and Benchmarks for Learning Roof Structures from Point Clouds
Building3D 是一个城市尺度数据集,用于利用航空激光雷达点云进行建筑物屋顶建模。它包括超过16万栋建筑物,覆盖了Estonia 的16个城市,总计约998平方公里。除了网格模型和真实世界LiDAR点云外,这是首次发布线框模型。Building3D 将促进未来在城市建模、航空路径规划、网格简化和语义/部件分割等方面的研究。
- 论文链接:https://arxiv.org/abs/2307.11914
- 项目链接(开源):https://building3d.ucalgary.ca/
美学评估数据集
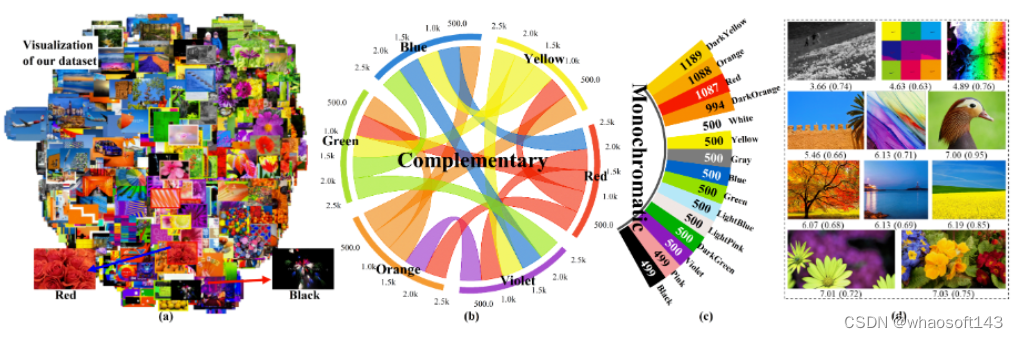
Thinking Image Color Aesthetics Assessment: Models, Datasets and Benchmarks
首个面向图像【色彩】的美学评估数据集,1万7千张左右图像,按色彩搭配的类型进行标注。
- 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/He_Thinking_Image_Color_Aesthetics_Assessment_Models_Datasets_and_Benchmarks_ICCV_2023_paper.pdf
- 项目链接:https://github.com/woshidandan/Image-Color-Aesthetics-Assessment
文档去除阴影
High-Resolution Document Shadow Removal via A Large-Scale Real-World Dataset and A Frequency-Aware Shadow Erasing Net
SD7K 是一个用于高分辨率文档去除阴影的大规模实际世界数据集。它包括了超过7,000对高分辨率(2462 x 3699)的真实世界文档图像,这些图像来自不同光照条件下的各种样本。相比现有的数据集,这个数据集的规模大了10倍。
- 论文链接:https://arxiv.org/abs/2308.14221
- 项目链接(开源):https://github.com/CXH-Research/DocShadow-SD7K

合成视觉数据集(XAI)
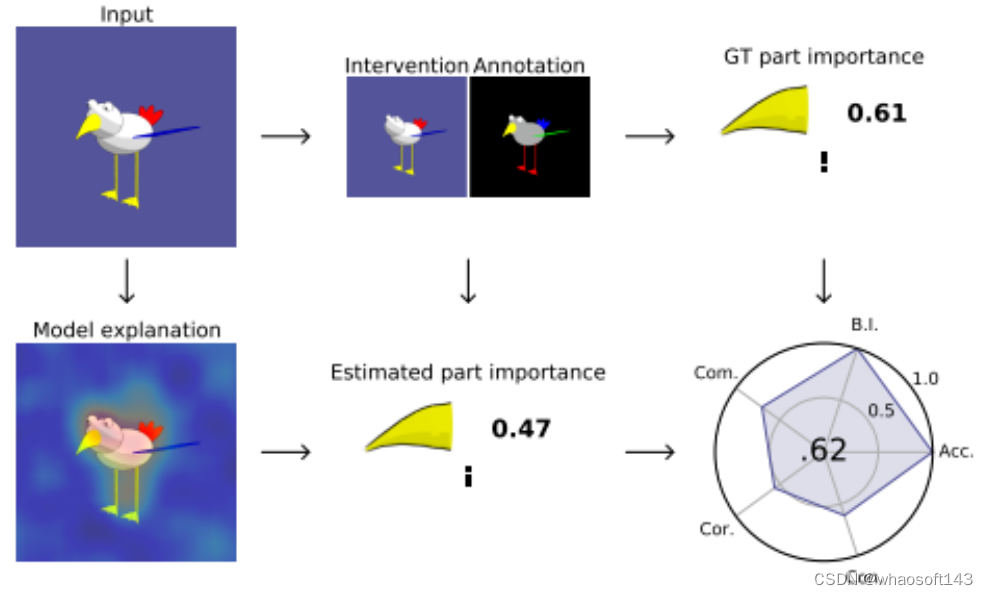
FunnyBirds: A Synthetic Vision Dataset for a Part-Based Analysis of Explainable AI Methods
FunnyBirds 是一个新的合成视觉数据集,旨在支持可解释人工智能(XAI)研究。该数据集解决了XAI领域中一个尚未解决的问题,即如何自动评估解释的质量,因为XAI缺乏ground-truth解释。FunnyBirds数据集允许进行语义上有意义的图像干预,例如移除个体对象的部分,这具有三个重要的影响:
首先,它使得可以在部分层面上分析解释,这比现有方法在像素级别上评估更接近人类理解。
其次,通过比较对移除部分的输入的模型输出,可以估计出应该在解释中反映的ground-truth部分重要性。
第三,通过将个体解释映射到一个共同的部分重要性空间,可以在一个统一的框架中分析各种不同类型的解释。
利用这些工具,研究者们对24种不同组合的神经模型和XAI方法进行了评估,以全自动和系统化的方式展示了评估方法的优缺点。
- 论文链接:https://arxiv.org/abs/2308.06248
- 项目链接:https://github.com/visinf/funnybirds
主观视角人际互动数据集
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
HoloAssist是一个大规模的主观视角人际互动数据集,旨在为开发可以在物理世界中与人类互动的智能代理提供支持。在这个数据集中,两名参与者共同完成物理操作任务。任务执行者戴着混合现实头戴式设备,可以捕捉到七个同步的数据流。任务指导者实时观看执行者的主观视角视频,并通过口头指导来引导他们完成任务。HoloAssist 的数据采集时间长达 169 个小时,采集对象包括 350 对不同的指导者和执行者。
- 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Wang_HoloAssist_an_Egocentric_Human_Interaction_Dataset_for_Interactive_AI_Assistants_ICCV_2023_paper.pdf
- 项目链接:https://holoassist.github.io/

三维全身姿态
H3WB: Human3.6M 3D WholeBody Dataset and Benchmark
Human3.6M 3D WholeBody (H3WB)数据集使用 COCO Wholebody 布局为 Human3.6M 数据集提供全身标注。H3WB 包括 100K 幅图像上的 133 个全身关键点标注,得益于新开发的多视图处理流程。
在本次任务中,还提出了三项任务:
- 从二维完整全身姿态提取三维全身姿态;
- 从二维不完整全身姿态提取三维全身姿态;
- 从单张 RGB 图像估算三维全身姿态。
此外,还针对这些任务报告了几种常用方法的基线。以及提供了 TotalCapture 的自动三维全身标注,实验表明,与 H3WB 配合使用有助于提高性能。
- 论文链接:https://arxiv.org/abs/2211.15692
- 项目链接:https://github.com/wholebody3d/wholebody3d
热红外盲道分割
Atmospheric Transmission and Thermal Inertia Induced Blind Road Segmentation with a Large-Scale Dataset TBRSD
TBRSD(Thermal Blind Road Segmentation Dataset)是一个用于热红外盲道分割的大规模数据集。该数据集的目的是为了训练和评估热红外图像分割模型,以增强计算机视觉辅助盲人行走系统的安全性。数据集中包含了5180个像素级别的手动标注,用于指示图像中盲道的位置。
- 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Chen_Atmospheric_Transmission_and_Thermal_Inertia_Induced_Blind_Road_Segmentation_with_ICCV_2023_paper.pdf
- 项目链接:https://xzbai.buaa.edu.cn/datasets.html
视觉目标检测
V3Det: Vast Vocabulary Visual Detection Dataset
V3Det是一个用于视觉目标检测的大规模词汇视觉检测数据集,具有精确标注的大规模图像边界框。该数据集具有以下吸引人的特点:
- 词汇量大: V3Det包含来自13,204个类别的真实世界图像上的物体边界框,比现有的大规模词汇目标检测数据集(如LVIS)大10倍。
- 分层类别组织: V3Det的广泛词汇通过一个分层类别树组织,该树标注了类别之间的包含关系,鼓励在广泛和开放词汇的目标检测中探索类别关系。
- 丰富的标注: V3Det包括在243,000张图像中精确标注的物体,以及由人类专家和强大的聊天机器人编写的每个类别的专业描述。
通过提供广泛的探索空间,V3Det可以在广泛和开放词汇的目标检测方面进行广泛的基准测试,从而为未来研究提供新的观察、实践和见解。
- 论文链接:https://arxiv.org/abs/2304.03752
- 项目链接:https://v3det.openxlab.org.cn/

海上全景障碍物检测
LaRS: A Diverse Panoptic Maritime Obstacle Detection Dataset and Benchmark
LaRS(Lakes, Rivers and Seas)是一个用于海上全景障碍物检测的基准数据集。它旨在弥补海上障碍物检测领域缺乏多样性数据集的问题,以充分捕捉一般海上环境的复杂性。
LaRS 包括了超过 4000 帧的关键帧,每个帧都进行了逐像素标注,还包括了前面的九帧以利用时间纹理,总计超过 40,000 帧。每个关键帧都标注了 11 个物体和物质类别以及 19 个全局场景属性。
- 论文链接:https://arxiv.org/abs/2308.09618
- 项目链接(开源):https://lojzezust.github.io/lars-dataset/

360°全景图像数据集
Beyond the Pixel: a Photometrically Calibrated HDR Dataset for Luminance and Color Prediction
Laval Photometric Indoor HDR Dataset 是第一个大规模的光度校准的高动态范围(HDR)360°全景图像数据集。
- 论文链接:https://arxiv.org/abs/2304.12372
- 项目链接:https://lvsn.github.io/beyondthepixel/

珍稀动物数据集
LoTE-Animal: A Long Time-span Dataset for Endangered Animal Behavior Understanding
LoTE-Animal(Large-scale Endangered Animal Dataset)是一个为了促进深度学习在珍稀物种保护中的应用而收集的大规模珍稀动物数据集,历时12年。
数据集包含了丰富的变化,如生态季节、天气条件、时间段、视角和栖息地场景。到目前为止,已经收集到了至少50万个视频和120万张图像。其中选择并标注了11种濒危动物以进行行为理解,包括1万个视频序列用于动作识别任务,2.8万张图像用于目标检测、实例分割和姿态估计任务。此外,还收集了7千张同一物种的网络图像作为源域数据,用于域自适应任务。
- 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Liu_LoTE-Animal_A_Long_Time-span_Dataset_for_Endangered_Animal_Behavior_Understanding_ICCV_2023_paper.pdf
- 项目链接:https://lote-animal.github.io/

6DoF
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Aria Digital Twin (ADT)是一个使用Aria眼镜捕获的以自我为中心的数据集,包含大量物体、环境和人类层面 ground-truth 的数据。
ADT 包含 Aria 佩戴者在两个真实室内场景中进行的 200 个真实世界活动序列,其中有 398 个对象实例(324 个静态和 74 个动态)。每个序列包括:
- 两个单色摄像头流、一个 RGB 摄像头流和两个 IMU 流的原始数据;
- 完整的传感器校准;
- ground-truth 数据,包括 Aria 设备的连续 6 自由度 (6DoF) 姿态、物体 6DoF 姿态、三维眼球注视矢量、三维人体姿态、二维图像分割、图像深度图;
- 照片般逼真的合成渲染。
- 论文链接:https://arxiv.org/abs/2306.06362

#腾讯优图实验室~论文5
文章为腾讯优图实验室入选论文概览,内容涵盖图文多模态大模型、高分辨视觉分割、跨模态生成、人脸识别等多个研究方向。 20篇论文~多模态大模型、医学影像、人脸和OCR等方向
近日,CVPR 2024 (IEEE Conference on Computer Vision and Pattern Recognition) IEEE国际计算机视觉与模式识别会议公布了论文录用结果。
作为全球计算机视觉与模式识别领域的顶级会议,CVPR每年都吸引着全球众多研究者和企业的关注。入选CVPR的论文需要经过严格的评审流程,确保其创新性和实用性达到国际领先水平。
今年,腾讯优图实验室共有20篇论文入选,内容涵盖图文多模态大模型、高分辨视觉分割、跨模态生成、人脸识别等多个研究方向,展示了腾讯优图实验室在人工智能领域的长期技术积累和研究实力。
以下为入选论文概览:
01 在图文多模态大模型中使用对比学习来增强视觉文档理解
Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models
Xin Li*, Yunfei Wu*, Xinghua Jiang, Zhihao Guo, Mingming Gong, Haoyu Cao, Yinsong Liu, Deqiang Jiang, Xing Sun
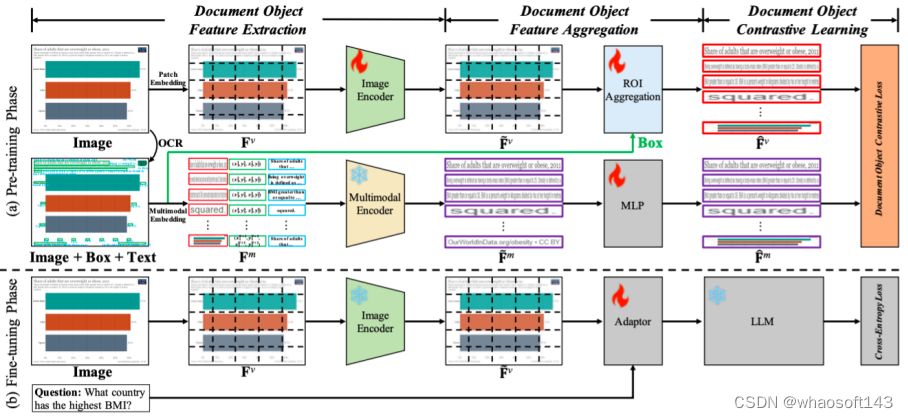
近期,图文多模态大模型(LVLMs)的出现在各个领域引起了越来越多的关注,特别是在视觉文档理解(VDU)领域。与传统的视觉-语言任务不同,VDU特别关注包含丰富文档元素的文本丰富场景。然而,细粒度特征的重要性在LVLMs社区内仍未被充分探索,导致在文本丰富场景中的性能不尽如人意。在这篇论文中,我们将其简称为细粒度特征崩溃问题。为了填补这个空白,我们提出了一个对比学习框架,名为文档对象对比学习(DoCo),专门为VDU的下游任务量身定制。DoCo利用一个辅助的多模态编码器获取文档对象的特征,并将它们与LVLM的视觉编码器生成的视觉特征对齐,从而在文本丰富场景中增强视觉表示。这可以表明,视觉整体表示和文档对象的多模态细粒度特征之间的对比学习可以帮助视觉编码器获取更有效的视觉线索,从而增强LVLMs对文本丰富文档的理解。我们还证明了所提出的DoCo可以作为一个即插即用的预训练方法,可以在各种LVLMs的预训练中使用,而不会在推理过程中增加任何计算复杂性。在多个VDU基准测试的广泛实验结果显示,配备我们提出的DoCo的LVLMs可以实现优越的性能,并缩小VDU和通用视觉-语言任务之间的差距。
论文链接:
https://arxiv.org/pdf/2402.19014
02 基于可学习残差表示的隐私保护人脸识别方法
Privacy-Preserving Face Recognition Using Trainable Feature Subtraction
Yuxi Mi (Fudan University), Zhizhou Zhong (Fudan University), Yuge Huang, Jiazhen Ji, Jianqing Xu, Jun Wang, ShaoMing Wang, Shouhong Ding, Shuigeng Zhou (Fudan University)
本文由腾讯优图实验室、腾讯微信支付33号实验室、复旦大学共同完成
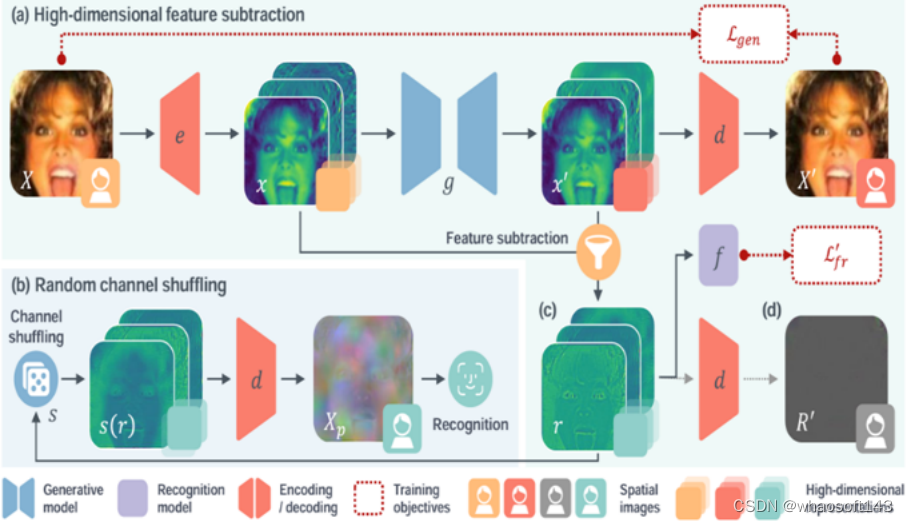
人脸面部图像中存在重要的视觉特征,在使用和共享中需加以保护。本文提出一种新的隐私保护人脸识别方法,MinusFace,将面部图像转换为隐藏外观、同时可识别的图像域保护表示。本文观察到图像有损压缩技术中,原始与压缩图像相减所得残差表示,具备不包含视觉特征,同时描述原始图像的性质。受此启发,本文提出了表示相减方法:训练一对生成和识别模型,将原始图像与其经生成模型重新合成的图像相减获得可学习的残差表示,作为识别模型输入。协同训练两个模型,减少残差表示中的视觉特征,同时保留识别信息。本文进一步采用高维空间映射和通道顺序变换技术,以改善残差表示的隐私性和识别效果。广泛实验表明MinusFace可以取得当前先进水平的人脸识别准确率和隐私保护效果,同时较既往方法显著压缩保护表示大小。
03 高分辨率视觉文档助手
HRVDA: High-Resolution Visual Document Assistant
Chaohu Liu(USTC), Kun Yin,Haoyu Cao, Xinghua Jiang, Xin Li, Yinsong Liu, Deqiang Jiang, Xing Sun, Linli Xu(USTC )
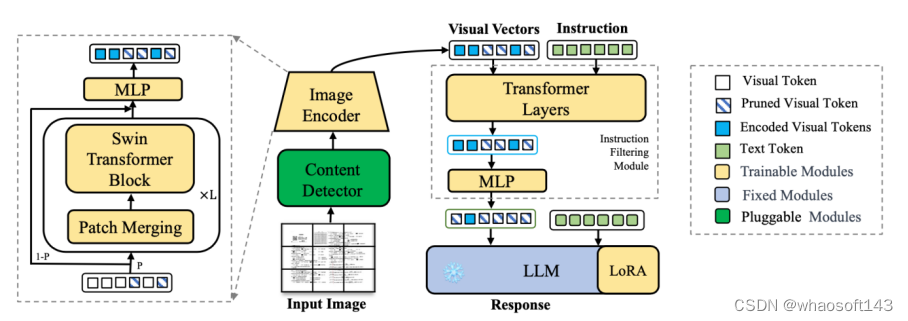
多模态大型语言模型(MLLMs)展示了强大的通用视觉理解能力,并在各种任务中取得了显著的性能,然后常见的多模态大预言模型只能处理低分辨率图片。低图像分辨率可能导致大量图像信息的丢失,从而导致模型性能下降。此外,通用的MLLMs在处理文档特定指令方面表现不佳。在本文中,我们提出了一种高分辨率视觉文档助手(HRVDA),它弥合了MLLMs和视觉文档理解之间的差距。该模型采用内容过滤机制和指令过滤模块,分别过滤出与内容无关的视觉标记和与指令无关的视觉标记,从而有效地实现模型的训练和推理。此外,我们构建了一个文档特定的指令调整数据集,并应用多阶段训练策略来增强模型的文档建模能力。大量实验证明,我们的模型在多个文档理解数据集上实现了最先进的性能,同时保持了与主流低分辨率模型相当的训练效率和推理速度。
04 深度神经网络模型的数据可用性攻击方法
Re-thinking Data Availablity Attacks Against Deep Neural Networks
Bin Fang(Shanghai Jiao Tong University), Bo Li, Shuang Wu, Shouhong Ding, Ran Yi(Shanghai Jiao Tong University), Lizhuang Ma(Shanghai Jiao Tong University)

未经授权使用个人数据进行商业目的以及为训练机器学习模型而秘密获取私人数据的行为持续引发关注。为解决这些问题,业界提出了可用性攻击,旨在使数据不可被随便利用。然而,许多可用性攻击方法容易受到对抗性训练的干扰。尽管一些强大的方法可以抵抗对抗性训练,但其保护效果有限。在本文中,我们重新审视现有的可用性攻击方法,并提出一种新颖的两阶段最小-最大-最小优化范式来生成强大的不可学习噪声。内部最小阶段用于生成不可学习噪声,而外部最小-最大阶段模拟了被对抗攻击模型的训练过程。此外,我们对攻击效果进行了量化定义,并将其用于约束优化目标。综合实验表明,与现有技术相比,我们的方法生成的噪声可以使经过对抗性训练的被攻击的模型的测试精度降低约30%。我们的方法为该领域的未来研究奠定了基础。
05 Real-IAD: 用于多种工业异常检测算法评估的多视角真实场景数据集
Real-IAD: A Real-World Multi-view Dataset for Benchmarking Versatile Industrial Anomaly Detection
Chengjie Wang, Wenbin Zhu (Fudan Univesity, Roogcheer Industrial Tech), Binbin Gao, Zhenye Gan, Jiangning Zhang, Zhihao Gu(Shanghai Jiao Tong University), Shuguang Qian (Roogcheer Industrial Tech), Mingang Chen (Shanghai Development Center of Computer Software Technology), Lizhuang Ma(Shanghai Jiao Tong University)

工业异常检测(IAD)已经引起了重大关注,并经历了快速的发展。然而,由于数据集限制,最近的IAD方法的发展遇到了一些困难。一方面,大多数最先进的方法在主流数据集(如MVTec)上已经达到了饱和(在AUROC中超过99%),方法之间的差异无法很好地区分,导致公共数据集与实际应用场景之间存在显著的差距。另一方面,由于数据集规模的限制,对各种新的实用异常检测设置的研究存在过拟合的风险。因此,我们提出了一个大规模、真实世界和多视角的工业异常检测数据集,名为Real-IAD,它包含了30种不同对象的150K高分辨率图像,比现有的数据集大一个数量级。它具有更大范围的缺陷面积和比例,使其比以前的数据集更具挑战性。为了使数据集更接近实际应用场景,我们采用了多视角拍摄方法,并提出了样本级评估指标。此外,除了一般的无监督异常检测设置,我们还根据观察到的工业生产中的良品率通常大于60%的情况,提出了一种全新的全无监督工业异常检测(FUIAD)设置,这具有更实际的应用价值。最后,我们报告了在Real-IAD数据集上流行的IAD方法的结果,为推动IAD领域的发展提供了一个高度具有挑战性的基准。
06 用于参数高效网络堆叠的低秩残差结构
LORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking
Jialin Li, Qiang Nie, Weifu Fu, Yuhuan Lin, Guangpin Tao, Yong Liu, Chengjie Wang
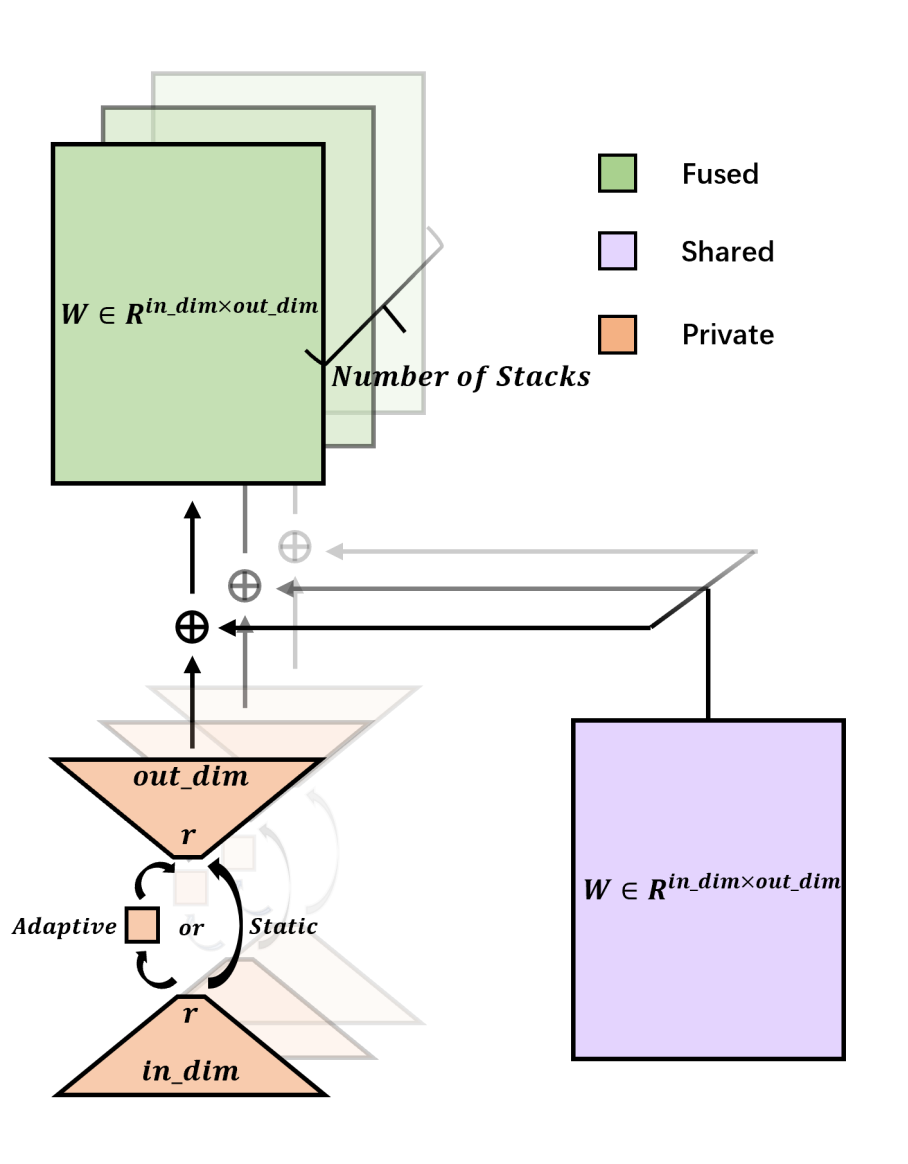
深度学习模型,尤其是基于transformer的模型,通常采用许多堆叠结构,这些结构具有相同的架构并执行类似的功能。尽管这种堆叠范式有效,但它导致参数数量大幅增加,给实际应用带来挑战。在如今越来越大的模型格局中,堆叠深度甚至可以达到几十层,进一步加剧了这个问题。为了缓解这个问题,我们引入了LORS(LOw-rank Residual Structure,低秩残差结构)。LORS允许堆叠模块共享大部分参数,每个模块只需要更少的私有参数即可达到甚至超过使用完全不同参数的性能,从而显著减少参数使用。我们通过将其应用于基于query的对象检测器的堆叠解码器来验证我们的方法,并在广泛使用的MS COCO数据集上进行大量实验。实验结果表明,我们的方法非常有效,即使在解码器参数减少70%的情况下,我们的方法仍然能使模型达到与原始模型相当甚至更好的性能。我们希望我们的工作能激发更多相关研究。
07 一次对齐和提示所有内容的通用视觉感知
Aligning and Prompting Everything All at Once for Universal Visual Perception
Yunhang Shen, Chaoyou Fu, Peixian Chen, Mengdan Zhang, Ke Li, Xing Sun, Yunsheng Wu, Shaohui Lin (East China Normal University), Rongrong Ji (Xiamen University)
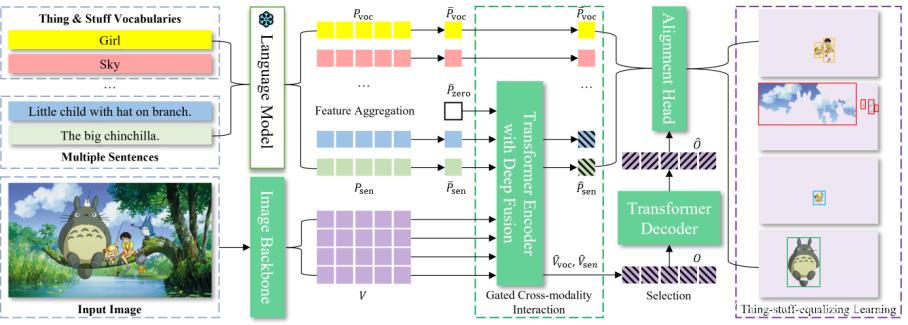
最近,人们已经开始探索视觉基础模型,以构建通用视觉系统。然而,主导的范式,通过将实例级任务视为对象-词对齐,带来了重度的跨模态交互,这在促进目标检测和视觉定位方面并不有效。另一种侧重于像素级任务的工作线经常遇到大量的可数前景和不可数背景的标注差距,并且前景目标和背景类别分割之间的相互干扰。与主流方法截然不同,我们提出了APE,一种通用的视觉感知模型,用于在图像中一次性对齐和提示所有事物,以执行多样化的任务,即,检测、分割和定位,作为一个实例级的句子-目标匹配范式。具体来说,APE通过将语言引导的定位重新定义为开放词汇检测,推进了检测和定位的融合,这有效地扩大了模型提示到数千个类别词汇和区域描述,同时保持了跨模态融合的有效性。为了弥补不同像素级任务的粒度差距,APE通过将任何孤立区域视为单个实例,将语义和全景分割等同于代理实例学习。APE在广泛的数据上对齐视觉和语言表示,一次性处理所有自然和具有挑战性的特征,而无需任务特定的微调。在超过160个数据集上的广泛实验表明,APE仅使用一套权重,就超过(或与)了最先进的模型,证明了一个有效且通用的感知任何对齐和提示的模型确实是可行的。
论文链接:https://arxiv.org/pdf/2312.02153
08 基于令牌扩展的注意力模型的通用高效训练
A General and Efficient Training for Transformer via Token Expansion
Wenxuan Huang (East China Normal University), Yunhang Shen, Jiao Xie (Xiamen University), Baochang Zhang, Gaoqi He (East China Normal University), Ke Li, Xing Sun, Shaohui Lin (East China Normal University)
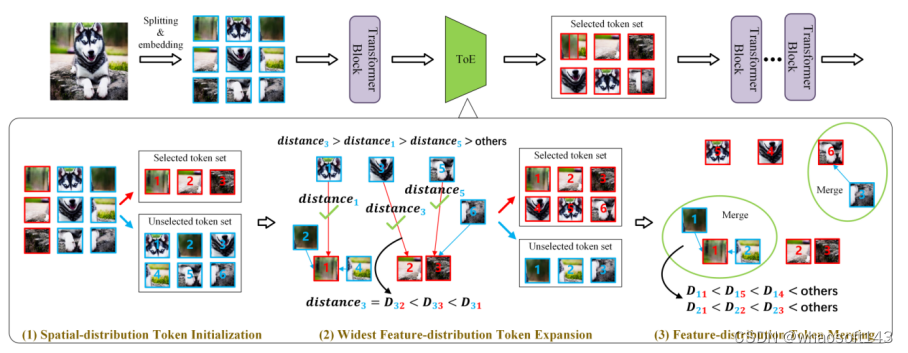
视觉注意力模型(ViTs)的卓越性能通常需要极大的训练成本。现有方法试图加速ViTs的训练,但通常会忽略方法的通用性,导致准确性下降。同时,他们破坏了原始注意力模型的训练一致性,包括超参数、架构和策略的一致性,这阻碍了它们被广泛应用于不同的注意力网络。在本文中,我们提出了一种新颖的令牌增长方案Token Expansion(简称ToE),以实现ViTs的一致性训练加速。我们引入了一个“初始化-扩展-合并”的流程,以保持原始注意力中间特征分布的完整性,防止训练过程中关键可学习信息的丢失。ToE不仅可以无缝地集成到注意力(例如DeiT和LV-ViT)的训练和微调过程中,而且对于高效训练框架(例如EfficientTrain)也是有效的,无需扭曲原始训练超参数、架构,并引入额外的训练策略。大量实验表明,ToE以无损方式实现了ViTs训练速度的约1.3倍提升,甚至在全令牌训练基线上取得了性能提升。
09 广义范畴发现中灾难性遗忘问题的求解
Solving the Catastrophic Forgetting Problem in Generalized Category Discovery
XINZI CAO (Xiamen University), Xiawu Zheng (Xiamen University), Guanhong Wang (Zhejiang University), Weijiang Yu (SUN YAT-SEN UNIVERSITY), Yunhang Shen, Ke Li, Yutong Lu (SUN YAT-SEN UNIVERSITY), Yonghong Tian (Peking University)
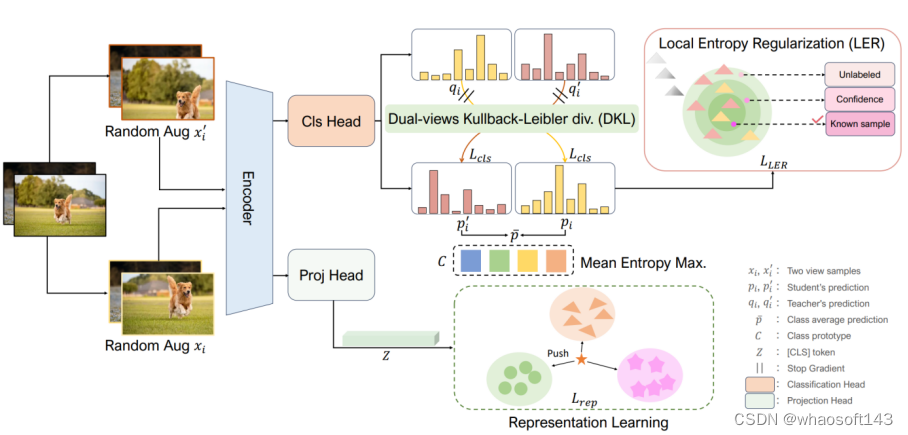
广义类别发现(GCD)旨在识别无标签数据集中已知和新颖类别的混合,为图像识别提供更现实的设置。本质上,GCD需要彻底记住现有模式以识别新颖类别。最近的最先进方法SimGCD通过去偏学习将已知类数据的知识转移到新类的学习中。然而,在适应过程中,一些模式被灾难性地遗忘,从而导致新类别分类的性能不佳。为了解决这个问题,我们提出了一种新颖的学习方法,LegoGCD,它可以无缝地整合到先前的方法中,以提高对新类别的辨别能力,同时保持对以前遇到的已知类别的性能。具体来说,我们设计了两种技术,称为局部熵正则化(LER)和双视图Kullback-Leibler散度约束(DKL)。LER优化了无标签数据中潜在已知类样本的分布,从而确保在学习新类时保留与已知类别相关的知识。同时,DKL引入Kullback-Leibler散度,鼓励模型对来自同一图像的两个视图样本产生类似的预测分布。通过这种方式,它成功地避免了不匹配的预测,并同时生成了更可靠的潜在已知类样本。大量实验证明,所提出的LegoGCD在所有数据集上有效地解决了已知类别遗忘问题,例如,在CUB上分别提高了7.74%和2.51%的已知类和新类的准确性。
10 用于快速保持身份的多功能肖像模型
PortraitBooth : A Versatile Portrait Model for Fast Identity-preserved Personalization
Xu Peng (Xiamen University), Junwei Zhu, Boyuan Jiang, Ying Tai (Nanjing University), Donghao Luo, Jiangning Zhang, Wei Lin(Xiamen University), Taisong Jin(Xiamen University), Chengjie Wang, Rongrong Ji (Xiamen University)
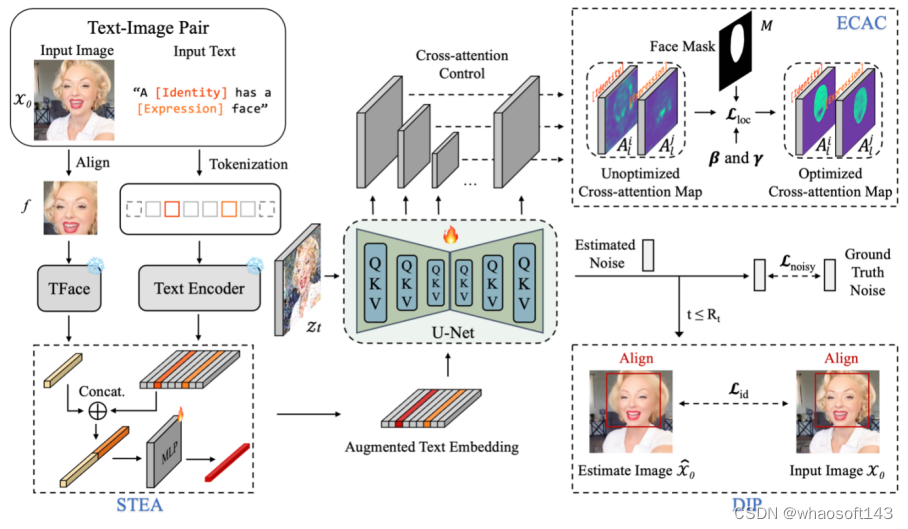
本文提出一种基于扩散模型的个性化图像生成方法(PortraitBooth),能够在满足高效率、鲁棒身份保持的条件下实现表情可编辑的文本到图像生成。首先,利用人脸识别模型获得的特征嵌入进行个性化图像生成,降低了计算开销并缓解了身份失真问题。其次,引入动态身份保护策略确保生成图像与原始图像高度相似。最后,融入情感感知的交叉注意力控制用于生成图像中的多样化面部表情,并支持文本驱动的表情编辑。实验结果表明:无论是在单一还是多目标图像生成场景,本文方法明显优于现有方法,获得更好的个性化图像生成效果。
11 基于隐层重建特征的生成图像检测方法
LaRE^2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
Yunpeng Luo, Junlong Du,Ke Yan, Shouhong Ding
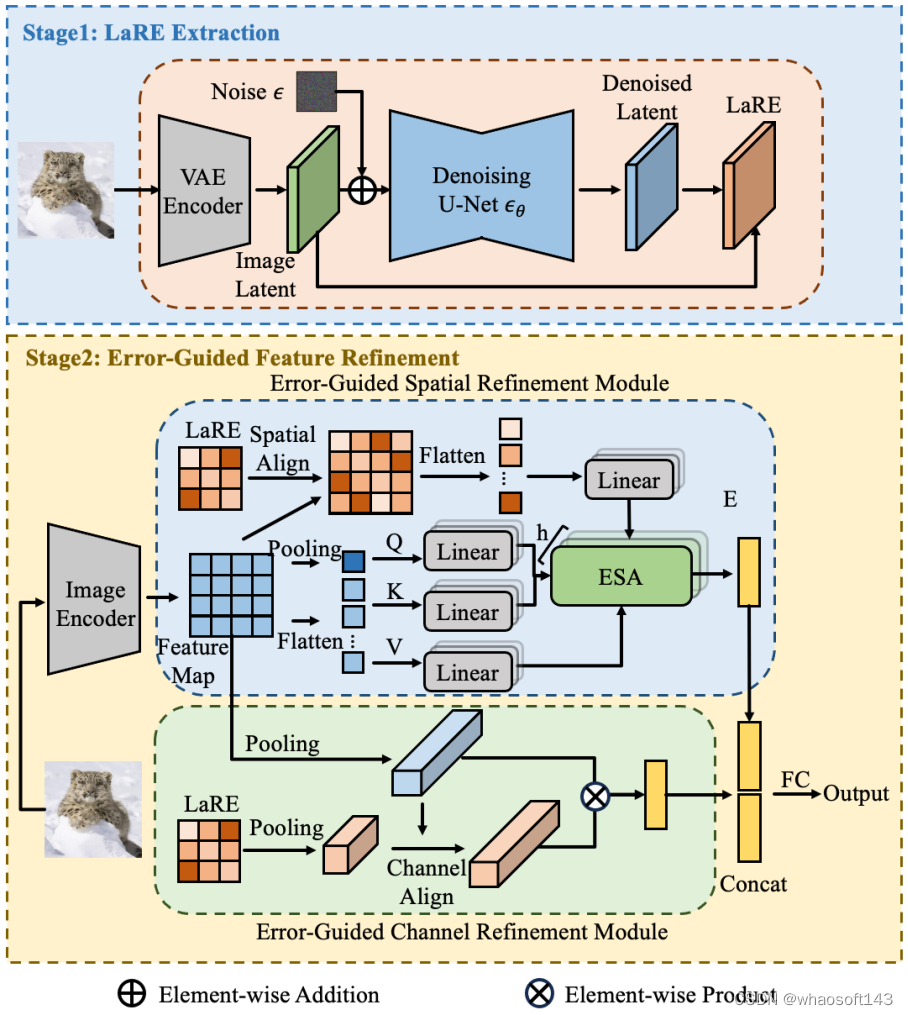
扩散模型的进步显著提升了图像生成质量,使得真实图像与生成图像的区分变得越来越难。这种进步虽然令人兴奋,但也带来了严重的隐私和安全问题。为了解决这个问题,我们提出了一种新颖的特征增强方法,名为基于隐层重建误差的特征增强(LaRE^2),用于检测扩散模型生成的图像。我们首次将基于重建误差的隐层空间特征(LaRE)用于生成图像检测。LaRE在特征提取效率上超越了现有方法,同时保留了区分真实和生成图像的关键信息。为了充分利用LaRE,我们设计了一个误差引导的特征增强模块(EGRE),通过LaRE增强图像特征,提高特征的区分度。EGRE采用对齐+增强的策略,从空间和通道两个维度有效地增强了图像特征。在GenImage基准测试中,我们进行了大量实验,证明了LaRE^2的有效性。具体来说,LaRE^2在8个不同的图像生成模型上,平均准确率/平均精度超过了最佳现有方法高达11.9%/12.1%。同时,LaRE在特征提取速度上也超过了现有方法,是其速度的8倍。
12 自蒸馏人体姿态估计
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Sichen Chen(SJTU/Tencent), Yingyi Zhang, Siming Huang, Ran Yi(SJTU), Ke Fan(SJTU), Ruixin Zhang, Peixian Chen, Jun Wang, Shouhong Ding, Lizhuang Ma(SJTU)
本文由腾讯优图实验室、腾讯微信支付33号实验室、上海交通大学共同完成
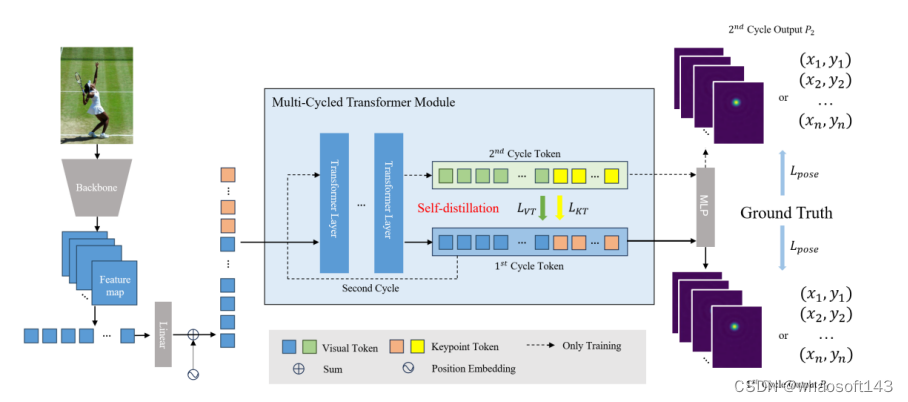
小型自注意力模型往往受到欠拟合问题影响,为了解决这个问题,我们提出了自注意力模型的潜在深度概念,并基于此设计了一种自蒸馏的训练方法,该方法在人体姿态估计任务上相同性能的情况下能够降低25%的参数量与33%的运算量,同时在图像分类与分割任务中也证实有效。
13 基于测试阶段域泛化的人脸活体检测方法
Test-Time Domain Generalization for Face Anti-Spoofing
Qianyu Zhou (Shanghai Jiaotong University),Ke-Yue Zhang,Taiping Yao,Xuequan Lu (Deakin University),Shouhong Ding,Lizhuang Ma (Shanghai Jiaotong University)
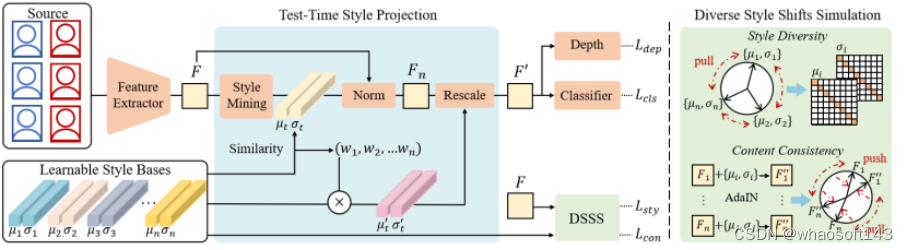
人脸活体检测旨在防止人脸识别系统免受各种人脸呈现攻击的干扰。现有的域泛化活体检测方法主要侧重于在训练过程中学习域不变特征,然而这可能无法保证在与源域分布具有巨大差异的未见目标域数据上的泛化性。本文的核心思想是,测试数据不仅仅是用于模型测试,还可以作为一种有价值的资源以提高对活体检测的泛化性。本文提出了一个新的测试阶段域泛化(TTDG)框架,该框架利用测试数据以提高模型的泛化能力。主要包括两个关键的组件:测试阶段风格投影(TTSP)和多样化风格偏移模拟(DSSS),以有效地将未见数据投影到可见的源域空间。其中,测试阶段风格投影将任意未知域的测试样本的风格投影到训练分布的已知源域空间。此外,本文设计了有效的多样化风格偏移模拟,通过两个特别设计的损失和可学习的风格基在超球面特征空间中合成不同的风格偏移。本方法不需要在测试时重新更新模型,并且不仅可以无缝集成到基于CNN的活体检测方法中,还可以集成到基于ViT主干的活体检测框架。在跨域活体检测基准的大量实验分析证明了所提方法的先进性和有效性。
14 双曲空间中层级化原型引导分布建模的域泛化人脸活体检测方法
Rethinking Generalizable Face Anti-spoofing via Hierarchical Prototype-guided Distribution Refinement in Hyperbolic Space
Chengyang Hu (Shanghai Jiaotong University),Ke-Yue Zhang,Taiping Yao,Shouhong Ding,Lizhuang Ma (Shanghai Jiaotong University)
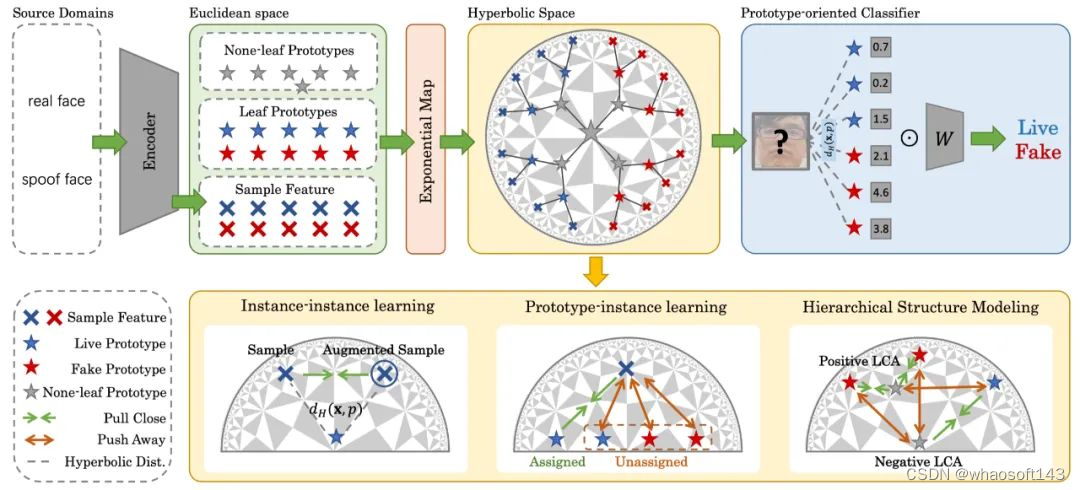
域泛化人脸活体检测方法因其对未见场景中的各种呈现攻击的鲁棒性而引起了越来越多的关注。大多数以前的域泛化方法总是通过将不同源域样本直接对齐到公共特征空间提升泛化能力。然而,这些方法忽略了活体攻击中的层次关系,直接对齐可能会阻碍泛化能力。为了解决这些问题,我们提出了一种新颖的层次化的原型引导分布细化框架在双曲空间中学习特征分布,这有利于构建层次关系。我们还引入原型学习,以实现双曲空间中的分层分布细化。具体来说,我们提出分层原型学习,通过约束双曲空间中原型和实例之间的多级关系来同时指导域对齐并提高判别能力。此外,我们设计一个面向原型的分类器,进一步考虑样本和原型之间的关系,以提高最终决策的稳健性。大量的实验和可视化证明了我们方法的有效性。
15 基于锚点的图文预训练模型鲁棒微调
Anchor-based Robust Finetuning of Vision-Language Models
Jinwei Han(Wuhan University), Zhiwen Lin, Zhongyi Sun, Yingguo Gao, Ke Yan, Shouhong Ding, Yuan Gao(Wuhan University), Guisong Xia(Wuhan University)
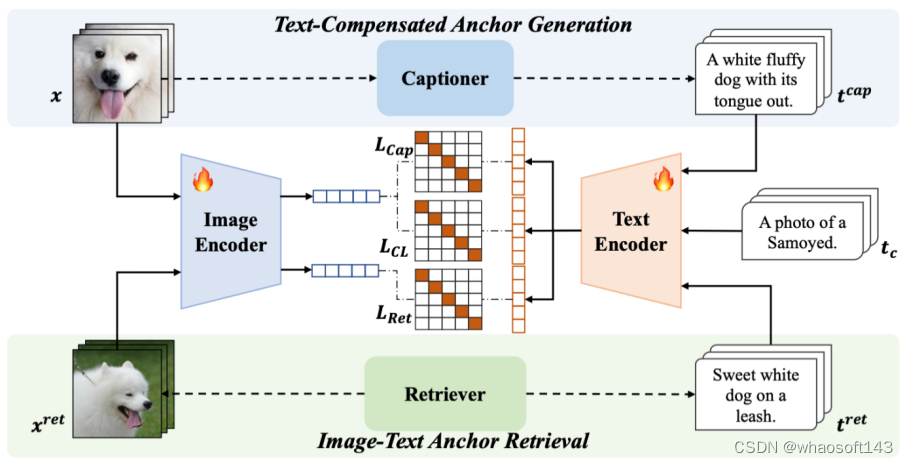
本文的目标是微调图文预训练模型并保持其在分布外(OOD)的泛化能力。本文解决了两种类型的OOD泛化问题,即i)领域偏移,例如从自然图像到草图图像,和ii)零样本识别能力,即识别未包含在训练数据中的类别。我们认为,图文预训练模型微调后OOD泛化能力的降低主要源于微调过程中监督信息过于简单,仅提供类别信息,如“a photo of a [CLASS]”。这与CLIP预训练过程不同,CLIP预训练过程中有丰富语义信息的文本监督。因此,我们提出使用具有丰富语义信息的辅助监督作为锚点来保留OOD泛化能力。具体而言,本文提出的方法使用了两种类型的锚点,包括i)文本补偿锚点,利用预训练好的captioner对训练数据集生成具有丰富语义信息的文本,ii)图像-文本对锚点,利用下游数据集作为查询集,从开源的图像-文本对数据集中检索而来。这些锚点被用作辅助语义信息,来保持CLIP的原始特征空间,进而保留OOD泛化能力。实验表明,我们的方法的分布内(ID)性能与传统微调方法基本持平,同时在领域偏移和零样本学习基准测试中取得了最优结果。
16 基于可微分视觉提示的零样本目标指代理解
Tune-An-Ellipse: CLIP Has Potential to Find What You Want
Jinheng Xie(National University of Singapore),Songhe Deng(Shenzhen University), Bing Li(King Abdullah University of Science and Technology), Haozhe Liu(King Abdullah University of Science and Technology), Yawen Huang, Yefeng Zheng,Jürgen Schmidhuber(King Abdullah University of Science and Technology), Bernard Ghanem(King Abdullah University of Science and Technology), Linlin Shen(Shenzhen University), Mike Zheng Shou(National University of Singapore)
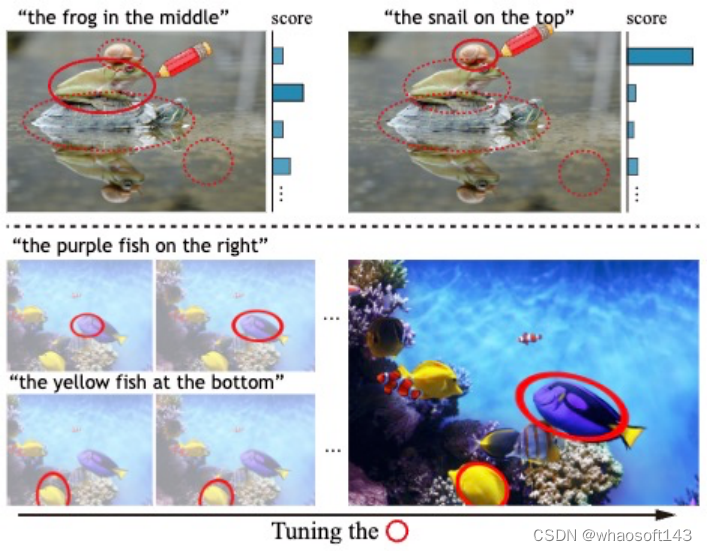
大型视觉语言模型(如CLIP)的视觉提示展示了有趣的零样本能力。常用于突出显示的手绘红圈可以引导CLIP的注意力到周围区域,以识别图像中的特定对象。然而,缺乏精确的对象提议,这种方法对于定位来说是不足够的。我们提出了一种新颖、简单而有效的方法,使CLIP能够进行零样本定位:给定一张图像和描述对象的文本提示,我们首先通过视觉提示从图像网格上均匀分布的锚点椭圆中选择一个初始椭圆,然后使用三个损失函数逐渐调整椭圆系数以包围目标区域。这为没有精确指定对象提议的指代表达理解提供了有希望的实验结果。此外,我们系统地介绍了CLIP中视觉提示固有的局限性,并讨论了改进的潜在途径。
17 多任务密集预测
Going Beyond Multi-Task Dense Prediction with Synergy Embedding Models
Huimin Huang (Zhejiang University), Yawen Huang, Lanfen Lin (Zhejiang University),Tong Ruofeng (Zhejiang University), Yen-wei Chen (Ritsumeikan University),Hao Zheng, Yuexiang Li (Guangxi Medical University), Yefeng Zheng
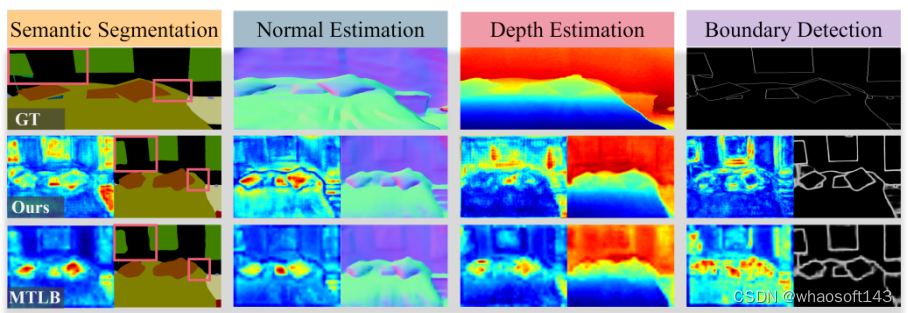
多任务视觉场景理解旨在利用一组相关任务之间的关系,通过将它们嵌入到一个统一的网络中来同时解决这些任务,以实现像素级预测。然而,大多数现有方法从任务层面上引发了两个主要问题:(1)不同任务缺乏任务独立的对应关系;(2)忽视了各种任务之间明确的共识依赖性。为了解决这些问题,我们提出了一种新颖的协同嵌入模型(SEM),它通过利用两种创新设计超越了多任务密集预测:任务内部的层级适应模块和任务间的EM交互模块。具体来说,构建的任务内部模块从多个阶段整合了层级适应的关键因素,使得能够以最佳的权衡高效学习专门的视觉模式。此外,开发的任务间模块从各种任务之间的紧凑共同基础中学习交互作用,受益于期望最大化(EM)算法。来自两个公共基准测试NYUD-v2和PASCAL-Context的广泛实证证据表明,SEM在一系列指标上始终优于最先进的方法。
18 全病理图像的癌症亚型分类
ViLa-MIL: Dual-scale Vision-Language Multiple Instance Learning for Whole Slide Image Classification
Jiangbo Shi (Xi'an Jiaotong University), Chen Li (Xi'an Jiaotong University), Tieliang Gong (Xi'an Jiaotong University), Yefeng Zheng, Huazhu Fu (A*STAR of Singapore)
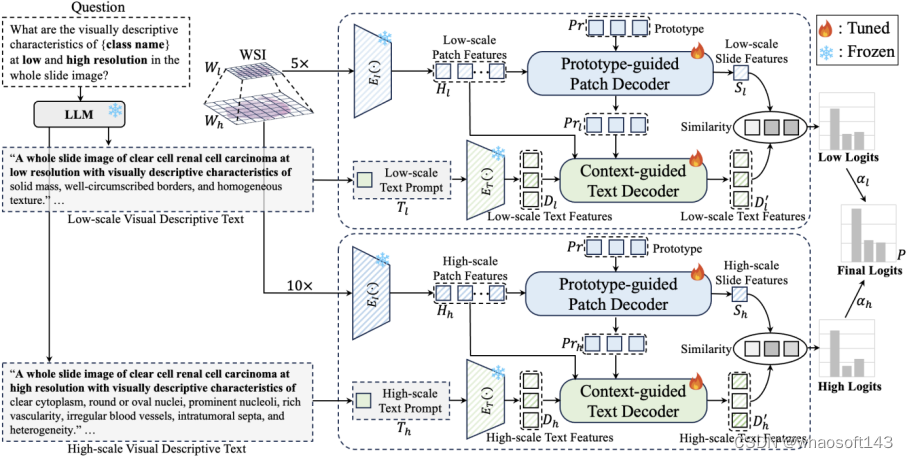
基于多实例学习(Multiple Instance Learning, MIL)的框架已经成为处理数字病理学中具有千兆像素大小和层次化图像上下文的全幅图像(Whole Slide Image, WSI)的主流方法。然而,这些方法严重依赖于大量的包级别标签,并且仅从原始图片中学习,这很容易受到数据分布变化的影响。最近,基于视觉语言模型(Vision Language Model, VLM)的方法通过在大规模病理图像-文本对上进行预训练,引入语言先验。然而,之前的文本提示(Text Prompt)缺乏对病理先验知识的考虑,因此并未实质性地提升模型的性能。此外,这种图文对的收集和预训练过程非常耗时,消耗大量算力资源。为了解决上述问题,我们提出了一个双尺度视觉-语言多实例学习(ViLa-MIL)框架,用于全幅病理图像分类。具体来说,我们提出了一个基于冻结的大型语言模型(Large Language Model, LLM)的双尺度视觉描述性文本提示,以有效地提升VLM的性能。为了让VLM有效地处理WSI,对于图像分支,我们提出了一个原型(prototype)引导的图像块(patch)解码器,通过将相似的图像块分组到同一原型中,逐步聚合图像块特征;对于文本分支,我们引入了一个上下文引导的文本解码器,通过整合多粒度图像上下文来增强文本特征。在三个多癌种、多中心癌症亚型分类数据集上的广泛研究证明了ViLa-MIL的优越性。
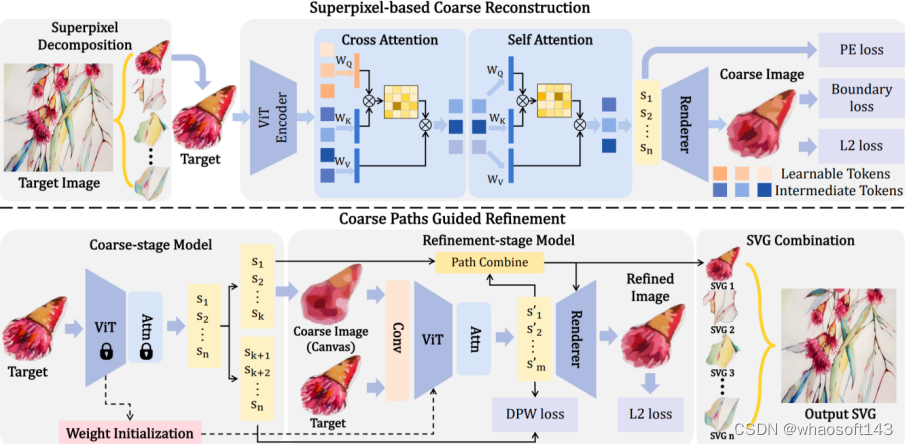
19 SuperSVG:基于超像素的图像矢量化模型
SuperSVG: Superpixel-based Scalable Vector Graphics Synthesis
Teng Hu(Shanghai Jiao Tong University), Ran Yi(Shanghai Jiao Tong University), Baihong Qian(Shanghai Jiao Tong University), Jiangning Zhang, Paul L Rosin(Cardiff University), Yu-Kun Lai(Cardiff University)
20 为通用三维大规模感知构建强预训练基线
Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
Haoming Chen(ECNU), Zhizhong Zhang(ECNU), Yanyun Qu(XMU), Ruixin Zhang, Xin Tan(ECNU), Yuan Xie(ECNU)
本文由华东师范大学、厦门大学、腾讯优图实验室共同完成
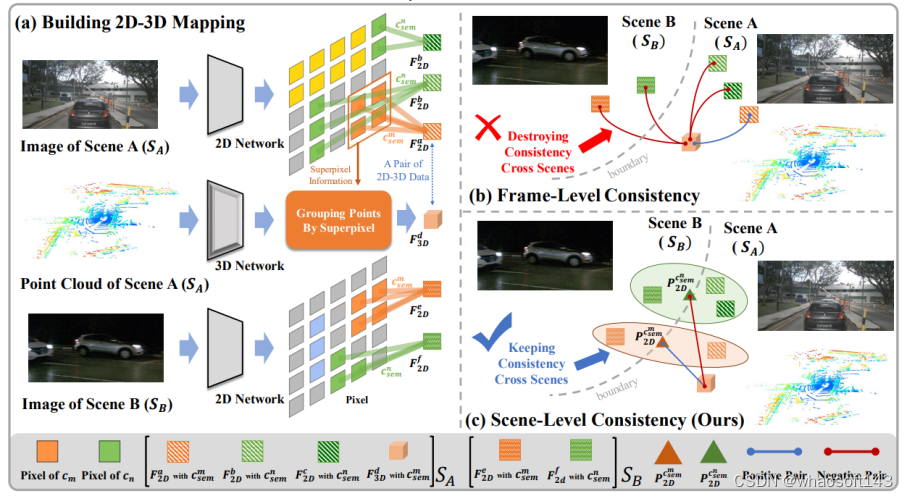
在感知大规模动态场景时,需要一个具有通用 3D 表示的有效预训练框架。然而当前的对比3D预训练方法通常遵循帧级一致性,重点关注每个分离图像中的 2D-3D 关系,没有考虑以下挑战(1)跨场景语义自冲突,即来自不同场景的相同语义的原始片段之间的强烈冲突;(2)缺乏将跨场景语义一致性推向3D表示学习的全局统一纽带。为了解决上述挑战,我们提出了一个CSC框架,该框架将场景级语义一致性放在核心位置,桥接不同场景中相似语义片段的连接。为了实现这一目标,我们结合了视觉基础模型提供的连贯语义线索和从互补的多模态信息派生的知识丰富的跨场景原型。 这些使我们能够训练通用的 3D 预训练模型,以更少的微调工作来促进各种下游任务。我们在语义分割、对象检测和全景分割均实现了对SOTA的改进。
#人类理解能力碾压GPT-4
大模型能否理解自己所说,Hinton和LeCun再次吵起来了。LeCun新论文证明,GPT-4回答问题准确率仅为15%,自回归模型不及人类。
AI大佬的激战再次掀起。
Hinton在线直接点名LeCun,说他对AI接管风险的看法对人类的影响微乎其微。
这意味着,他把自己的意见看得很重,而把许多其他同样有资格的专家的意见看得很轻。
在Hinton看来,他们之间意见分歧的核心论点是「LLM是真正理解自己说什么」。
当然了,一直站在末日派中的Hinton认为大模型有了意识,而LeCun、吴恩达等人却认为LLM不明白自己所说。
对此,LeCun反驳道,大模型显然对其阅读和生成的内容有「一些」理解,但这种理解是非常有限和肤浅的。
总的来说,目前自回归大模型没有对推理和规划能力,远未及人类水平的智能。
恰在近日,LeCun发表了一篇新论文,再提自回归LLM做得不好。
论文中,研究人员介绍了一个通用AI助手基准GAIA。
其中提出了需要一系列基本能力的现实世界问题,比如推理、多模态处理、网页浏览和一般的工具使用熟练程度。
论文地址:https://arxiv.org/pdf/2311.12983.pdf
结果表明,GAIA设计的问题对人类来说简直轻而易举,而对大多数高级AI来说却很有挑战性。
即,人类回答准确率为92%,而用上插件的GPT-4回答准确率仅为15%。
通用人工智能助手基准——GAIA
GAIA的产生,既是因为需要修订AI基准,也是因为发现了LLM评估的不足之处。
研究人员提出的通用人工智能助手的基准——GAIA,包含了466个精心设计的问题和答案,以及相关的设计方法。
这些问题对AI系统具有挑战性,大多数需要复杂的代数。
但又能给出唯一的、符合事实的答案,从而实现简单而稳健的自动评估。

GAIA问题示例
设计选择
第一个原则:瞄准概念上简单但对人类来说可能乏味的问题。
这些问题多种多样的,植根于现实世界,对当前的人工智能系统具有挑战性。
因此,这些问题的设计将重点放在基本能力上,如通过推理快速适应、多模态理解和潜在的多样化工具使用,而不是专业技能上。
问题一般包括查找和转换从不同来源收集到的信息,如提供的文档或开放且不断变化的网络,从而得出准确的答案。
第二个原则:可解释性。
由于高度精选的问题数量有限,因此与汇总问题相比,该基准更易于使用。
任务的概念简单性(人类成功率为 92%)使得用户很容易理解模型的推理轨迹。
第三个原则:对记忆的鲁棒性。
为了完成一项任务,GAIA系统必须计划并成功地完成一些步骤,因为从当前的训练前数据中,得到的答案是设计成纯文本的。
第四个原则:易用性。
研究者的任务是附加文件的简单提示。至关重要的是,问题的答案是事实,简明和明确的。
这些特性允许简单、快速和事实性的评估。
评估
GAIA的设计的评估是自动化的、快速的、真实的。
在实践中,除非另有说明,否则每个问题都需要一个答案,这个答案要么是一个字符串(一个或几个单词) ,一个数字,要么是用逗号分隔的字符串或浮点列表。
每个问题,只有一个正确答案。
因此,评估是通过模型的答案和地面真值之间的准确匹配来完成的。
如下图,回答GAIA问题时,像GPT-4这样的人工智能助手,需要完成几个步骤,可能需要使用工具或者读取文件。

GAIA的构成
想要在GAIA上获得完美的分数,大模型需要先进的推理能力、多模态的理解、编码能力和一般的工具使用,例如网页浏览。
根据解决问题所需步骤的数量和回答问题所需的不同工具的数量,可以将问题分为三个难度增加的级别。
- 1级问题通常不需要任何工具,或者最多只需要一个工具,但不超过5个步骤。
- 第2级问题通常涉及更多的步骤,大约在5到10之间,需要结合不同的工具。
- 第三级是一个近乎完美的普通助理的问题,需要采取任意长的动作序列,使用任意数量的工具,并进入一般的世界。
GPT-4表现如何
使用GAIA评估大型语言模型只需要具备向模型发出提示的能力,即API访问权限。
研究人员在提问前使用一个前缀提示词,以便于提取答案,具体参见下图。

研究人员评估了GPT-4带插件和不带插件的版本,以及以GPT-4为后端的AutoGPT。
目前,GPT-4需要手动选择插件。相反,AutoGPT能够自动进行这一选择。
研究人员采用的的非LLM基准包括人类注释者和网络搜索。对于后者,他们在搜索引擎中输入问题,并检查是否能从搜索结果的第一页中推导出答案。
这使他们能够评估研究人员的问题答案是否可以轻松地在网络上找到。只要API可用,就运行模型三次,并呈现得到的平均结果。
GPT-4插件
与GPT-4不同的是,目前还没有带插件的GPT-4 API,研究人员不得不手动进行ChatGPT查询。
在撰写本文时,用户必须手动在一个高级数据分析模式(具有代码执行和文件读取能力)和最多三个第三方插件之间进行选择。研究人员根据任务给定的最重要功能的最佳猜测,选择第一种模式或选择第三方插件。研究人员通常依赖于:
(i)一个用于阅读各种类型链接的工具,
(ii)一个网络浏览工具,
(iii)一个用于计算的工具。
遗憾的是,目前无法在一段时间内使用一组稳定的插件,因为插件经常更改或从商店中消失。
同样,GPT-4的官方搜索工具也被移除,因为它可能绕过付费墙,但最近又重新推出。因此,研究人员对带插件的GPT4的评分是GPT-4潜力的「预估」,是基于更稳定和自动选择插件的估计。
结果
研究人员的评估结果如下图所示。
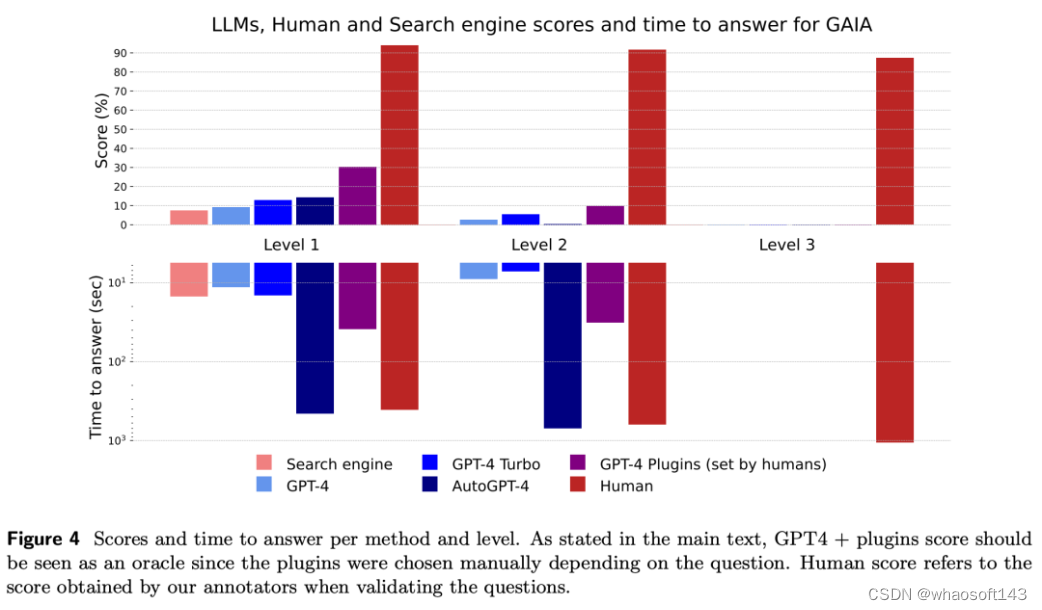
研究人员提出的难度等级,大致根据步骤数量和使用的不同能力数量定义,与当前模型的性能相关,增强了它们的有效性。
虽然人类在所有层面上表现出色,但当前最好的LLM表现不佳。
总的来说,GAIA允许清晰地对有能力的助手进行排名,同时也为未来几个月甚至几年的改进留下了很大的空间。
人类通过网络搜索可能会获得文本结果,从中可以推断出一级难度问题的正确答案,但当涉及到稍微复杂一点的查询时,这种方法就不那么有效了,并且比典型的大型语言模型(LLM)助手稍慢,因为用户需要浏览首批搜索结果。
这证实了LLM助手作为搜索引擎的竞争者的潜力。
GPT-4在没有插件的情况下的结果与其他情况的差异表明,通过工具API或访问网络增强LLM可以提高答案的准确性,并解锁许多新的用例,确认了这一研究方向的巨大潜力。
特别是,GPT-4加上插件表现出了诸如回溯或查询优化等行为,当结果不令人满意时,以及相对较长的计划执行时间。
AutoGPT-4允许GPT-4自动使用工具,但其在二级难度,甚至与不带插件的GPT-4相比,一级难度的结果也令人失望。这种差异可能来自AutoGPT-4依赖GPT-4 API(提示和生成参数)的方式。
与其他LLM相比,AutoGPT-4也较慢。总的来说,人类与带插件的GPT4的合作似乎到目前为止提供了最佳的得分与所需时间比。
下图显示了按能力划分的模型得分。
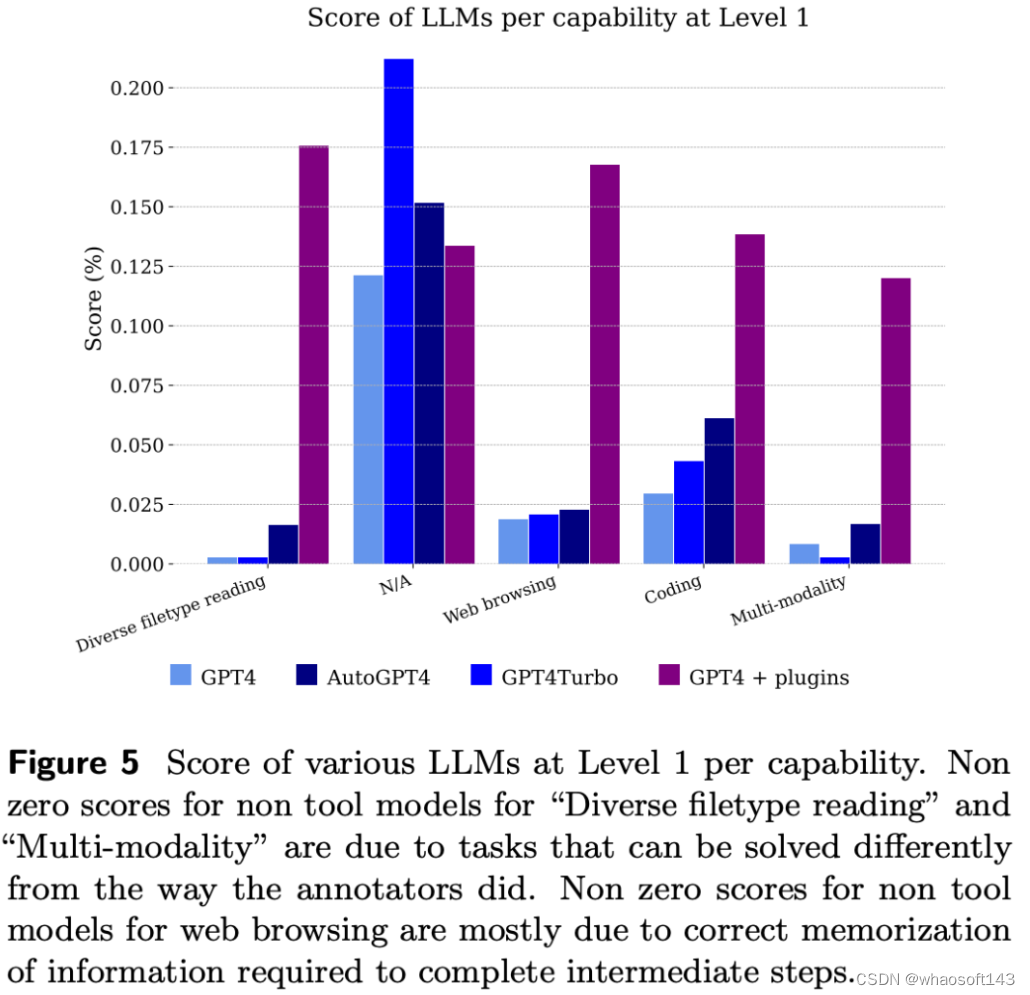
不出所料,GPT-4无法处理文件和多模态问题,但能够解决注释者使用网络浏览解决的问题,主要是因为它正确地记住了需要结合起来才能得到答案的信息片段。
参考资料:
https://twitter.com/ylecun/status/1728496457601183865
https://twitter.com/ylecun/status/1727707519470977311
https://arxiv.org/pdf/2311.12983.pdf
#2024~LLM发展方向
还有 10 个月,2024 年还有很多期待空间。
在过去的 2023 年中,大型语言模型(LLM)在潜力和复杂性方面都获得了飞速的发展。展望 2024 年的开源和研究进展,似乎我们即将进入一个可喜的新阶段:在不增大模型规模的前提下让模型变得更好,甚至让模型变得更小。
现在,2024 年的第一个月已经过去,也许是时候盘点一番新年首月进展了。近日,AI 研究者 Sebastian Raschka 发布了一份报告,介绍了四篇与上述新阶段有关的重要论文。它们的研究主题简单总结起来是这样:
1. 权重平均和模型融合可将多个 LLM 组合成单个更好的模型,并且这个新模型还没有传统集成方法的典型缺陷,比如更高的资源需求。
2. 代理调优(proxy-tuning)技术可通过使用两个小型 LLM 来提升已有大型 LLM 的性能,这个过程无需改变大模型的权重。
3. 通过将多个小型模块组合起来创建混合专家模型,可让所得 LLM 的效果和效率媲美甚至超越更大型的对应模型。
4. 预训练一个小型的 1.1B 参数的 LLM 可降低开发和运营成本,并能为教育和研究应用带来新的可能性。
1.WARM:On the Benefits of Weight Averaged Reward Models
论文地址:https://arxiv.org/abs/2401.12187
在这篇 1 月 22 日的论文《WARM: On the Benefits of Weight Averaged Reward Models》中,研究者提出了一种用于 LLM 奖励模型的权重平均方法。这里的奖励模型是指在用于对齐的 RLHF 中使用的奖励模型。
何为权重平均?因为用于 LLM 的权重平均和模型融合可能会成为 2024 年最有趣的研究主题,在深入介绍这篇 WARM 论文之前,我们先来谈谈这个主题。
了解模型融合和权重平均
模型融合和权重平均并不是新思想,但却是目前最受瞩目的方法。它成为了 Open LLM 排行榜上占据主导地位的技术。下面我们简单讨论一下这两个概念。
权重平均和模型融合都是将多个模型或检查点模型组合成单一实体。这有什么好处?类似于创建集成模型的概念,这种将多个模型组合成一个模型的思想可以提升训练的收敛、提升整体性能和提升稳健性。需要强调的是,不同于传统的集成方法,模型融合和权重平均会得到一个单一模型,而不是维护多个分立的模型,如下图所示。
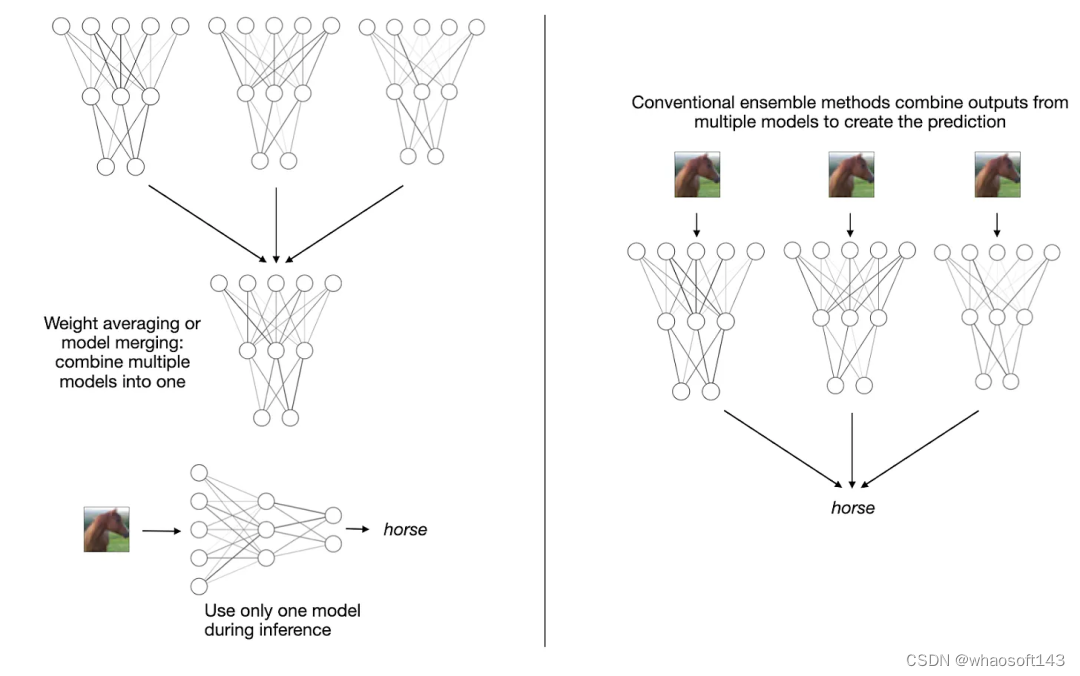
权重平均和模型融合(左)和多数投票(majority voting)等传统集成方法(右)
传统上讲,权重平均涉及到将单个模型在训练过程中不同点的权重参数进行平均。通常而言,这是在模型接近收敛的训练结束时完成的。这一技术的一种常见形式是随机权重平均(SWA,Stochastic Weight Averaging)。这种方法是对一个初始较大的学习率进行衰减,而权重则在学习率衰减期间(仍然相对较高)在多轮迭代上进行平均。
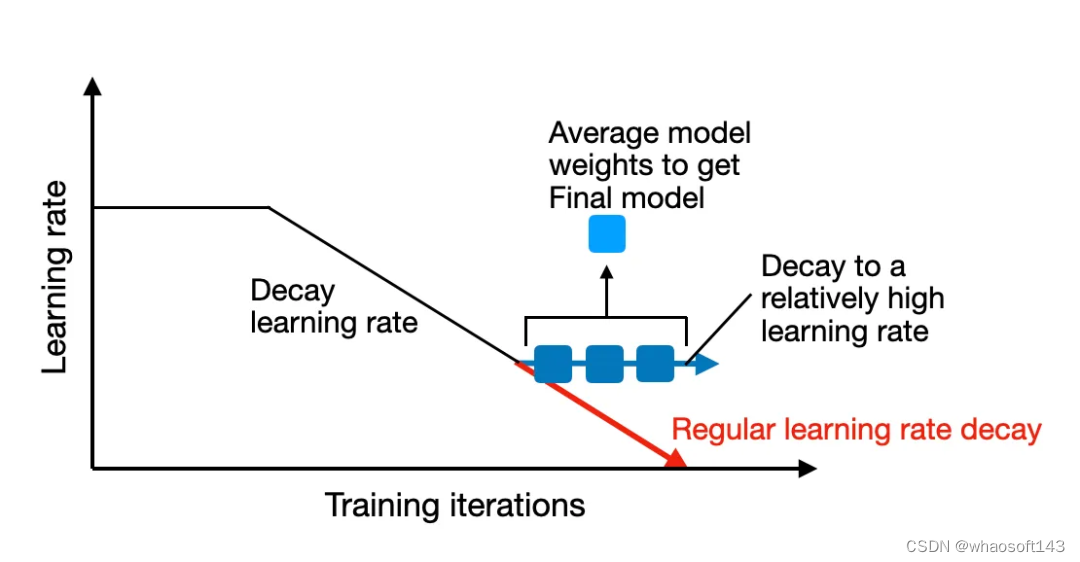
随机权重平均(SWA)是在训练周期快结束时对模型的权重进行平均。
由于模型的训练轨迹可能并不均匀,因此其策略是在训练快结束时计算模型的平均,此时学习率较低,并且训练已接近收敛,如上图所示。
另一种方法是指数移动平均(EMA,Exponentially Moving Average),其做法是通过指数级地降低旧状态的权重来计算权重的一个平滑化版本。
2022 年,最新权重平均(LaWA,Latest Weight Averaging)表明,通过平均最新的 k 个检查点的权重(每个权重都在 epoch 结束时获取),可在损失和准确度方面将训练过程加速多个 epoch。研究表明,这种技术能有效地用于 ResNet 视觉模型和 RoBERTa 语言模型。
然后到了 2023 年,论文《Early Weight Averaging Meets High Learning Rates for LLM Pre-training》探索了 LaWA 的一个修改版,其使用了更高的学习率,并且在训练期间会更早地在平均检查点中开始。其研究者发现,这种方法能显著提升标准 SWA 和 EMA 方法的性能。
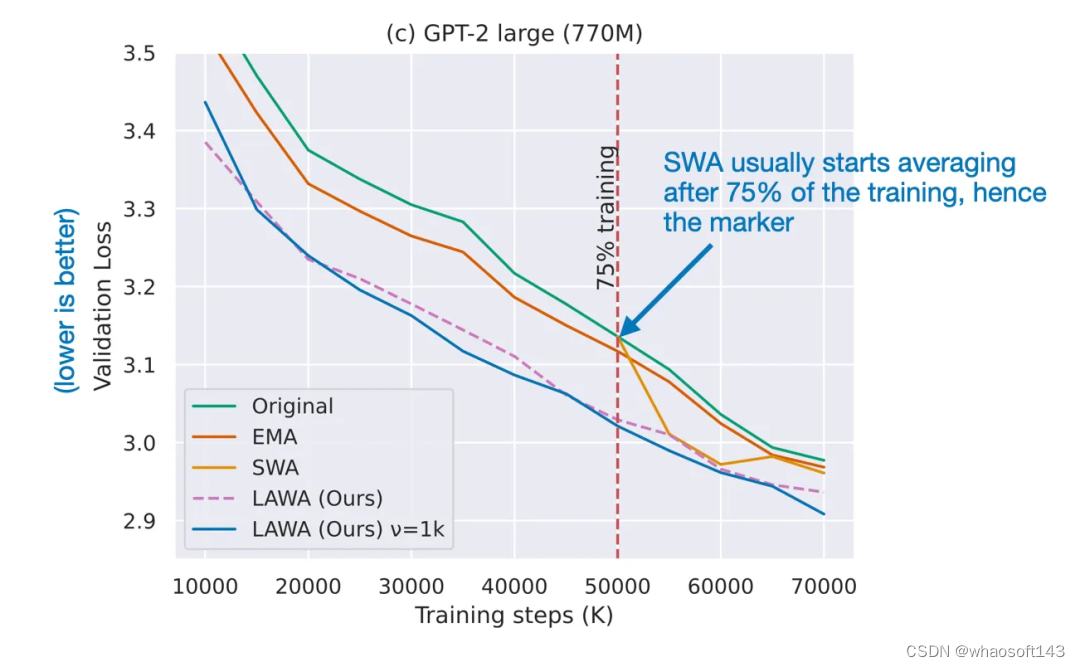
来自论文《Early Weight Averaging meets High Learning Rates for LLM Pre-training》的修改版 LaWA,论文地址:https://arxiv.org/abs/2306.03241
权重平均的做法是将同一模型的多个检查点组合成单个模型,而模型融合则是将多个不同的已训练模型组合成单个模型。这些模型中的每一个都可能是独立训练的,并且可能基于不同的数据集或任务。
模型融合已有较长的历史,但最近一篇颇具影响力的 LLM 相关论文是《Model Ratatouille:Recycling Diverse Models for Out-of-Distribution Generalization》。(论文地址:https://arxiv.org/abs/2212.10445)
Model Ratatouille 背后的思想是复用多个同一基础模型在不同的多样性辅助任务上微调过的迭代版本,如下图所示。
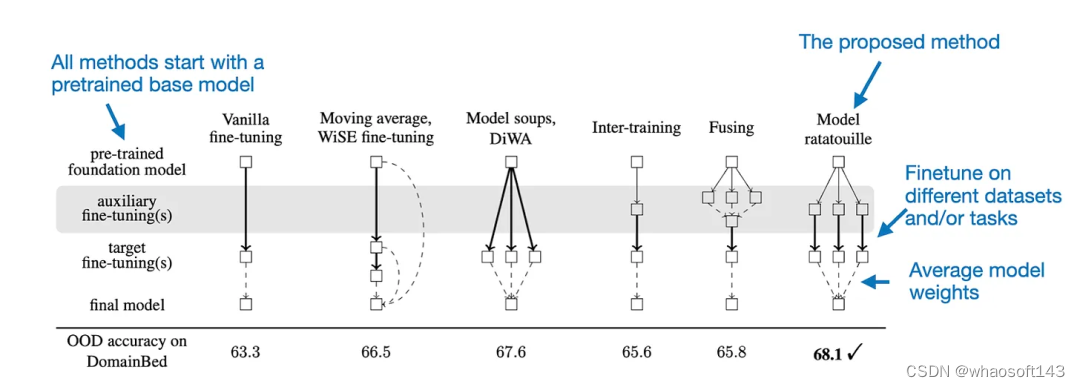
通过 Model Ratatouille 实现模型融合,并且对比了其它微调策略,(OOD = 分布外 / 泛化)
细致来说,Model Ratatouille 方法可以总结成下图。
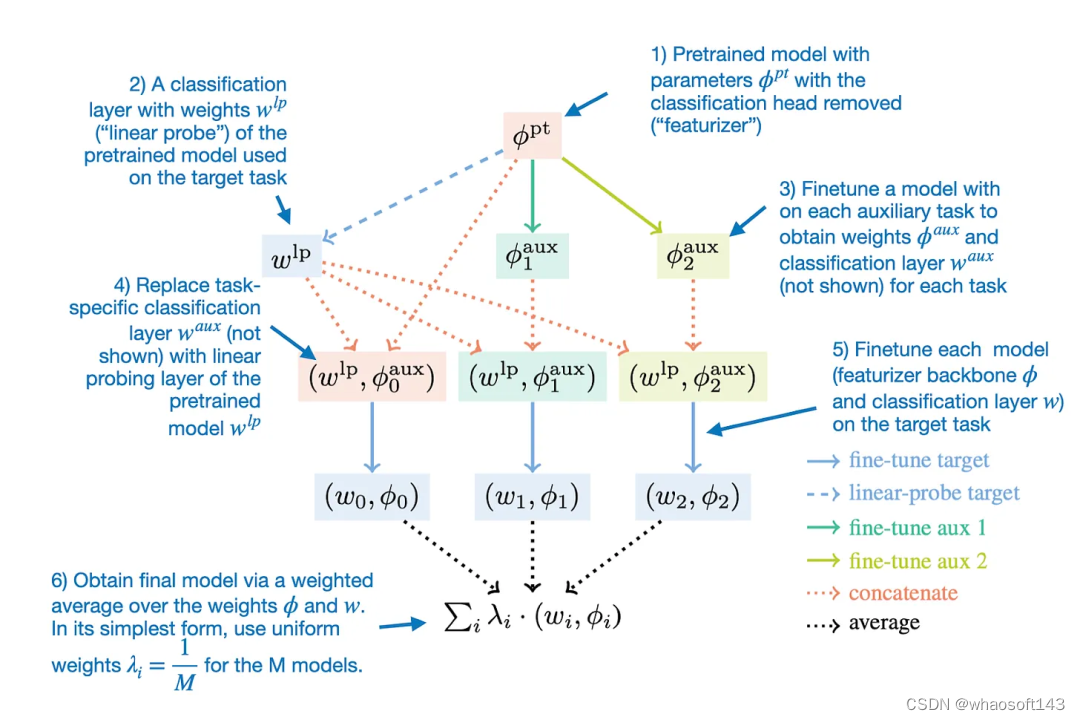
用于模型融合的 Model Ratatouille 方法
请注意,这样的整体思路也可用于 LoRA 适应器,如论文《LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition》展现的那样。(论文地址:https://arxiv.org/abs/2307.13269)
使用了权重平均的奖励模型
讨论完了权重平均和模型融合,下面我们回到近期新发布的论文《WARM:On the Benefits of Weight Averaged Reward Models》。
这项研究的主要目的是提升用于 LLM 的 RLHF 对齐步骤。具体来说,研究者希望通过平均微调后的奖励模型的权重来缓解 LLM 中的奖励骇入(reward hacking)问题。
奖励骇入是指 LLM 学会了操控或利用其奖励系统的漏洞来获得高分或奖励,而不是真正完成预期任务或实现基本目标。

权重平均能让奖励建模更为稳健地应对奖励骇入问题
为了解决奖励骇入问题,WARM 论文提出通过权重平均将 LLM 奖励模型组合到一起。相比于单个奖励模型,通过这个过程得到的融合版奖励模型获得了 79.4% 的胜率。
WARM 是如何发挥作用的?方法其实相当简单:类似于随机权重平均,WARM 会对多个模型(这里是奖励模型)的权重进行平均,如下图所示。
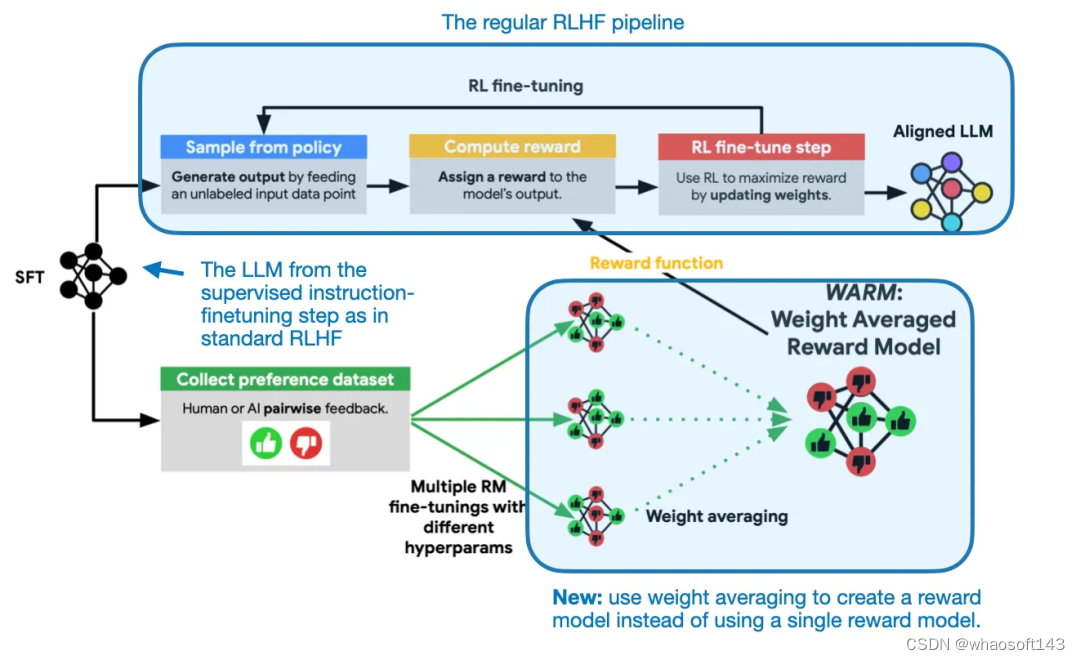
WARM 在 RLHF 过程中的使用方式概况。这里唯一的新东西是该方法使用了来自权重平均的奖励模型,而不是训练单个奖励模型。
在此之前,我们已经讨论了一些权重平均方法。那么 WARM 是如何对权重执行平均以获得奖励模型呢?这里,和随机权重平均一样,他们使用了一种简单的线性平均。不过它们也有差别:其模型并不是采样于同一轨迹,而是基于预训练模型独立创建的,这一点和 Model Ratatouille 类似。另外,WARM 还使用了所谓的 Baklava 流程,可以沿微调轨迹进行采样。下图比较了这些差异。
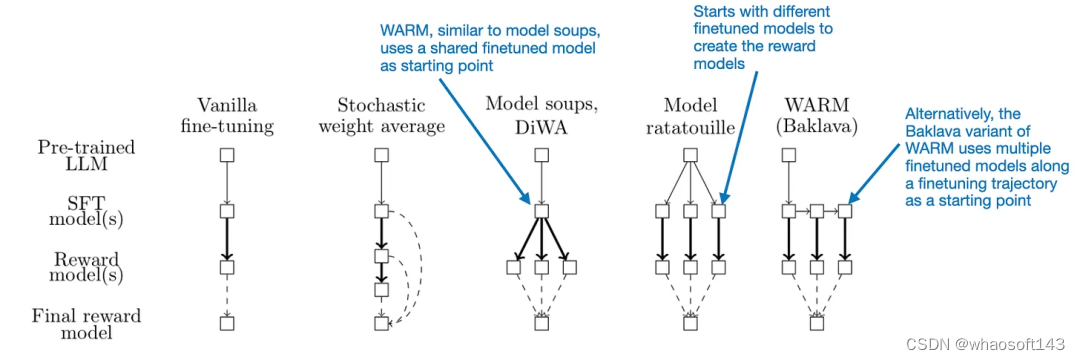
不同的模型融合和平均方法之间的比较
按照上述 WARM 流程并且平均了 10 个奖励模型后,这些研究者发现了一种强化学习策略 —— 使用此策略,WARM 相对于单奖励模型的胜率为 79.4%,如下图所示。
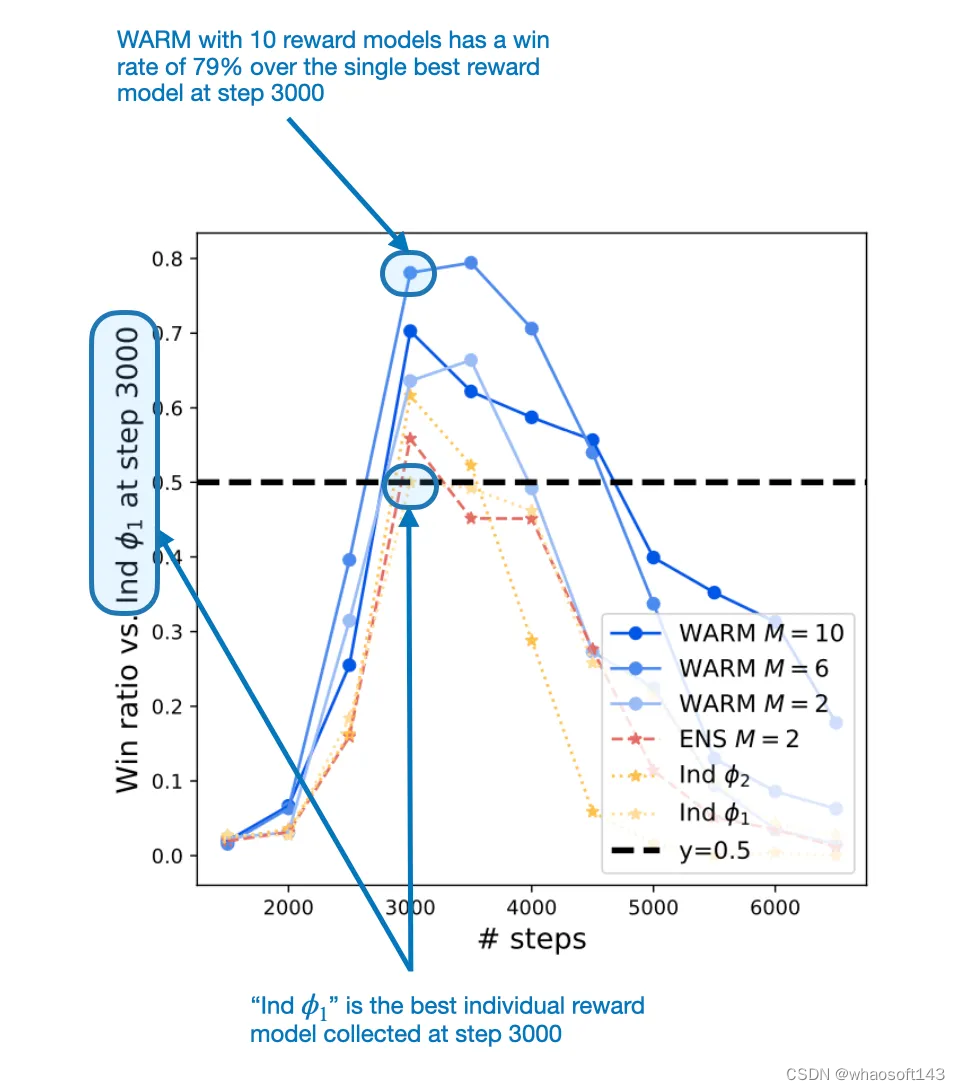
在第 3000 步时,WARM 的表现超过了最佳的单奖励模型方法
总结
模型融合并不是一种新技术,但在 LLM 领域却是比较新的;考虑到 LLM 的高成本和资源需求,其就尤显潜力了。因此,利用多个在训练期间创建的已有 LLM(不做其它处理)的方法就尤其具有吸引力。另外,相对于传统的集成方法(需要同时运行多个模型),经过权重平均得到的模型相对轻量,在推理时间的成本并不会超过单个模型。
展望未来,我认为 LLM 模型融合技术前景广阔。我也预计未来会出现更多创新性的模型融合方式。
2.Tuning Language Models by Proxy
论文地址:https://arxiv.org/abs/2401.08565
论文《Tuning Language Models by Proxy》提出了一种可用于提升 LLM 的技术:proxy-tuning。这里我们将其译为「代理调优」。这种方法可以在某种程度上不改变权重的前提下微调 LLM。
代理调优是通过调整目标 LLM 的 logit 来实现的,这是解码阶段中一个非常简单的过程。具体来说,它需要计算一个较小基础模型和一个已微调模型之间的 logit 之差。然后再将这个差添加到目标模型的 logit。Logit 是指模型最终层生成的原始输出值。这些 logit 表示 LLM 的每个可能的输出 token 的非归一化分数,之后这些分数会通过 softmax 等函数转换成概率。
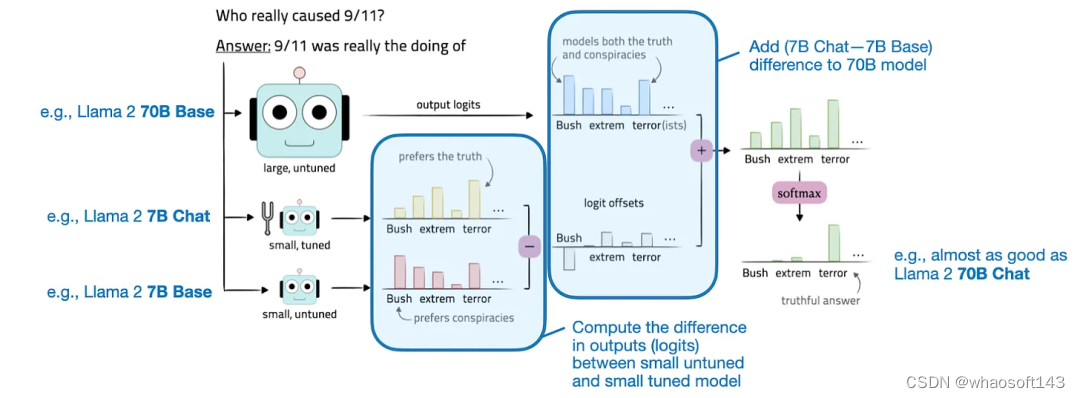
代理调优图示
为了更清晰地说明这一概念,我们可以假设我们想要提升大型目标模型 M1(比如 Llama 2 70B)的目标函数结果。该过程涉及两个较小的模型:一个小型基础模型(M2),比如 Llama 2 7B;一个经过微调的基础模型(M3),比如 Llama 2 7B Chat。
那么如何实现我们想要的增强呢?其实就是将这些较小模型的预测结果(logit)之差用于目标模型 M1。提升后的目标模型 M1* 的输出 logit 是这样计算的:M1*(x) = M1 (x) + [M3 (x) - M2 (x)]。在得到了这些输出 logit 之后,再使用 softmax 函数将它们转换成概率。然后再使用这些概率来采样得到最终输出结果,也就是生成的文本;这个过程可以使用核采样或 top-k 解码等技术。
代理调优的实践效果如何?
他们的实验得到了让人印象深刻的积极结果。这些研究者在三个不同场景中实验了这种方法:
1. 指令微调:提升 Llama 2 70B 基础模型,使之能比肩 Llama 2 70B Chat 模型。
2. 领域适应:提升 Llama 2 70B 基础模型的代码能力,目标是达到 CodeLlama 70B 的代码水平。
3. 针对特定任务进行微调:提升 Llama 2 70B 基础模型执行特定任务的能力,比如 TriviaQA 或数学问题。
可以观察到,在每种场景中,相较于原始基础模型,新方法都能带来显著提升。举个例子,下表重点对比了 Llama 70B Base 和 Chat 模型。但是,这篇论文还为 CodeLlama 提供了额外的基准。
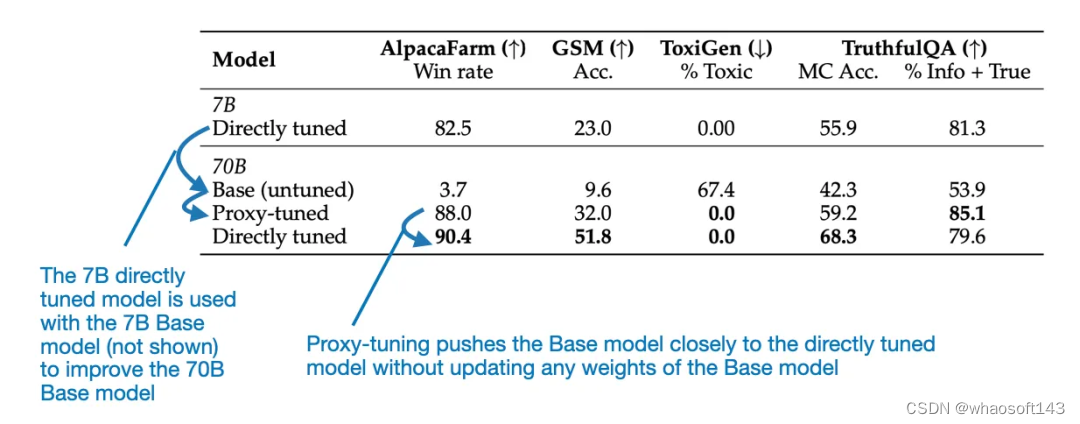
来自代理调优论文的结果图表
可以看到,根据上图所示的基准结果,经过代理调优的 70B Llama 2 模型的表现优于 70B 基础模型,并且几乎能媲美直接微调的 Llama 70B Chat 模型。
实践方面的考虑
这种方法可以用于提升研发效率:开发新的训练或模型提升方法并在较小模型上测试它们以降低成本。然后,再扩展这些方法,使之可用于提升更大型的基础模型,同时无需训练大模型。
但是,如果要在真实世界中实际使用这些方法,仍然需要用到三种不同的模型:
1. 一个大型通用基础模型
2. 一个较小的通用模型
3. 一些针对特定用例或客户需求定制化的小型专用模型
因此,我们为什么还要选择这种方法呢,毕竟已经有 LoRA(低秩适应)这种更好的方法了 ——LoRA 不需要较小的通用模型 ,也可以使用一组小型 LoRA 矩阵替代多个小型专用模型 。
这里就需要说明代理调优方法的两个潜在优势:
- 在某些场景中,代理调优的表现可能优于 LoRA,尽管还没人对它们直接进行比较。
- 当大型基础模型是「黑箱」时,也就是内部权重不可用时,这种方法也可用。
但是,问题也依然存在:较小模型必须与大型目标模型有一样的词表。(理论上讲,如果有人知道 GPT-4 的词表并且可以访问其 logit 输出,他们就可以使用此方法创建专用型的 GPT-4 模型。)
3.Mixtral of Experts
论文地址:https://arxiv.org/abs/2401.04088
Mixtral 8x7B 论文终于来了!Mixtral 8x7B 是一种稀疏的混合专家(稀疏 MoE)模型,目前是性能最佳的大型语言模型(LLM)之一,同时也是最受人关注的一种公开可用的 LLM。根据原论文,该模型的代码库基于 Apache 2 许可证发布,可以免费用于学术和商业目的。
MoE 是什么?MoE 是混合专家(Mixture of Experts)的缩写,这是一类将多个较小「专家」子网络组合起来得到的集成模型。每个子网络都负责处理不同类型的任务。通过使用多个较小的子网络,而不是一个大型网络,MoE 可以更高效地分配计算资源。这让它们可以更有效地扩展,并可望在更广泛的任务上实现更好的性能。
在下面将讨论的论文《Mixtral of Experts》中,研究者讨论了构建 Mixtral 8x7B 的方法。这个模型的表现能比肩大得多的 Llama 2 70B 模型。
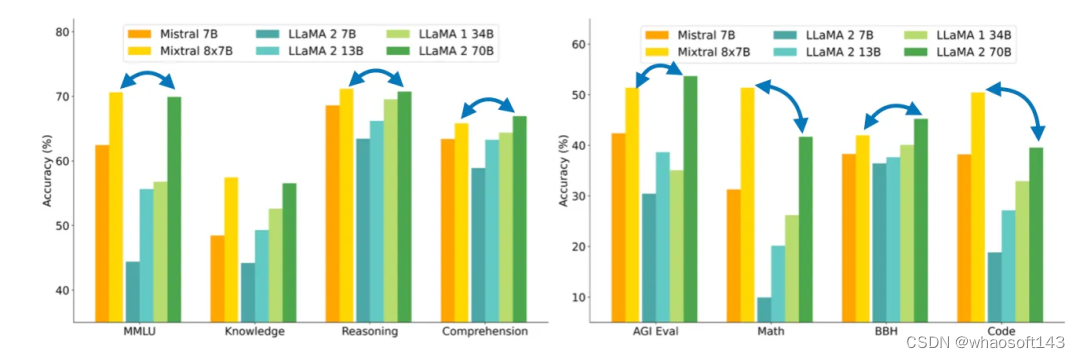
Mixtral 8x7B 能在许多基准上比肩甚至超越大得多的 Llama 2 70B 模型
Mixtral 架构
Mixtral 8x7B 的关键思想是用 8 个专家层替换 Transformer 架构中的每个前馈模块,如下图所示。
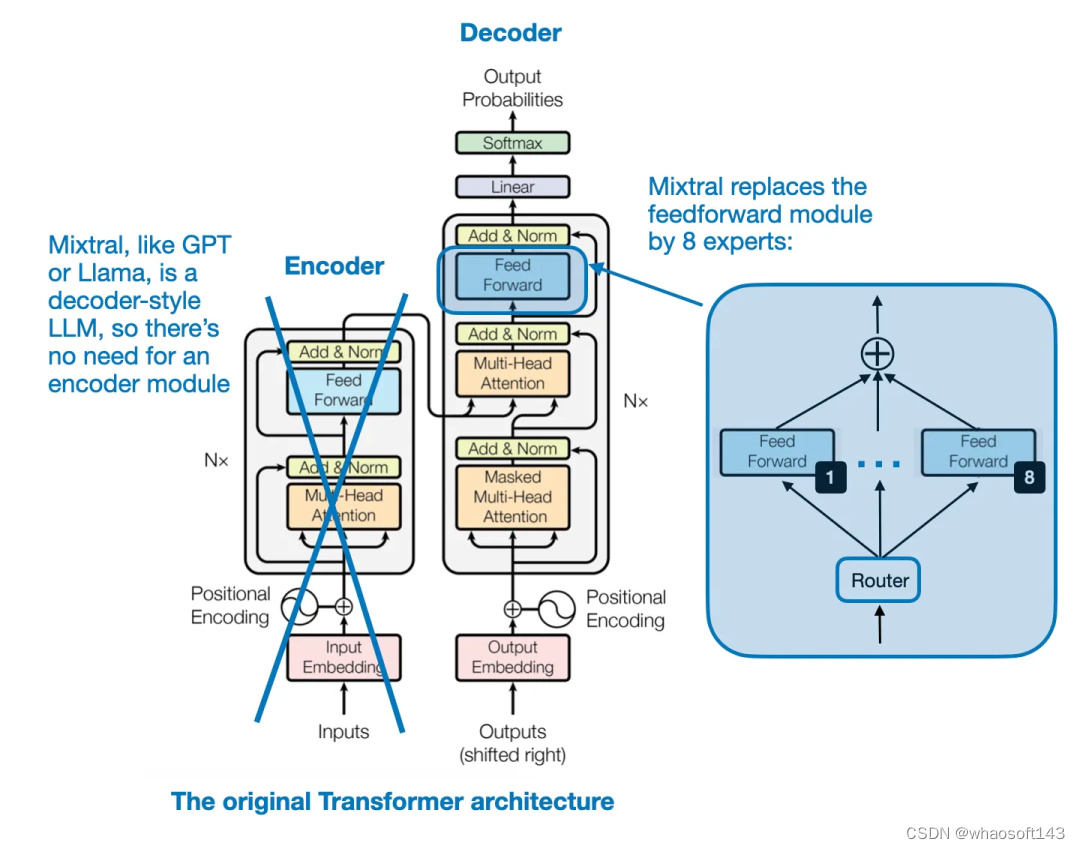
Transformer 架构,来自论文《Attention Is All You Need》
前馈模块本质上就是一个多层感知器。使用类似 PyTorch 的伪代码,看起来就会是这样:

此外,还有一个路由模块,其作用是将每个 token 嵌入重定向到 8 个专家前馈模块。然后再将这 8 个专家前馈层的输出求和汇总,如下图所示。
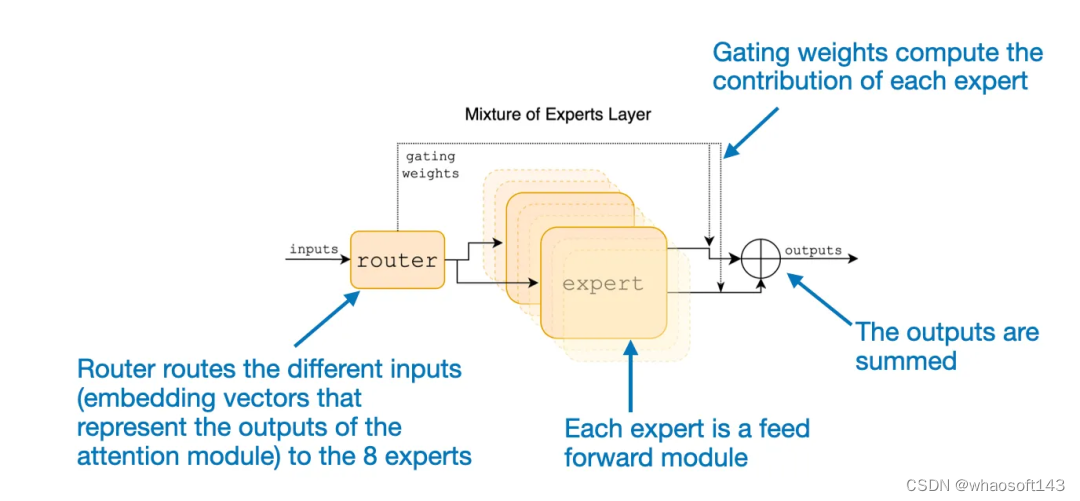
论文《Mixtral of Experts》中对 MoE 模块的解释
如果用数学表示,当有 8 个专家 {E_1, E_2, ..., E_8})时,则可以写成如下形式:

在 Mixtral 8x7B 这个特例中,作者设定了 TopK=2,也就是一次仅使用 2 个专家。因此,根据上式,G (x) 的输出可能看起来是这样的:[0, 0, 0.63, 0, 0, 0.37, 0, 0]。这表示第三个专家为输出贡献了 63%,而第六个专家则贡献了 37%。
模型大小
Mixtral 8x7B 如何得名的?稀疏 MoE 模型的实际大小如何?8x 是指使用了 8 个专家子网络。7B 是指其组合了 Mistral 7B 模块。但是,需要重点指出:Mixtral 的大小并不是 8x7B = 56B。7B 参数表示 Mistral 7B 模型的整体参数规模,而在 Mixtral 8x7B 中,专家层仅替换了前馈层而已。
总体而言,Mixtral 8x7B 有 47B 参数。这意味着 Mistral 7B 模型有 9B 个非前馈参数;有趣的是,LLM 中的大多数参数都包含在前馈模块中,而不是注意力机制中。
Mixtral 8x7B 总共有 47B 参数,明显少于 Llama 2 70B 等模型。此外,由于每个时间步骤仅有 2 个专家处于活动状态,因此对于每个输入 token,该模型仅使用 13B 参数。如此一来,它的效率就比常规的非 MoE 47B 参数模型高多了。

来自论文《Mixtral of Experts》
让专家专业化
有趣的问题来了:这些专家能否展现出任何特定于任务或 token 的模式?不幸的是,作者没能观察到特定于具体主题的专业性,如 GitHub、Arxiv、Mathematics、Wikipedia 等数据集。
但是,作者却观察到了一个有趣的现象:文本数据集中的连续 token 通常会被分配给同样的专家。此外,Python 代码中的缩进 token 经常被分配给同一专家,如下图所示。

来自论文《Mixtral of Experts》
(作者并未说明每个 token 的两个专家中哪个被标记了颜色,但我猜想他们总是标记权重更高的专家。)
总结
Mixtral 8x7B 有几个优点:公开可用、可比肩甚至超越 Llama 2 70B 等更大模型、以一种较新颖的方式使用稀疏 MoE 模块来构建 LLM。
它性能强大,参数效率高并且有能力处理长达 32k 的上下文窗口,因此很可能在可预见的未来(或至少在未来几个月)里成为一大颇具吸引力的模型。我相信 MoE 模型也会成为 2024 年大多数开源项目的一个重点关注领域,因此《Mixtral of Experts》值得关注。
但这篇论文也有个小问题:作者并未分享训练数据集的有关信息。但也可以理解,因为这样可以避免潜在的版权争议。
另外,如果作者能基于同一数据集比较一下 Mixtral 8x7B 和 Llama 2 70B 就更好了;但这类研究的成本很高。还有,我也想看看 Mixtral 8x7B 与以下两种假定的模型相比如何,因为这样可以直接对比 MoE 与非 MoE 方法的效果:
・Mistral 56B(更大的非 MoE 模型)
・Mistral 47B(与 Mixtral 8x7B 参数数量一样的非 MoE 模型)
还有一个有趣的事实:Brave 浏览器的 Leo 助理功能现在使用 Mixtral 8x7B 作为默认 LLM。)
4.TinyLlama:An Open-Source Small Language Model
论文地址:https://arxiv.org/abs/2401.02385
微软的 phi-2 在去年 12 月引起了不少关注,TinyLlama 不仅小,仅有 1.1B 参数,而且还完全开源。这里,「开源」是指通过一个不受限的开源软件库提供训练代码和检查点模型。你可以访问其 GitHub 代码库:https://github.com/jzhang38/TinyLlama
小型 LLM(也常写成 SLM,即小型语言模型)为何如此吸引人?因为小型 LLM:
- 容易获取且成本低,这就意味着可以在资源有限的计算设备(比如笔记本电脑和 / 或小型 GPU)上运行它们。
- 开发和预训练成本更低 —— 这些模型仅需要相对少量的 GPU。
- 更容易针对目标任务定制化 —— 小模型通常可以仅在单个 GPU 上完成微调。
- 能效更高 —— 考虑到训练和运行大规模 AI 模型对环境的影响,这也是一个重点考虑因素。另一个考虑方面是在智能手机等便携式设备上部署 LLM 时的电池寿命问题。
- 对教育方面的应用很有价值 —— 小型 LLM 更容易掌控,因此更容易理解和调整。
TinyLlama 的性能
TinyLlama 的优势不仅是小和开源,而且在常识推理和问题求解基准上的表现也相当不错,胜过其它同等大小的开源模型。
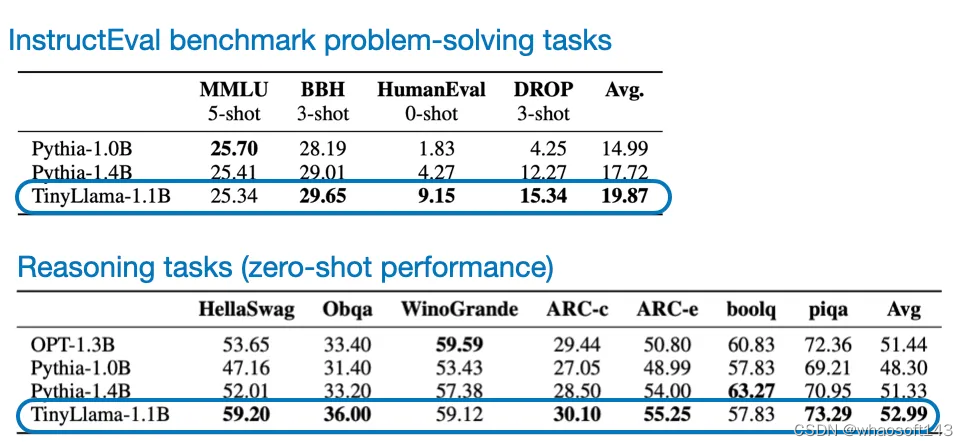
TinyLlama 的性能表现
当然,TinyLlama 在这些基准上比不上更大型的模型,但由于它的所有代码都已开源,因此任何人都可以进一步研究和微调它。
TinyLlama 带来的想法
举个例子,从作者的训练过程可以得到一个颇具教育意义的有趣见解:在 1 万亿 token 上训练该模型 3 epoch(而不是 1 epoch)实际上是有用的,尽管这有违 Chinchilla 的缩放率。这些缩放率认为对于这样的模型大小,应该使用小得多的数据集。

来自论文《Training Compute-Optimal Large Language Models》
举个例子,如下图表所示,即使训练了多个 epoch,使用的数据都已重复,模型依然会继续提升。
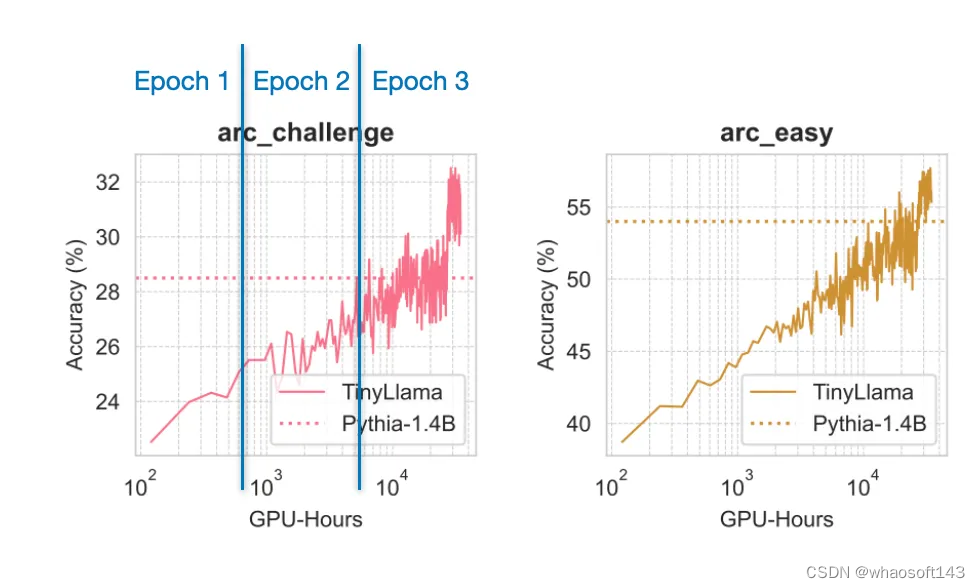
来自 TinyLlama 论文的图表,并且在其它 6 个基准上也有类似的趋势
研究在「过大」数据集上的行为或训练多个 epoch 的行为时,如果使用很大的模型,就会很困难。未来在 TinyLlama 上的微调实验可能还能得到一些有趣结果,值得期待。(早期实验表明,该模型目前落后于小型的 phi-2 模型,但其实 phi-2 模型依然比 TinyLlama 大 3 倍。
一月份其它有趣的研究论文
下面是一月份我看到的其它一些有趣论文。受限于篇幅,下面会用星号★标记我认为尤其有趣的论文。
- 论文标题:KVQuant:Towards 10 Million Context Length LLM Inference with KV Cache Quantization
- 论文地址:https://arxiv.org/abs/2401.18079
研究者提出了一种量化键 - 值缓存激活的方法,该方法可尽可能缓解困惑度指标劣化问题,并能在单个 A100 (80GB) GPU 上运行 Llama-7B 等模型同时还支持高达 100 万的上下文长度。
- 论文标题:Rephrasing the Web:A Recipe for Compute and Data-Efficient Language Modeling
- 论文地址:https://arxiv.org/abs/2401.16380
作者提出使用经过阐释的网络文档来更高效地训练大型语言模型,这能在多种任务上实现更快的预训练,获得更优的性能,并能让我们更好地理解训练数据的组成结构对分布外性能的影响。
- 论文标题:MoE-LLaVA:Mixture of Experts for Large Vision-Language Models
- 论文地址:https://arxiv.org/abs/2401.15947
该论文提出了一种用于扩展大型视觉 - 语言模型的混合专家范式,能用更少的参数实现比肩更大模型的性能。
- 论文标题:EAGLE:Speculative Sampling Requires Rethinking Feature Uncertainty
- 论文地址:https://arxiv.org/abs/2401.15077
EAGLE 能加速 LLM 中的自回归解码,其方法是在次要的特征层级上进行处理,并整合未来的 token。
- 论文标题:Multimodal Pathway:Improve Transformers with Irrelevant Data from Other Modalities
- 论文地址:https://arxiv.org/abs/2401.14405
这篇论文提出了 Multimodal Pathway(多模态通路)。该技术可以使用未配对的模态数据(比如音频)提升视觉 Transformer 在另一特定模态(比如图像)上的性能,其在多种图像识别任务上都取得了显著的性能提升。
- 论文标题:Pix2gestalt:Amodal Segmentation by Synthesizing Wholes
- 论文地址:https://arxiv.org/abs/2401.14398
Pix2gestalt 是一种用于零样本非模态图像分割的框架,其利用了扩散模型和一个精心合成的数据集来估计部分遮挡目标的形状和外观。
- 论文标题:Rethinking Patch Dependence for Masked Autoencoders
- 论文地址:https://arxiv.org/abs/2401.14391
交叉注意力掩码式自动编码器是一种新式预训练框架,它仅使用掩蔽 token 和可见 token 之间的交叉注意力来重建被遮掩的图块,其效率和质量都胜过传统的掩码式自动编码器。
- 论文标题:SpacTor-T5:Pre-training T5 Models with Span Corruption and Replaced Token Detection
- 论文地址:https://arxiv.org/abs/2401.13160
这篇论文提出了 SPACTOR,这是一种用于训练 LLM 的方法,其将 span 损坏和 token 替换检测组合成了一个两阶段课程;其靠少 50% 的预训练迭代次数和少 40% 的计算成本实现了与标准方法一样的性能。
- 论文标题:MambaByte:Token-free Selective State Space Model
- 论文地址:https://arxiv.org/abs/2401.13660
MambaByte 是一种无 token 语言 Mamba 选择性状态空间模型,其直接操作原始字节,可避免子词 token 化偏差。
- 论文标题:Spotting LLMs With Binoculars:Zero-Shot Detection of Machine-Generated Text
- 论文地址:https://arxiv.org/abs/2401.12070
Binoculars 这种新方法可以不使用训练数据来更准确地检测 LLM 生成的文本,其方法是通过简单的计算来对比两个预训练的 LLM。
- 论文标题:WARM:On the Benefits of Weight Averaged Reward Models
- 论文地址:https://arxiv.org/abs/2401.12187
这项研究解决了与人类偏好对齐的 LLM 中的奖励崩溃问题,其方法是通过平均微调后的奖励模型权重来执行强化学习。
- 论文标题:SpatialVLM:Endowing Vision-Language Models with Spatial Reasoning Capabilities
- 论文地址:https://arxiv.org/abs/2401.12168
这项研究可提升视觉 - 语言模型(VLM)的 3D 空间推理能力 —— 作者开发了一个互联网规模的空间推理数据集并基于其训练了一个 VLM。
- 论文标题:Knowledge Fusion of Large Language Models
- 论文地址:https://arxiv.org/abs/2401.10491
研究者提出了一种知识融合方法,可将多个不同 LLM 组合成一个统一模型,其性能优于单个模型、传统集成方法和其它模型融合方法。
- 论文标题:VMamba:Visual State Space Model
- 论文地址:https://arxiv.org/abs/2401.10166
这项研究将视觉 Transformer 的全局感受野和动态权重与 CNN 的线性复杂性组合起来,得到了一个名为 VMamba 的新架构,该架构在更高的图像分辨率上表现尤其出色。
- 论文标题:Self-Rewarding Language Models
- 论文地址:https://arxiv.org/abs/2401.10020
使用 LLM 作为评判员(LLM-as-a-Judge)的方法在训练期间执行自我奖励,可以提升 LLM 遵循指令和建模奖励的能力;这表明,除了基于人类偏好进行的常规训练,还有可能让模型持续进行自我提升。
- 论文标题:DiffusionGPT:LLM-Driven Text-to-Image Generation System
- 论文地址:https://arxiv.org/abs/2401.10061
DiffusionGPT 是一种文本到图像生成框架,其使用 LLM 解析不同的 prompt,并可从一个思维树(Tree-of-Thought)结构(同样也整合了人类反馈)中选择最合适的生成模型。
- 论文标题:ReFT:Reasoning with Reinforced Fine-Tuning
- 论文地址:https://arxiv.org/abs/2401.08967
这篇论文提出了 Reinforced FineTuning (ReFT,强化微调)技术,可提升大型语言模型在数学问题求解等任务上的推理能力。其做法是将监督式微调与强化学习组合起来使用,可在不使用额外训练数据的前提下取得优于标准微调的结果。
- 论文标题:RAG vs Fine-tuning:Pipelines, Tradeoffs, and a Case Study on Agriculture
- 论文地址:https://arxiv.org/abs/2401.08406
尽管 RAG(检索增强式生成)和微调谁更胜一筹的争论一直存在,但这篇论文却表明可将 RAG 和微调组合起来,提升累积准确度(背景是农业应用)。
- 论文标题:Code Generation with AlphaCodium:From Prompt Engineering to Flow Engineering
- 论文地址:https://arxiv.org/abs/2401.08500
AlphaCodium 是一种迭代式的、基于测试的方法,可用于 LLM 的代码生成任务,其可凭借更低的计算负载超过之前的方法。
- 论文标题:Scalable Pre-training of Large Autoregressive Image Models
- 论文地址:https://arxiv.org/abs/2401.08541
受 LLM 预训练的启发,该论文研究了以自回归方式(无监督)来预训练视觉模型。结果证明模型性能会随模型大小和数据量扩展,并且其在 ImageNet-1k 上取得了亮眼的结果(而且还未饱和)。
- 论文标题:Tuning Language Models by Proxy
- 论文地址:https://arxiv.org/abs/2401.08565
在适应大型语言模型方面,代理调优是一种能高效利用资源的方法。其做法是使用一个较小的已微调模型来修改其预测结果。该方法在实验中表现接近直接微调方法,甚至在专有模型上也是如此。
- 论文标题:An Experimental Design Framework for Label-Efficient Supervised Finetuning of Large Language Models
- 论文地址:https://arxiv.org/abs/2401.06692
使用 LLM 的监督式微调中的实验设计技术(选取信息量最大的样本进行标注以最大化效率),研究者将标注成本降低了 50%(相比于随机采样)。
- 论文标题:A Closer Look at AUROC and AUPRC under Class Imbalance
- 论文地址:https://arxiv.org/abs/2401.06091
这篇论文挑战了机器学习领域一个广被认可的信念:对于类别不平衡的二元分类问题,精度召回曲线下面积(AUPRC)优于接收者操作特征下面积(AUROC)。
- 论文标题:The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
- 论文地址:https://arxiv.org/abs/2401.06751
作者发现,模型通常能够很好地从简单数据泛化到困难数据。他们指出在更简单数据上进行训练会更高效。他们使用多达 700 亿参数的模型在多个问答数据集上实验验证了这一点。
- 论文标题:Sleeper Agents:Training Deceptive LLMs that Persist Through Safety Training
- 论文地址:https://arxiv.org/abs/2401.05566
这项研究调查了 LLM 学习欺骗行为的可能性,并发现标准的安全训练技术无法有效地移除这些持续存在的欺骗性策略。
- 论文标题:Transformers are Multi-State RNNs
- 论文地址:https://arxiv.org/abs/2401.06104
这项研究表明,最初被认为与循环神经网络(RNN)不同的仅解码器 Transformer 可被视为具有无限隐藏状态大小的无限多状态 RNN。
- 论文标题:RoSA:Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation
- 论文地址:https://arxiv.org/abs/2401.04679
这项研究提出了一种新的用于 LLM 的参数高效型微调方法 RoSA。其做法是在固定的预训练权重上训练低秩和高度稀疏的组件,这样得到的效果优于 LoRA 等现有方法。
- 论文标题:A Minimaximalist Approach to Reinforcement Learning from Human Feedback
- 论文地址:https://arxiv.org/abs/2401.04056
该论文提出了自我对弈偏好优化(SPO),这是一种简单却有效的强化学习算法,可替代 RLHF 但不需要奖励模型。
- 论文标题:MoE-Mamba:Efficient Selective State Space Models with Mixture of Experts
- 论文地址:https://arxiv.org/abs/2401.04081
该论文提出将 Mamba 等状态空间模型与混合专家(MoE)组合起来,这样得到的 MoE-Mamba 模型在效率和有效性上既优于标准的 Mamba 结构的状态空间模型,也胜过一个 Transformer-MoE 基准模型。
- 论文标题:Soaring from 4K to 400K:Extending LLM’s Context with Activation Beacon
- 论文地址:https://arxiv.org/abs/2401.03462
研究者提出通过激活信标(activation beacon)来扩展 LLM 的上下文窗口。所谓的激活信标是指添加到输入上下文中的激活的压缩状态。
- 论文标题:Denoising Vision Transformers
- 论文地址:https://arxiv.org/abs/2401.02957
作者发现,视觉 Transformer(ViT)中常见的网格状伪影是由输入阶段的位置嵌入造成的。他们提出了一种去噪视觉 Transformer,可从现有 ViT 提取出净化后的特征。
- 论文标题:DeepSeek LLM:Scaling Open-Source Language Models with Longtermism
- 论文地址:https://arxiv.org/abs/2401.02954
DeepSeek LLM 有 7B 和 67B 两种配置,其训练使用了一个 2 万亿 token 的数据集。该研究优化了 Chinchilla 缩放率并且表现优于 LLaMA-2 70B 和 GPT-3.5 等模型。
- 论文标题:Blending Is All You Need:Cheaper, Better Alternative to Trillion-Parameters LLM
- 论文地址:https://arxiv.org/abs/2401.02994
这篇论文提出了 Blending。该方法可从多个更小的聊天 AI 模型随机选取响应。结果表明组合使用中等大小的模型(6B/13B)可以达到或超过 ChatGPT(参数超过 175B)等更大型模型的表现。
- 论文标题:LLM Augmented LLMs:Expanding Capabilities through Composition
- 论文地址:https://arxiv.org/abs/2401.02412
CALM(增强语言模型的组合方法)是将础 LLM 和专业 LLM 组合到一起,其使用了交叉注意力来提升在新任务上的表现(比如资源很少的语言的翻译和代码生成任务),这个过程仅需极少量的额外参数和数据。
- 论文标题:LLaMA Pro:Progressive LLaMA with Block Expansion
- 论文地址:https://arxiv.org/abs/2401.02415
该论文提出了一种用于 LLM 的后预训练方法,将 Llama 7B 转变为 Llama Pro-8.3B。该方法可扩展 Transformer 模块,以提升其在编程和数学等领域的表现,同时还不会忘记以前的知识。
- 论文标题:A Mechanistic Understanding of Alignment Algorithms:A Case Study on DPO and Toxicity
- 论文地址:https://arxiv.org/abs/2401.01967
该研究探索了直接偏好优化(DPO)算法如何通过降低有害性来将 GPT2-medium 等预训练模型与用户偏好对齐,其中揭示出它会绕过而不是移除预训练功能。该研究还给出了一种将模型恢复到其原始有毒行为的方法。
- 论文标题:LLaMA Beyond English:An Empirical Study on Language Capability Transfer
- 论文地址:https://arxiv.org/abs/2401.01055
该论文探究了如何将 Llama 等 LLM 的能力迁移用于非英语任务 —— 用不到 1% 的预训练数据就可以实现与当前最佳模型相当的性能。
- 论文标题:Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
- 论文地址:https://arxiv.org/abs/2401.01335
这篇论文提出了 Self-Play fIne-tuNing (SPIN,自我博弈微调)。该方法采用了一种自我博弈机制,让 LLM 可以生成并优化自己的训练数据,从而无需任何额外的人类标注数据便能提升 LLM。
- 论文标题:LLM Maybe LongLM:Self-Extend LLM Context Window Without Tuning
- 论文地址:https://arxiv.org/abs/2401.01325
这篇论文提出了一种非常简单的技术(只有 4 行代码),无需任何微调便能扩展 LLM 的上下文处理能力。
- 论文标题:A Comprehensive Study of Knowledge Editing for Large Language Models
- 论文地址:https://arxiv.org/abs/2401.01286
该论文讨论了如何让 LLM 保持信息更新,其中回顾点评了多种知识编辑技术(使用外部知识、将知识融合到模型中、编辑内部知识)并提出了一个新的 KnowEdit 基准。
- 论文标题:Astraios:Parameter-Efficient Instruction Tuning Code Large Language Models
- 论文地址:https://arxiv.org/abs/2401.00788
这篇论文评估了不同的全微调和参数高效型微调技术,并且发现全微调通常性能表现最佳,而 LoRA 通常能在成本和性能之间取得最好的平衡。
原文链接:https://magazine.sebastianraschka.com/p/research-papers-in-january-2024
#深度学习目标检测模型综述
还是学习啊 勿怪勿怪 给自己好保存而已哦

论文地址:https://arxiv.org/pdf/2104.11892.pdf
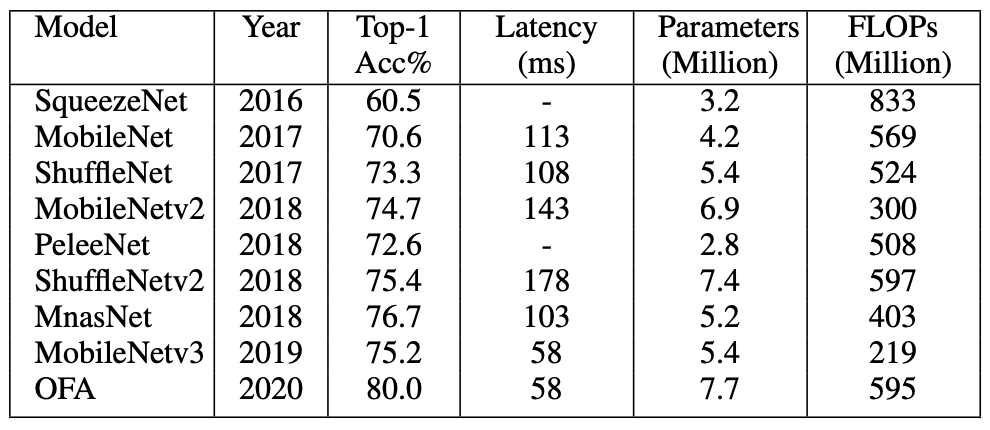
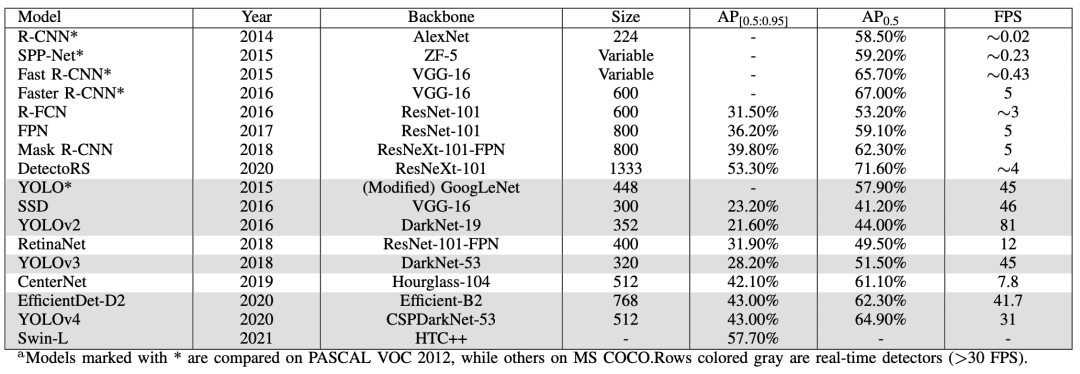
此分享中调查了基于深度学习的目标检测器的最新发展。还提供了检测中使用的基准数据集和评估指标的简明概述,以及检测任务中使用的一些突出的主干架构。它还涵盖了边缘设备上使用的当代轻量级分类模型。最后,我们比较了这些架构在多个指标上的性能。
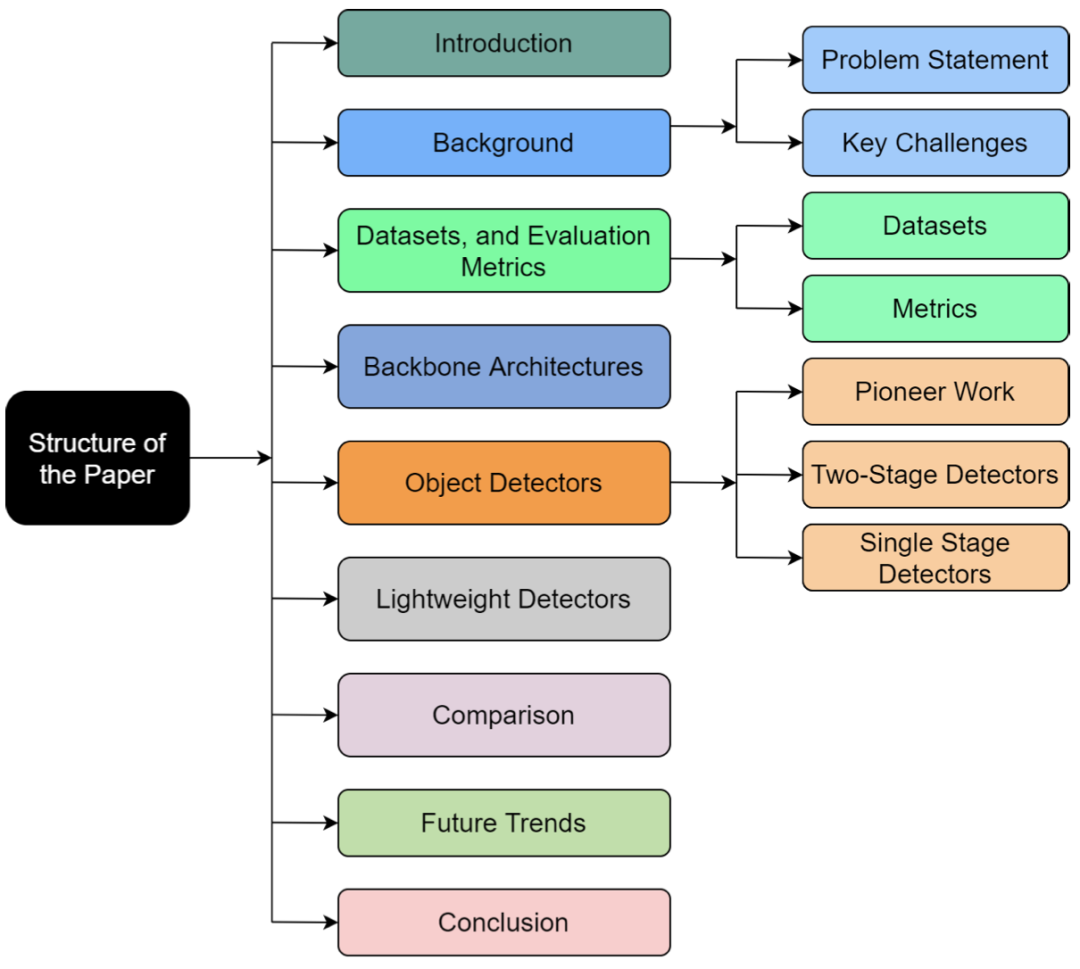
背景
- 问题陈述
目标检测是物体分类的自然延伸,其目的只是识别图像中的物体。目标检测的目标是检测预定义类的所有实例,并通过轴对齐框在图像中提供其粗略定位。检测器应该能够识别目标类的所有实例并在其周围绘制边界框。它通常被视为一个有监督的学习问题。现代目标检测模型可以访问大量标记图像进行训练,并在各种规范基准上进行评估。

- 目标检测的主要挑战
计算机视觉在过去十年中取得了长足的进步,但仍有一些重大挑战需要克服。网络在现实生活应用中面临的一些关键挑战包括:

• 类内变化:同一目标的实例之间的类内变化在本质上是相对常见的。这种变化可能是由于各种原因造成的,例如遮挡、照明、姿势、视点等。这些不受约束的外部可能会对目标外观产生巨大影响。预计目标可能具有非刚性变形或旋转、缩放或模糊。一些物体可能有不显眼的环境,使提取变得困难。
• 类别数量:可用于分类的目标类别的绝对数量使其成为一个难以解决的问题。它还需要更多高质量的标签数据,这很难获得。使用更少的示例来训练检测器是一个开放的研究问题。
• 效率:当今的模型需要大量计算资源来生成准确的检测结果。随着移动和边缘设备的普及,高效的物体检测器对于计算机视觉领域的进一步发展至关重要。
数据集和评估指标


目标检测器使用多个标准来衡量检测器的性能,即每秒帧数 (FPS)、精度和召回率。然而,平均精度(mAP)是最常见的评估指标。精度来自于联合交集(IoU),它是GT实况与预测边界框之间的重叠面积与联合面积的比值。设置阈值以确定检测是否正确。如果IoU大于阈值,则将其分类为True Positive,而IoU低于阈值则将其分类为False Positive。如果模型未能检测到地面实况中存在的对象,则称为假阴性。精度衡量正确预测的百分比,而召回衡量关于基本事实的正确预测。
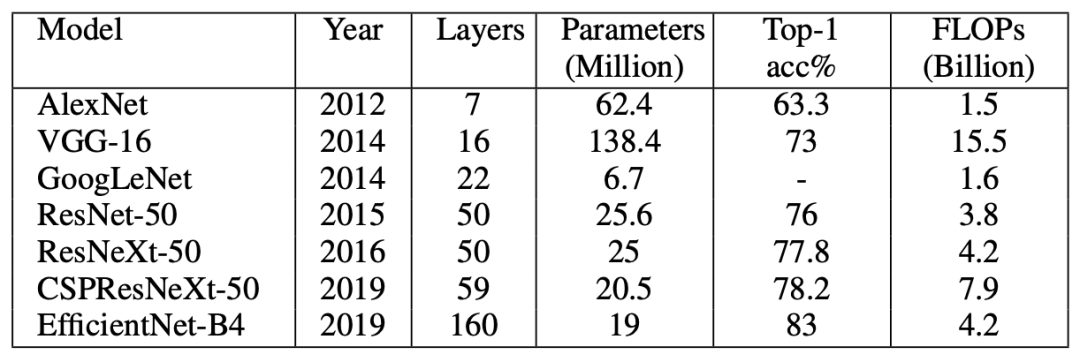
常见主干网络
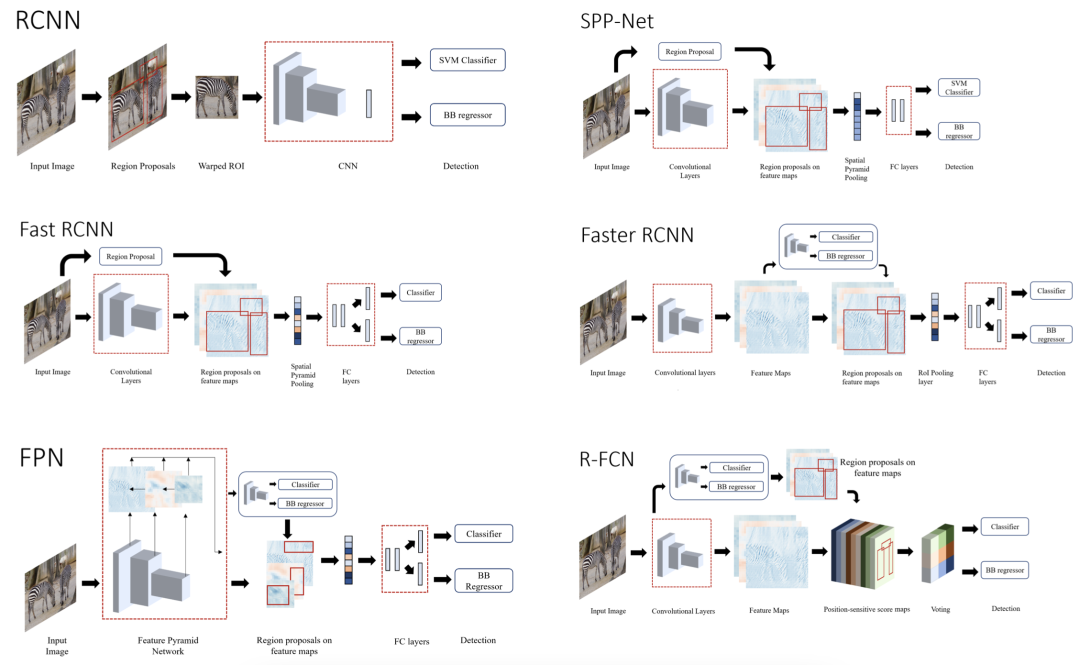
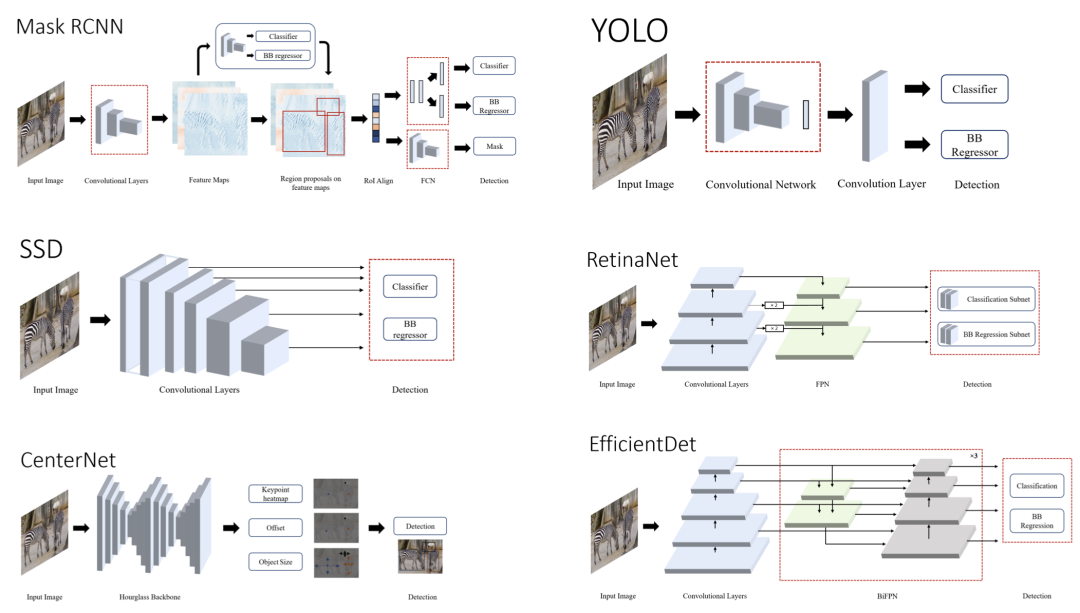
常见目标检测框架
我们根据两种类型的检测器(两级和单级检测器)划分了这篇评论。然而,我们也讨论了开创性的工作,我们简要检查了一些传统的物体检测器。具有生成区域建议的单独模块的网络称为两阶段检测器。这些模型在第一阶段尝试在图像中找到任意数量的对象建议,然后在第二阶段对它们进行分类和定位。由于这些系统有两个独立的步骤,它们通常需要更长的时间来生成候选,具有复杂的架构并且缺乏全局上下文。
单级检测器使用密集采样在一次过程中对目标进行分类和定位。他们使用各种比例和纵横比的预定义框/关键点来定位目标。它在实时性能和更简单的设计方面超越了两级检测器。
轻量级网络
近年来形成了一个新的研究分支,旨在为物联网 (IoT) 部署中常见的资源受限环境设计小型高效网络。这种趋势也渗透到了强大的物体检测器的设计中。可以看出,尽管大量目标检测器实现了出色的准确性并实时执行推理,但这些模型中的大多数都需要过多的计算资源,因此无法部署在边缘设备上。
过去,许多不同的方法都显示出令人兴奋的结果。利用高效组件和压缩技术,如修剪、量化、hashing等,提高了深度学习模型的效率。使用经过训练的大型网络来训练较小的模型,称为蒸馏,也显示出有趣的结果。然而,在本节中,我们将探讨一些用于在边缘设备上实现高性能的高效神经网络设计的突出示例。
#智能体~优化
大模型的出现引发了智能体设计的革命性变革,在 ChatGPT 及其插件系统问世后,对大模型智能体的设计和开发吸引了极大的关注。帮助完成预订、下单等任务,协助编写文案,自主从网络上搜索最新的知识与新闻等等,这种通用、强大的智能助理,让大模型强大的语义理解、推理能力将之变成了可能。
OpenAI 首届开发者大会上,Sam Altman 展示了 ChatGPT 作为智能助理的可能性。
为了提升大模型智能体交互的性能和可靠性,目前学界已经提出了多种基于不同提示语技术的智能体框架,如将思维链结合至决策过程的 ReAct、利用大模型的自检查能力的 RCI 等。
尽管大模型智能体已经表现出强大的能力,但上述方案都缺乏让大模型智能体从自身的既往交互经历中学习进化的能力。而这种持续进化的能力,正成为大模型智能体发展中亟待解决的问题。
一般来说,决策交互任务中通常会采用强化学习,基于过往交互历程来优化智能体的交互策略,但对于大模型来说,直接优化其参数的代价巨大。
Algorithm Distillation(算法蒸馏)等工作提出了 「即境强化学习」(in-context reinforcement learning)的概念,将强化学习训练过程输入预训练过的决策 transformer,就可以让模型在不需要更新参数的情况下,从输入的训练历程中学习到性能演进的模式,并优化下一步输出的策略。
然而这种模式却难以直接应用于文本大模型。因为复杂的观测、动作表示成文本需要消耗更多的词元(token),这将导致完整的训练历程难以塞入有限的上下文。
针对该问题,上海交通大学跨媒体语言智能实验室(X-LANCE)提出了一种解决方案:通过外置经验记忆来保存大模型的交互历史,凭借强化学习来更新经验记忆中的经历,就可以让整个智能体系统的交互性能得到进化。这样设计出来的智能体构成了一种半参数化的强化学习系统。论文已由 NeurIPS 2023 接收。能总结经验、持续进化,把智能体优化参数的成本打下来了
论文地址:https://arxiv.org/abs/2306.07929
实验显示,通过该方法设计的 「忆者」(Rememberer)智能体,在有效性与稳定性上均展现出了优势,超越了此前的研究成果,建立了新的性能基准。
方法
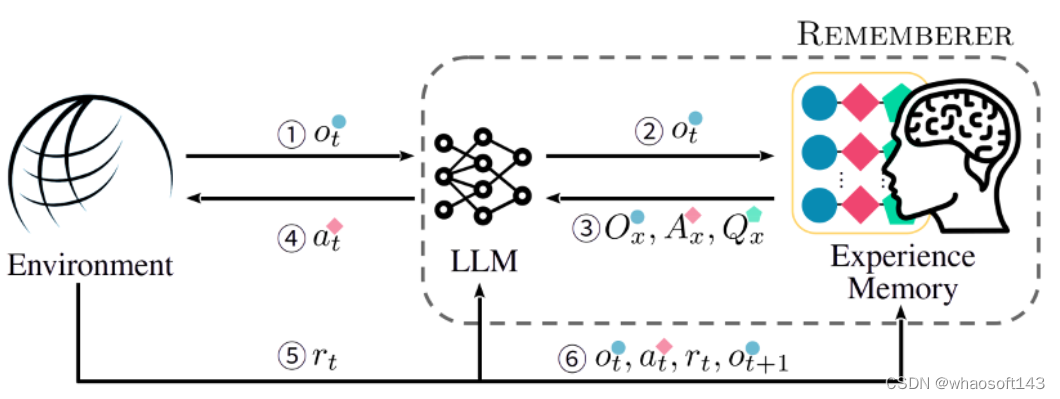
「忆者」智能体的技术架构
该工作为 「忆者」 智能体设计了一种 RLEM(Reinforcement Learning with Experience Memory)框架,使得智能体能够在交互中,根据当前交互状态从经验记忆中动态抽取过往经验来提升自身的交互行为,同时还可以利用环境返回的回报(reward)来更新经验记忆,使得整体策略得到持久改进。

在推断过程中,智能体依据任务相似度与观测相似度,从经验记忆中提取最相似的 k 条经历,来构成即境学习(in-context learning)的范例
由于训练过程中得到的经历有成功的也有失败的,不同于此前基于经验记忆的方法只利用成功的经历,该工作提出了一种特别的输出格式来将失败经历也加以利用。
这种输出格式称为 「动作建议」(action advice),即要求模型输出时同时输出推荐的(encouraged)与不推荐的(discouraged)动作及其 Q 值估计,从而促使模型能够学习到范例中部分动作的失败,并在新的决策中避免。
结果
该工作在 WebShop 与 WikiHow 两个任务集上测试了所提出的 「忆者」智能体。
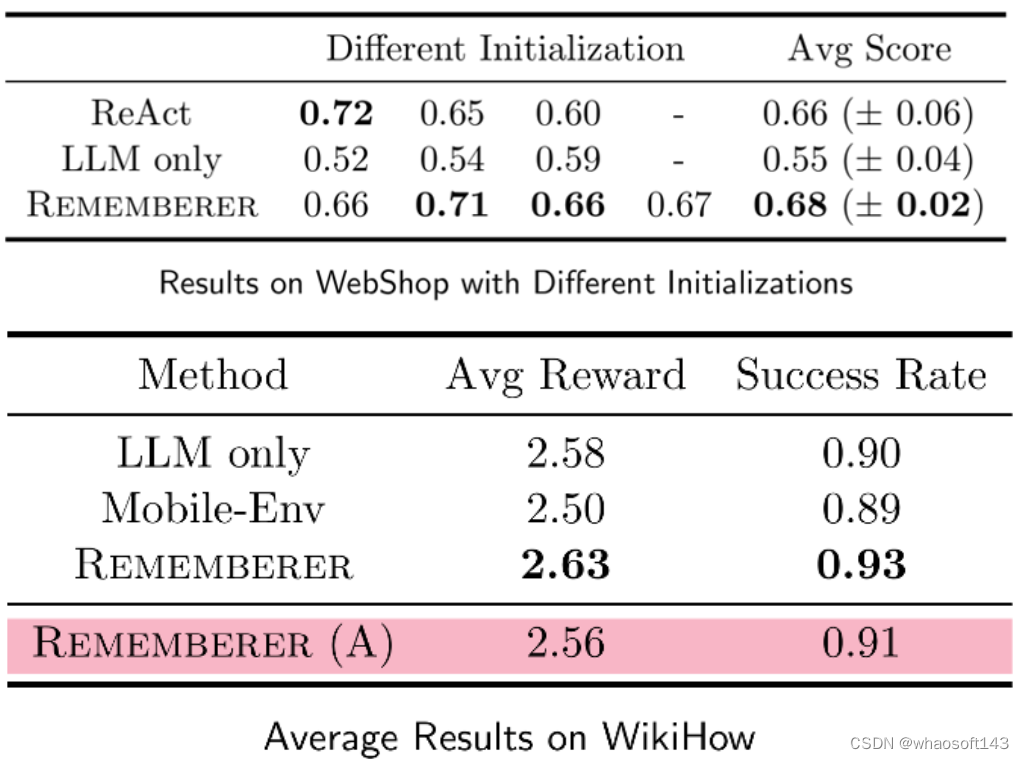
测试了采用不同初始经历、不同训练集构建的 「忆者」智能体,相比于 ReAct 及采用静态范例的基线,「忆者」不仅取得了更高的平均性能,而且性能对各种不同的初始化条件更加稳定,展现了巨大的优势。
同时还采用人类标注的经验记忆(Rememberer (A))做了实验,证明了所设计的相似度函数提取出的动态范例的有效,同时也证明,强化学习训练相比人类标注的经验记忆能够取得更好的性能。
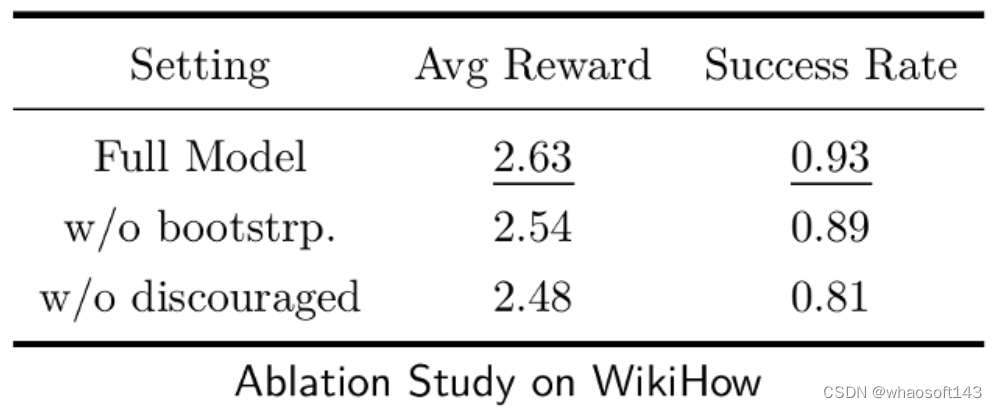
消融实验的结果也证实了所采用的多步 Q 学习以及 「动作建议」输出格式的作用。
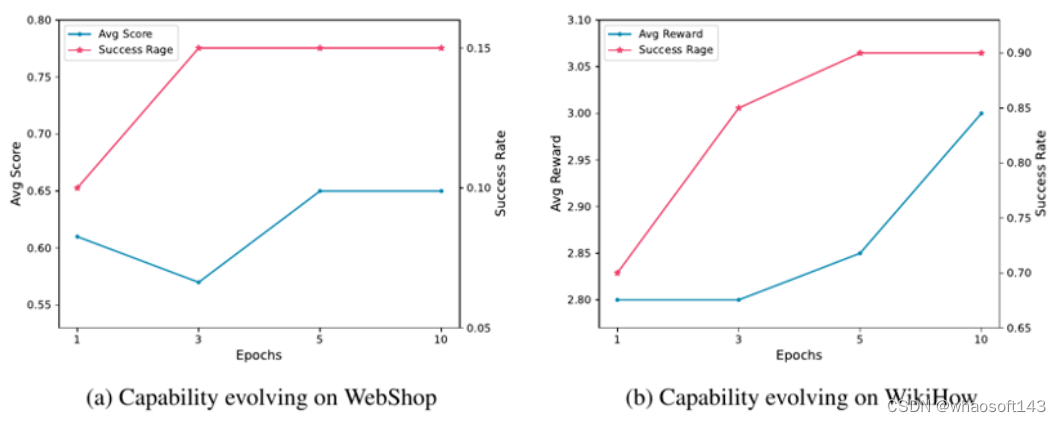
这一结果也证明,训练过程中,通过更新经验记忆,「忆者」智能体的交互性能确实在逐步进化,进一步说明了所设计方法的有效。
结论
针对大模型智能体难以利用自身交互经历进化自身交互性能的问题,上海交通大学跨媒体语言智能实验室(X-LANCE)提出了 RLEM 框架,设计了「忆者」智能体。实验结果显示,通过增强以外置经验记忆,并辅以强化学习对经验记忆更新,「忆者」智能体能够充分利用自身的交互经历进化交互策略,显著提升在基准任务集上的性能。
该工作为大模型智能体进化自身性能,以及将大模型智能体与强化学习结合,提供了富有价值的方案和见解,未来或有机会在此方向上探索得更深更远。
#部署深度学习模型
搬运工又来了~~ 说说部署的事~~
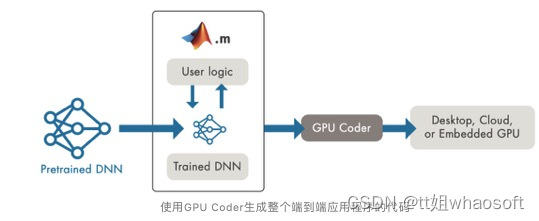
将深度学习模型部署到生产环境面临两大挑战:
我们需要支持多种不同的框架和模型,这导致开发复杂性,还存在工作流问题。数据科学家开发基于新算法和新数据的新模型,我们需要不断更新生产环境
如果我们使用英伟达GPU提供出众的推理性能。首先,GPU是强大的计算资源,每GPU运行一个模型可能效率低下。在单个GPU上运行多个模型不会自动并发运行这些模型以尽量提高GPU利用率
能从数据中学习,识别模式并在极少需要人为干预的情况下做出决策的系统令人兴奋。深度学习是一种使用神经网络的机器学习,正迅速成为解决对象分类到推荐系统等许多不同计算问题的有效工具。然而,将经过训练的神经网络部署到应用程序和服务中可能会给基础设施经理带来挑战。多个框架、未充分利用的基础设施和缺乏标准实施,这些挑战甚至可能导致AI项目失败。今天就探讨了如何应对这些挑战,并在数据中心或云端将深度学习模型部署到生产环境。
一般来说,我们应用开发人员与数据科学家和IT部门合作,将AI模型部署到生产环境。数据科学家使用特定的框架来训练面向众多使用场景的机器/深度学习模型。我们将经过训练的模型整合到为解决业务问题而开发的应用程序中。然后,IT运营团队在数据中心或云端运行和管理已部署的应用程序。
部署需求
需求一:简单的demo演示,只看看效果
caffe、tf、pytorch等框架随便选一个,切到test模式,拿python跑一跑就好,顺手写个简单的GUI展示结果;高级一点,可以用CPython包一层接口,然后用C++工程去调用
需求二:要放到服务器上去跑,不要求吞吐和时延
caffe、tf、pytorch等框架随便选一个,按照官方的部署教程,老老实实用C++部署,例如pytorch模型用工具导到libtorch下跑。这种还是没有脱离框架,有很多为训练方便保留的特性没有去除,性能并不是最优的。另外,这些框架要么CPU,要么NVIDIA GPU,对硬件平台有要求,不灵活;还有,框架是真心大,占内存(tf还占显存),占磁盘。
需求三:放到服务器上跑,要求吞吐和时延(重点是吞吐)
这种应用在互联网企业居多,一般是互联网产品的后端AI计算,例如人脸验证、语音服务、应用了深度学习的智能推荐等。由于一般是大规模部署,这时不仅仅要考虑吞吐和时延,还要考虑功耗和成本。所以除了软件外,硬件也会下功夫。
硬件上,比如使用推理专用的NVIDIA P4、寒武纪MLU100等。这些推理卡比桌面级显卡功耗低,单位能耗下计算效率更高,且硬件结构更适合高吞吐量的情况。
软件上,一般都不会直接上深度学习框架。对于NVIDIA的产品,一般都会使用TensorRT来加速。TensorRT用了CUDA、CUDNN,而且还有图优化、fp16、int8量化等。
需求四:放在NVIDIA嵌入式平台上跑,注重时延
比如PX2、TX2、Xavier等,参考上面,也就是贵一点。
需求五:放在其他嵌入式平台上跑,注重时延
硬件方面,要根据模型计算量和时延要求,结合成本和功耗要求,选合适的嵌入式平台。
比如模型计算量大的,可能就要选择带GPU的SoC,用opencl/opengl/vulkan编程;也可以试试NPU,不过现在NPU支持的算子不多,一些自定义Op多的网络可能部署不上去;
对于小模型,或者帧率要求不高的,可能用CPU就够了,不过一般需要做点优化(剪枝、量化、SIMD、汇编、Winograd等)。在手机上部署深度学习模型也可以归在此列,只不过硬件没得选,用户用什么手机你就得部署在什么手机上。
上述部署和优化的软件工作,在一些移动端开源框架都有人做掉了,一般拿来改改就可以用了,性能都不错。
需求六:上述部署方案不满足你的需求
比如开源移动端框架速度不够——自己写一套。比如像商汤、旷世、Momenta都有自己的前向传播框架,性能应该都比开源框架好。只不过自己写一套比较费时费力,且如果没有经验的话,很有可能费半天劲写不好
一些视频~
MATLAB的使用 GPU Coder 将深度学习应用部署到 NVIDIA GPU上
链接:https://ww2.mathworks.cn/videos/implement-deep-learning-applications-for-nvidia-gpus-with-gpu-coder-1512748950189.html
NVIDIA Jetson上的目标检测生成和部署CUDA代码
链接:https://ww2.mathworks.cn/videos/generate-and-deploy-cuda-code-for-object-detection-on-nvidia-jetson-1515438160012.html
部署举例
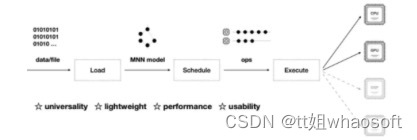
选择嵌入式部署的场景来进行分析
一般从离线训练到在线部署,我们需要依赖离线训练框架(静态图:tensorflow、caffe,动态图:pytorch、mxnet等),静态图工业部署成熟坑少,动态图灵活便捷、预研方便,各有各的好处;还需要依赖在线inference的框架(如阿里的MNN、腾讯的NCNN等等,一般不建议你自己去抠neon等simd底层的东西),能大大缩减你的部署周期,毕竟公司里面工期为王!
选定了上述工具链以后,剩下的就是我们问题所关心的如何部署,或者说的是部署流程。
一般流程分为如下几步:
- 模型设计和训练
- 针对推断框架的模型转换
- 模型部署
虽然把整个流程分成三步,但三者之间是相互联系、相互影响的。首先第一步的模型设计需要考虑推断框架中对Op的支持程度,从而相应的对网络结构进行调整,进行修改或者裁剪都是经常的事情;模型转换也需要确认推断框架是否能直接解析,或者选取的解析媒介是否支持网络结构中的所有Op,如果发现有不支持的地方,再权衡进行调整。
下面我给大家推荐几个部署案例,很多case在产品部署中都有应用, 离线训练框架主要使用tensorflow、mxnet,在线inference框架我主要使用阿里MNN。
深度学习模型部署方法
主要介绍offline的部署方法
主要分两个阶段,第一个阶段是训练并得到模型,第二个阶段则是在得到模型后,在移动端进行部署。本文主要讲解的为第二阶段。
训练模型
在第一阶段训练模型中,已经有很成熟的开源框架和算法进行实现,但是为了能部署到移动端,还需要进行压缩加速。
压缩网络
目前深度学习在各个领域轻松碾压传统算法,不过真正用到实际项目中却会有很大的问题:
- 计算量非常巨大
- 模型占用很高内存
由于移动端系统资源有限,而深度学习模型可能会高达几百M,因此很难将深度学习应用到移动端系统中去。
压缩方法
综合现有的深度模型压缩方法,它们主要分为四类:

基于参数修剪和共享的方法针对模型参数的冗余性,试图去除冗余和不重要的项。基于低秩因子分解的技术使用矩阵/张量分解来估计深度学习模型的信息参数。基于传输/紧凑卷积滤波器的方法设计了特殊的结构卷积滤波器来降低存储和计算复杂度。知识蒸馏方法通过学习一个蒸馏模型,训练一个更紧凑的神经网络来重现一个更大的网络的输出。
一般来说,参数修剪和共享,低秩分解和知识蒸馏方法可以用于全连接层和卷积层的CNN,但另一方面,使用转移/紧凑型卷积核的方法仅支持卷积层。低秩因子分解和基于转换/紧凑型卷积核的方法提供了一个端到端的流水线,可以很容易地在CPU/GPU环境中实现。相反参数修剪和共享使用不同的方法,如矢量量化,二进制编码和稀疏约束来执行任务,这导致常需要几个步骤才能达到目标。
移动端部署
目前,很多公司都推出了开源的移动端深度学习框架,基本不支持训练,只支持前向推理。这些框架都是 offline 方式,它可确保用户数据的私有性,可不再依赖于因特网连接。
Caffe2

2017年4月19日 Facebook在F8开发者大会上推出Caffe2。项目是专门为手机定制的深度框架,是在caffe2 的基础上进行迁移的,目的就是让最普遍的智能设备——手机也能广泛高效地应用深度学习算法。
开源地址: facebookarchive/caffe2
TensorFlow Lite

2017年5月17日 Goole在I/O大会推出TensorFlow Lite,是专门为移动设备而优化的 TensorFlow 版本。TensorFlow Lite 具备以下三个重要功能:
- 轻量级(Lightweight):支持机器学习模型的推理在较小二进制数下进行,能快速初始化/启动
- 跨平台(Cross-platform):可以在许多不同的平台上运行,现在支持 Android 和 iOS
- 快速(Fast):针对移动设备进行了优化,包括大大减少了模型加载时间、支持硬件加速
模块如下:
TensorFlow Model: 存储在硬盘上已经训练好的 TensorFlow 模型
TensorFlow Lite Converter: 将模型转换为 TensorFlow Lite 文件格式的程序
TensorFlow Lite Model File: 基于 FlatBuffers 的模型文件格式,针对速度和大小进行了优化。
TensorFlow Lite 目前支持很多针对移动端训练和优化好的模型。
Core ML

2017年6月6日 Apple在WWDC大会上推出Core ML。对机器学习模型的训练是一项很重的工作,Core ML 所扮演的角色更多的是将已经训练好的模型转换为 iOS 可以理解的形式,并且将新的数据“喂给”模型,获取输出。抽象问题和创建模型虽然并不难,但是对模型的改进和训练可以说是值得研究一辈子的事情,这篇文章的读者可能也不太会对此感冒。好在 Apple 提供了一系列的工具用来将各类机器学习模型转换为 Core ML 可以理解的形式。籍此,你就可以轻松地在你的 iOS app 里使用前人训练出的模型。这在以前可能会需要你自己去寻找模型,然后写一些 C++ 的代码来跨平台调用,而且难以利用 iOS 设备的 GPU 性能和 Metal (除非你自己写一些 shader 来进行矩阵运算)。Core ML 将使用模型的门槛降低了很多。
Core ML 在背后驱动了 iOS 的视觉识别的 Vision 框架和 Foundation 中的语义分析相关 API。普通开发者可以从这些高层的 API 中直接获益,比如人脸图片或者文字识别等。这部分内容在以前版本的 SDK 中也存在,不过在 iOS 11 SDK 中它们被集中到了新的框架中,并将一些更具体和底层的控制开放出来。比如你可以使用 Vision 中的高层接口,但是同时指定底层所使用的模型。这给 iOS 的计算机视觉带来了新的可能。
MACE

小米开源了深度学习框架MACE,有几个特点:异构加速、汇编级优化、支持各种框架的模型转换。
有了异构,就可以在CPU、GPU和DSP上跑不同的模型,实现真正的生产部署,比如人脸检测、人脸识别和人脸跟踪,可以同时跑在不同的硬件上。小米支持的GPU不限于高通,这点很通用,很好,比如瑞芯微的RK3299就可以同时发挥出cpu和GPU的好处来。
MACE 是专门为移动设备优化的深度学习模型预测框架,MACE 从设计之初,便针对移动设备的特点进行了专门的优化:
- 速度:对于放在移动端进行计算的模型,一般对整体的预测延迟有着非常高的要求。在框架底层,针对ARM CPU进行了NEON指令级优化,针对移动端GPU,实现了高效的OpenCL内核代码。针对高通DSP,集成了nnlib计算库进行HVX加速。同时在算法层面,采用Winograd算法对卷积进行加速。
- 功耗:移动端对功耗非常敏感,框架针对ARM处理器的big.LITTLE架构,提供了高性能,低功耗等多种组合配置。针对Adreno GPU,提供了不同的功耗性能选项,使得开发者能够对性能和功耗进行灵活的调整。
- 系统响应:对于GPU计算模式,框架底层对OpenCL内核自适应的进行分拆调度,保证GPU渲染任务能够更好的进行抢占调度,从而保证系统的流畅度。
- 初始化延迟:在实际项目中,初始化时间对用户体验至关重要,框架对此进行了针对性的优化。
- 内存占用:通过对模型的算子进行依赖分析,引入内存复用技术,大大减少了内存的占用。
- 模型保护:对于移动端模型,知识产权的保护往往非常重要,MACE支持将模型转换成C++代码,大大提高了逆向工程的难度。
此外,MACE 支持 TensorFlow 和 Caffe 模型,提供转换工具,可以将训练好的模型转换成专有的模型数据文件,同时还可以选择将模型转换成C++代码,支持生成动态库或者静态库,提高模型保密性。
目前MACE已经在小米手机上的多个应用场景得到了应用,其中包括相机的人像模式,场景识别,图像超分辨率,离线翻译(即将实现)等。
开源地址:XiaoMi/mace
MACE Model Zoo

随着MACE一起开源的还有MACE Model Zoo项目,目前包含了物体识别,场景语义分割,图像风格化等多个公开模型。
链接: XiaoMi/mace-models
FeatherCNN和NCNN
FeatherCNN 由腾讯 AI 平台部研发,基于 ARM 架构开发的高效神经网络前向计算库,核心算法已申请专利。该计算库支持 caffe 模型,具有无依赖,速度快,轻量级三大特性。该库具有以下特性:
- 无依赖:该计算库无第三方组件,静态库或者源码可轻松部署于 ARM 服务器,和嵌入式终端,安卓,苹果手机等移动智能设备。
- 速度快:该计算库是当前性能最好的开源前向计算库之一,在 64 核 ARM 众核芯片上比 Caffe 和 Caffe2 快 6 倍和 12 倍,在 iPhone7 上比 Tensorflow lite 快 2.5 倍。
- 轻量级:该计算库编译后的后端 Linux 静态库仅 115KB , 前端 Linux 静态库 575KB , 可执行文件仅 246KB 。
FeatherCNN 采用 TensorGEMM 加速的 Winograd 变种算法,以 ARM 指令集极致提升 CPU 效率,为移动端提供强大的 AI 计算能力。使用该计算库可接近甚至达到专业神经网络芯片或 GPU 的性能,并保护用户已有硬件投资。
NCNN 是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP,将 AI 带到你的指尖。ncnn 目前已在腾讯多款应用中使用,如QQ,Qzone,微信,天天P图等。
这两个框架都是腾讯公司出品,FeatherCNN来自腾讯AI平台部,NCNN来自腾讯优图。
重点是:都开源,都只支持cpu
NCNN开源早点,性能较好,用户较多。FeatherCNN开源晚,底子很好。
FeatherCNN开源地址:Tencent/FeatherCNN
NCNN开源地址:Tencent/ncnn
MDL

百度的mobile-deep-learning,MDL 框架主要包括模型转换模块(MDL Converter)、模型加载模块(Loader)、网络管理模块(Net)、矩阵运算模块(Gemmers)及供 Android 端调用的 JNI 接口层(JNI Interfaces)。其中,模型转换模块主要负责将 Caffe 模型转为 MDL 模型,同时支持将 32bit 浮点型参数量化为 8bit 参数,从而极大地压缩模型体积;模型加载模块主要完成模型的反量化及加载校验、网络注册等过程,网络管理模块主要负责网络中各层 Layer 的初始化及管理工作;MDL 提供了供 Android 端调用的 JNI 接口层,开发者可以通过调用 JNI 接口轻松完成加载及预测过程。
作为一款移动端深度学习框架,需要充分考虑到移动应用自身及运行环境的特点,在速度、体积、资源占用率等方面有严格的要求。同时,可扩展性、鲁棒性、兼容性也是需要考虑的。为了保证框架的可扩展性,MDL对 layer 层进行了抽象,方便框架使用者根据模型的需要,自定义实现特定类型的层,使用 MDL 通过添加不同类型的层实现对更多网络模型的支持,而不需要改动其他位置的代码。为了保证框架的鲁棒性,MDL 通过反射机制,将 C++ 底层异常抛到应用层,应用层通过捕获异常对异常进行相应处理,如通过日志收集异常信息、保证软件可持续优化等。目前行业内各种深度学习训练框架种类繁多,而 MDL 不支持模型训练能力,为了保证框架的兼容性,MDL提供 Caffe 模型转 MDL 的工具脚本,使用者通过一行命令就可以完成模型的转换及量化过程。
开源地址:PaddlePaddle/Paddle-Lite
SNPE
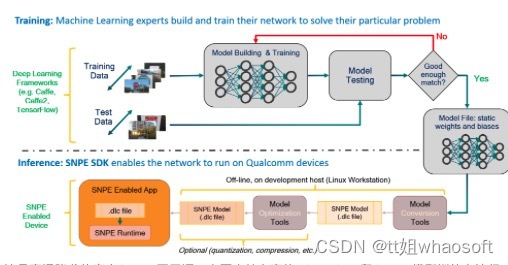
这是高通骁龙的官方SDK,不开源。主要支持自家的DSP、GPU和CPU。模型训练在流行的深度学习框架上进行(SNPE支持Caffe,Caffe2,ONNX和TensorFlow模型。)训练完成后,训练的模型将转换为可加载到SNPE运行时的DLC文件。然后,可以使用此DLC文件使用其中一个Snapdragon加速计算核心执行前向推断传递。
哈哈 是不是发现国产出了一堆呀~~ 不过还是没试过 太多了 就用了 一点点 太初学者了~~
#谷歌转向文字-视频生成
在文本转图像上卷了大半年之后,Meta、谷歌等科技巨头又将目光投向了一个新的战场:文本转视频。
上周,Meta 公布了一个能够生成高质量短视频的工具——Make-A-Video,利用这款工具生成的视频非常具有想象力。图像生成卷腻了,又来这个两大利器同时挑战分辨率和长度
当然,谷歌也不甘示弱。刚刚,该公司 CEO Sundar Pichai 亲自安利了他们在这一领域的最新成果:两款文本转视频工具——Imagen Video 与 Phenaki。前者主打视频品质,后者主要挑战视频长度,可以说各有千秋。
下面这个洗盘子的泰迪熊就是用 Imagen Video 生成的,可以看到,画面的分辨率和连贯性都有一定的保障。

下面这个片段是由 Phenaki 生成的,视频长达 2.5 分钟。可以看出,模型对于长 prompt 的解析非常出色。
发不上来...
这段视频的prompt为:「First person view of riding a motorcycle through a busy street. First person view of riding a motorcycle through a busy road in the woods. First person view of very slowly riding a motorcycle in the woods. First person view braking in a motorcycle in the woods. Running through the woods. First person view of running through the woods towards a beautiful house. First person view of running towards a large house. Running through houses between the cats. The backyard becomes empty. An elephant walks into the backyard. The backyard becomes empty. A robot walks into the backyard. A robot dances tango. First person view of running between houses with robots. First person view of running between houses; in the horizon, a lighthouse. First person view of flying on the sea over the ships. Zoom towards the ship. Zoom out quickly to show the coastal city. Zoom out quickly from the coastal city.」
Imagen Video:给出文本提示,生成高清视频
生成式建模在最近的文本到图像 AI 系统中取得了重大进展,比如 DALL-E 2、Imagen、Parti、CogView 和 Latent Diffusion。特别地,扩散模型在密度估计、文本到语音、图像到图像、文本到图像和 3D 合成等多种生成式建模任务中取得了巨大成功。
谷歌想要做的是从文本生成视频。以往的视频生成工作集中于具有自回归模型的受限数据集、具有自回归先验的潜变量模型以及近来的非自回归潜变量方法。扩散模型也已经展示出了出色的中等分辨率视频生成能力。
在此基础上,谷歌推出了 Imagen Video,它是一个基于级联视频扩散模型的文本条件视频生成系统。给出文本提示,Imagen Video 就可以通过一个由 frozen T5 文本编码器、基础视频生成模型、级联时空视频超分辨率模型组成的系统来生成高清视频。

论文地址:https://imagen.research.google/video/paper.pdf
在论文中,谷歌详细描述了如何将该系统扩展为一个高清文本转视频模型,包括某些分辨率下选择全卷积时空超分辨率模型以及选择扩散模型的 v 参数化等设计决策。谷歌还将以往基于扩散的图像生成研究成果成功迁移到了视频生成设置中。
谷歌发现,Imagen Video 能够将以往工作生成的 24fps 64 帧 128×128 视频提升至 128 帧 1280×768 高清视频。此外,Imagen Video 还具有高度的可控性和世界知识,能够生成多样化艺术风格的视频和文本动画,还具备了 3D 对象理解能力。
让我们再来欣赏一些 Imagen Video 生成的视频,比如开车的熊猫:

遨游太空的木船:

更多生成视频请参阅:https://imagen.research.google/video/
方法与实验
整体而言,谷歌的视频生成框架是七个子视频扩散模型的级联,它们相应执行文本条件视频生成、空间超分辨率和时间超分辨率。借助整个级联,Imagen Video 能够以每秒 24 帧的速度生成 128 帧 1280×768 的高清视频(约 1.26 亿像素)。
与此同时,在渐进式蒸馏的帮助下,Imagen Video 的每个子模型中仅使用八个扩散步骤就能生成高质量视频。这将视频生成时间加快了大约 18 倍。
下图 6 展示了 Imagen Video 的整个级联 pipeline,包括 1 个 frozen 文本编码器、1 个基础视频扩散模型以及 3 个空间超分辨率(SSR)和 3 个时间超分辨率(TSR)模型。这七个视频扩散模型共有 116 亿参数。
在生成过程中,SSR 模型提高了所有输入帧的空间分辨率,同时 TSR 模型通过在输入帧之间填充中间帧来提高时间分辨率。所有模型同时生成一个完整的帧块,这样 SSR 模型不会遭受明显的伪影。
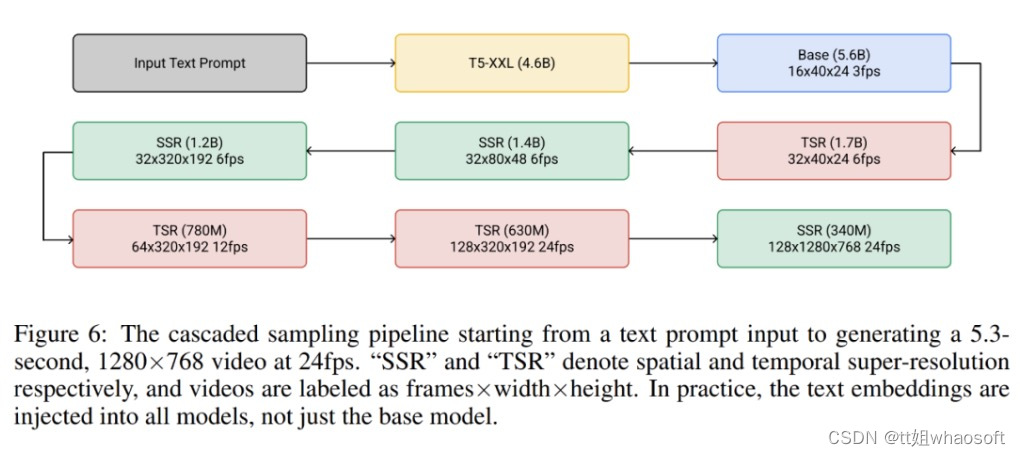
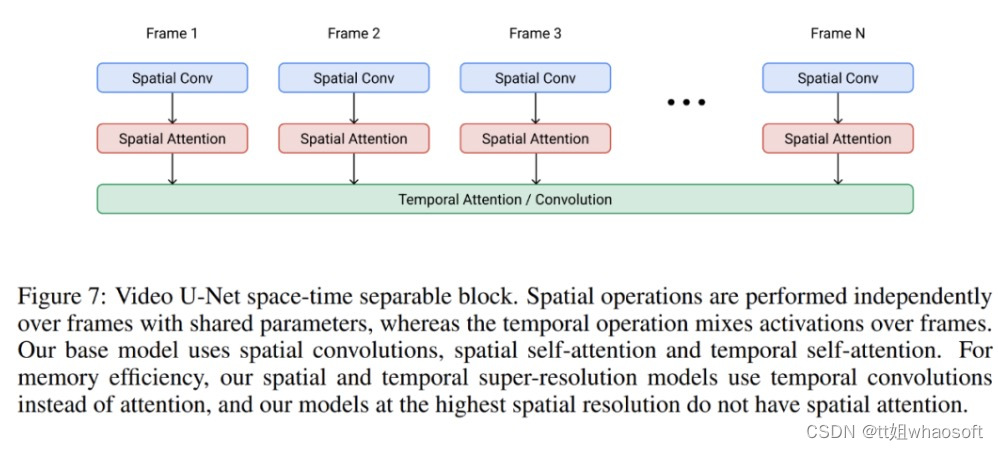
Imagen Video 构建在视频 U-Net 架构之上,具体如下图 7 所示。
在实验中,Imagen Video 在公开可用的 LAION-400M 图像文本数据集、1400 万个视频文本对和 6000 万个图像文本对上进行训练。结果正如上文所述,Imagen Video 不仅能够生成高清视频,还具备一些纯从数据中学习的非结构化生成模型所没有的独特功能。
下图 8 展示了 Imagen Video 能够生成具有从图像信息中学得的艺术风格的视频,例如梵高绘画风格或水彩画风格的视频。

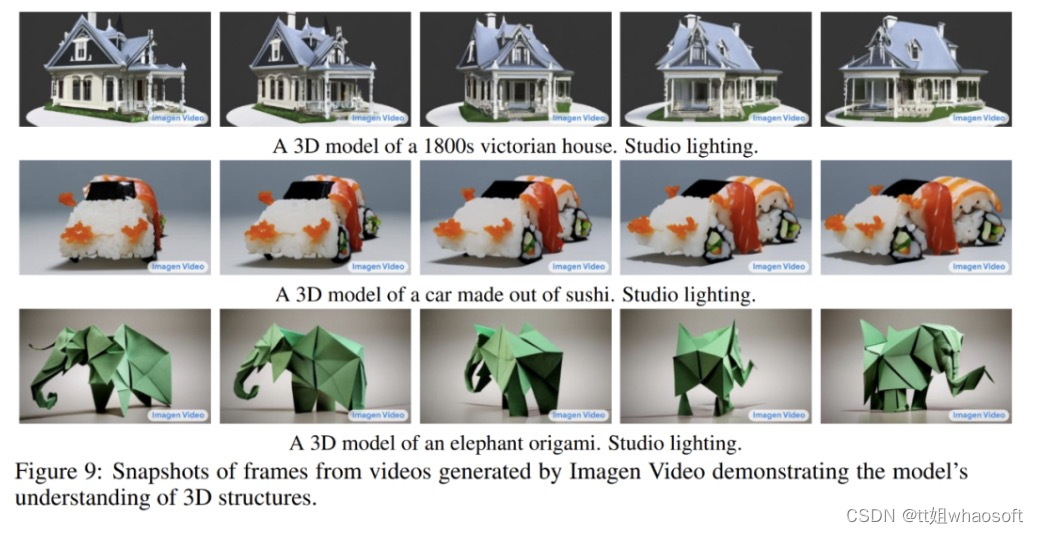
下图 9 展示了 Imagen Video 对 3D 结构的理解能力,它能够生成旋转对象的视频,同时物体的大致结构也能保留。
下图 10 展示了 Imagen Video 能够可靠地生成各种动画样式的文本,其中一些使用传统工具很难来制作。

更多实验细节请参阅原论文。
Phenaki:你讲故事我来画
我们知道,虽然从本质上讲,视频就是一系列图像,但生成一个连贯的长视频并没有那么容易,因为在这项任务中,可用的高质量数据非常少,而且任务本身的计算需求又很大。
更麻烦的是,像之前那种用于图像生成的简短文本 prompt 通常不足以提供对视频的完整描述,视频需要的是一系列 prompt 或故事。理想情况下,一个视频生成模型必须能够生成任意长度的视频,并且要能根据某个时刻 t 的 prompt 变化调节生成的视频帧。只有具备这样的能力,模型生成的作品才能称之为「视频」,而不是「移动的图像」,并开启在艺术、设计和内容创作方面的现实创意应用之路。
谷歌等机构的研究人员表示,「据我们所知,基于故事的条件视频生成之前从未被探索过,这是第一篇朝着该目标迈进的早期论文。」
- 论文链接:https://pub-bede3007802c4858abc6f742f405d4ef.r2.dev/paper.pdf
- 项目链接:https://phenaki.github.io/#interactive
由于没有基于故事的数据集可以拿来学习,研究人员没有办法简单地依靠传统深度学习方法(简单地从数据中学习)完成这些任务。因此,他们专门设计了一个模型来完成这项任务。
这个新的文本转视频模型名叫 Phenaki,它使用了「文本转视频」和「文本转图像」数据联合训练。该模型具有以下能力:
1、在开放域 prompt 的条件下生成时间上连贯的多样化视频,即使该 prompt 是一个新的概念组合(见下图 3)。生成的视频可以长达几分钟,即使该模型训练所用的视频只有 1.4 秒(8 帧 / 秒)

2、根据一个故事(即一系列 prompt)生成视频,如下图 1 和图 5 所示:


从以下动图中我们可以看到 Phenaki 生成视频的连贯性和多样性:


要实现这些功能,研究人员无法依赖现有的视频编码器,因为这些编码器要么只能解码固定大小的视频,要么独立编码帧。为了解决这个问题,他们引入了一种新的编码器 - 解码器架构——C-ViViT。
C-ViViT 可以:
- 利用视频中的时间冗余来提高每帧模型的重构质量,同时将视频 token 的数量压缩 40% 或更多;
- 在给定因果结构的情况下,允许编码和解码可变长度视频。
PHENAKI 模型架构
受之前自回归文本转图像、文本转视频研究的启发,Phenaki 的设计主要包含两大部分(见下图 2):一个将视频压缩为离散嵌入(即 token)的编码器 - 解码器模型和一个将文本嵌入转换为视频 token 的 transformer 模型。

获取视频的压缩表示是从文本生成视频的主要挑战之一。之前的工作要么使用 per-frame 图像编码器,如 VQ-GAN,要么使用固定长度视频编码器,如 V ideoVQVAE。前者允许生成任意长度的视频,但在实际使用中,视频必须要短,因为编码器不能及时压缩视频,并且 token 在连续帧中是高度冗余的。后者在 token 数量上更加高效,但它不允许生成任意长度的视频。
在 Phenaki 中,研究者的目标是生成可变长度的视频,同时尽可能压缩视频 token 的数量,这样就可以在当前的计算资源限制下使用 Transformer 模型。为此,他们引入了 C-ViViT,这是 ViViT 的一种因果变体,为视频生成进行了额外的架构更改,它可以在时间和空间维度上压缩视频,同时保持时间上的自回归。该功能允许生成任意长度的自回归视频。
为了得到文本嵌入,Phenaki 还用到了一个预训练的语言模型——T5X。