手撕Transformer之Embedding Layer
01
引言
我们在前面一系列文章中介绍了Transformer相关的理论知识,从本文开始我们开始动手实现Transformer。本文首先介绍Embedding Layer的相关知识,希望大家可以建立对其直观的理解。
闲话少说,我们直接开始吧!
02
背景介绍
嵌入层Embedding Layer的目标是使模型能够更多地了解单词、Tokens或其他输入之间的关系。如下所示:
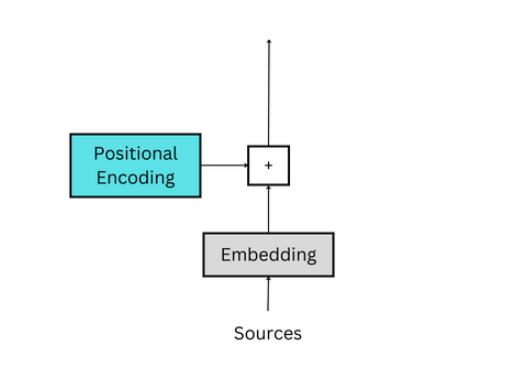
在自然语言处理中,标记Tokens可能来自于包含章节、段落或句子的数据语料库。这些数据会以各种方式被分解成更小的片段,但最常见的tokenization方法是按单词进行Token化。语料库中的所有单独单词构成了词汇表。
词汇表中的每个单词都会被分配一个整数,因为这样便于计算机处理。分配这些整数有多种方法,但最简单的方法还是按字母顺序分配。
下图展示了将大型语料库分解成各个部分并为每个部分分配整数的过程。请注意,为了简单起见,标点符号已被去掉,文本也被设置为小写。

为每个单词分配一个索引所产生的数字排列意味着一种关系。索引通常被表示成为每个词创建一个one-hot形式的编码向量。该向量的长度与词汇表的长度相同。在上述图像例子中,每个向量有 24 个元素。之所以称其为one-hot 向量,是因为只有一个元素被设置为 1;所有其他元素均被设置为 0。
当模型的词汇表只由十几个Token构成时,one-hot编码向量通常是一种方便的表示方法。然而,大型语料库可能有数十万个Token。此时,使用嵌入层Embedding Layer可以将向量映射到更小的维度,而不是使用无法表达太多含义、充满零的稀疏向量。这些嵌入向量经过训练后,可以传达更多关于每个单词及其与其他单词关系的信息。
基本上,每个单词都由一个 d_model 维向量表示,其中 d_model 可以是任何数字。它只是表示嵌入维度。如果 d_model 为 2 或 3,则可以直观地显示每个词之间的关系,但根据任务的不同,通常使用256、512 或1024 的值。
下面是一个嵌入向量可视化的例子,相似类型的书籍的嵌入向量在向量空间彼此靠近: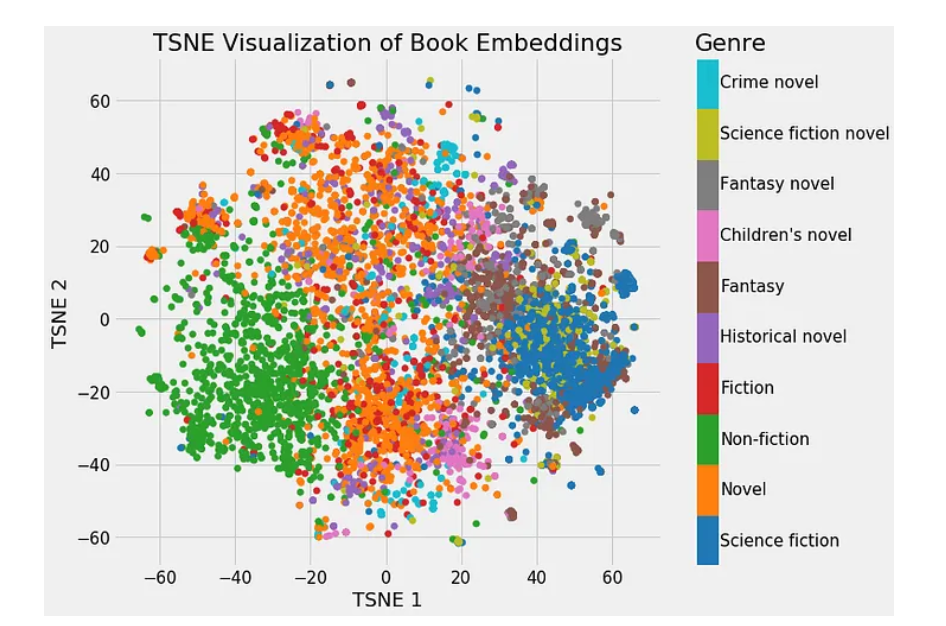
03
Embedding Vectors
嵌入矩阵的大小为 (vocab_size, d_model)。这样就可以将大小为(seq_length,vocab_size)的one-hot矩阵与之相乘,获得新的嵌入表示。序列长度用 seq_length 表示,即序列中的Token数目。请记住,输入序列将被Token化、索引化,并转换成一个one-hot编码向量矩阵。然后,这些one-hot编码向量就可以与嵌入矩阵相乘,进而获得我们输入的嵌入向量表示。
通过上述说明,我们知道嵌入向量表示的维度为:
(seq_length,vocab_size)X(vocab_size,d_model)=(seq_length,d_model)
这意味着输入句子中的每个单词,现在都是由一个d_model维向量来表示的。下面演示了上述矩阵乘法过程,输入序列的维度为(3,24),嵌入矩阵的维度为(24,3),二者相乘后,输出矩阵维度为(3,3),则表示每个单词最终由3维嵌入向量表示:

观察上述输出,我们知道当一个one-hot编码矩阵与一个嵌入矩阵相乘时,嵌入矩阵的相应位置处的向量将不做任何改变地返回。下面是one-hot编码向量与嵌入矩阵之间的矩阵乘法,输出仍然为嵌入矩阵。

这表明有一种更简便的方法可以获得这些嵌入向量的值,而无需使用矩阵乘法,因为矩阵乘法可能会耗费大量资源。为了简化上述过程,我们可以直接利用分配给每个单词的整数来直接索引固定次序下单词表的嵌入表示。这就好比从1维索引获取d_model维嵌入向量表示,这将提供更多关于输入Token的信息。
下图显示了如何在不相乘的情况下得到上图相同的结果:

04
代码实现之创建词汇表
有了上述词汇表中固定单词排序下的嵌入表示后,我们可以方便的通过索引来获取输入序列的嵌入表示,过程如下:
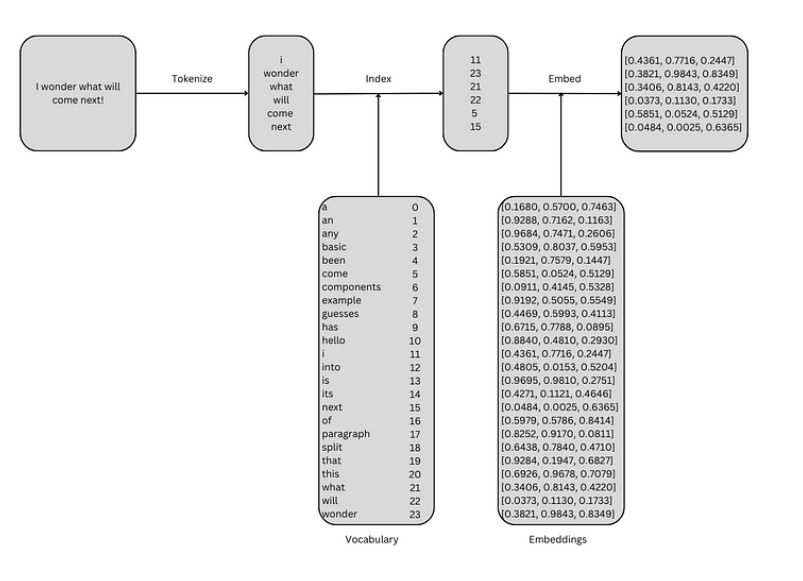
上图的简单过程可以用 Python实现。获取输入序列的嵌入表示需要一个tokenizer、一个词汇表及其索引,以及词汇表中每个单词的三维嵌入。Tokenizer将输入序列分割成单个Token,本例中的Token为小写单词。下面的简单函数会移除序列中的标点符号,将其拆分成Token,并将其转化小写。
# importing required libraries
import math
import copy
import numpy as np# torch packages
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor# visualization packages
from mpl_toolkits import mplot3d
import matplotlib.pyplot as pltexample = "Hello! This is an example of a paragraph that has been split into its basic components. I wonder what will come next! Any guesses?"def tokenize(sequence):# remove punctuationfor punc in ["!", ".", "?"]:sequence = sequence.replace(punc, "")# split the sequence on spaces and lowercase each tokenreturn [token.lower() for token in sequence.split(" ")]print(tokenize(example))
输出如下:
['hello', 'this', 'is', 'an', 'example', 'of', 'a', 'paragraph', 'that',
'has', 'been', 'split', 'into', 'its', 'basic', 'components', 'i',
'wonder', 'what', 'will', 'come', 'next', 'any', 'guesses']
创建了tokenizer后,就可以为我们的例子创建词汇表了。词汇表包含组成输入的唯一单词列表。下面是一个简单的例子"i am cool because i am short."。词汇表将是 “i,am,cool,because,short”。然后将这些单词按字母序排列:“am,because,cool,i,short”。最后,每个单词都会被赋予一个整数:“am:0,because:1,cool:2,i:3,short:4”。下面的函数实现了这一过程。
def build_vocab(data):# tokenize the data and remove duplicatesvocab = list(set(tokenize(data)))# sort the vocabularyvocab.sort()# assign an integer to each wordstoi = {word:i for i, word in enumerate(vocab)}return stoi# build the vocab
stoi = build_vocab(example)print(stoi)
得到输出结果如下:
{'a': 0,'an': 1,'any': 2,'basic': 3,'been': 4,'come': 5,'components': 6,'example': 7,'guesses': 8,'has': 9,'hello': 10,'i': 11,'into': 12,'is': 13,'its': 14,'next': 15,'of': 16,'paragraph': 17,'split': 18,'that': 19,'this': 20,'what': 21,'will': 22,'wonder': 23}
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

05
代码实现之获取嵌入向量
接着我们可以使用上述词汇表将任何Token序列转换为整数表示。
sequence = [stoi[word] for word in tokenize("I wonder what will come next!")]
print(sequence)
结果如下:
[11, 23, 21, 22, 5, 15]
下一步是创建嵌入层,它只不过是一个大小为(vocab_size,d_model)的随机值矩阵。这些值可以使用 torch.rand 生成。
# vocab size
vocab_size = len(stoi)# embedding dimensions
d_model = 3# generate the embedding layer
embeddings = torch.rand(vocab_size, d_model) # matrix of size (24, 3)
print(embeddings)
输出如下:
tensor([[0.7629, 0.1146, 0.1228],[0.3628, 0.5717, 0.0095],[0.0256, 0.1148, 0.1023],[0.4993, 0.9580, 0.1113],[0.9696, 0.7463, 0.3762],[0.5697, 0.5022, 0.9080],[0.2689, 0.6162, 0.6816],[0.3899, 0.2993, 0.4746],[0.1197, 0.1217, 0.6917],[0.8282, 0.8638, 0.4286],[0.2029, 0.4938, 0.5037],[0.7110, 0.5633, 0.6537],[0.5508, 0.4678, 0.0812],[0.6104, 0.4849, 0.2318],[0.7710, 0.8821, 0.3744],[0.6914, 0.9462, 0.6869],[0.5444, 0.0155, 0.7039],[0.9441, 0.8959, 0.8529],[0.6763, 0.5171, 0.9406],[0.1294, 0.6113, 0.5955],[0.3806, 0.7946, 0.3526],[0.2259, 0.4360, 0.6901],[0.6300, 0.2691, 0.9785],[0.2094, 0.9159, 0.7973]])
创建嵌入层后,索引序列可用于为每个标记Token选择合适的嵌入。原始序列的形状为 (6, ),值为 [11, 23, 21, 22, 5, 15],则通过索引获得的嵌入表示为:
# embed the sequence
embedded_sequence = embeddings[sequence]embedded_sequence
输出为:
tensor([[0.7110, 0.5633, 0.6537],[0.2094, 0.9159, 0.7973],[0.2259, 0.4360, 0.6901],[0.6300, 0.2691, 0.9785],[0.5697, 0.5022, 0.9080],[0.6914, 0.9462, 0.6869]])
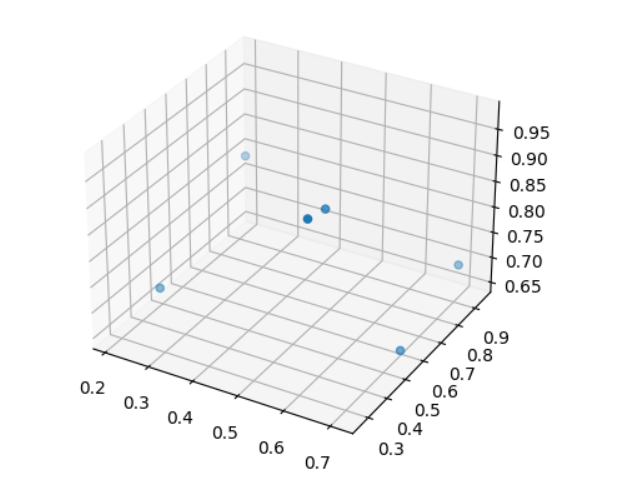
现在,六个Tokens中的每个Token都被一个3维向量取代。这表示每个Token均可以从三个维度进行映射。下图显示了未经训练的嵌入矩阵,而经过训练的嵌入矩阵则会将相似的词映射到彼此附近,就像前面提到的例子一样。
# visualize the embeddings in 3 dimensions
x, y, z = embedded_sequences[:, 0], embedded_sequences[:, 1], embedded_sequences[:, 2]
ax = plt.axes(projection='3d')
ax.scatter3D(x, y, z)
结果如下:
06
Pytorch实现
由于将使用 PyTorch 来实现Transformer,因此可以对 nn.Embedding 模块进行分析。PyTorch 将其定义为:
一个简单的查找表,用于存储固定字典和大小的嵌入。该模块通常用于存储单词嵌入,并使用索引来进行检索。该模块的输入是索引列表,输出是相应的词嵌入。
这与上一示例中使用索引而非one-hot向量时的操作完全相同。nn.Embedding 需要 vocab_size 和嵌入维度(今后将继续记为 d_model)。提醒一下,这是模型维度的简称。
下面的代码创建了一个维度为 (24, 3) 的嵌入矩阵。
# vocab size
vocab_size = len(stoi) # 24
# embedding dimensions
d_model = 3# create the embeddings
lut = nn.Embedding(vocab_size, d_model) # look-up table (lut)
# view the embeddings
print(lut.state_dict()['weight'])
输出如下:
tensor([[-0.3959, 0.8495, 1.4687],[ 0.2437, -0.3289, -0.5475],[ 0.9787, 0.7395, 2.0918],[-0.4663, 0.4056, 1.2655],[-1.0054, 1.4883, -0.1254],[-0.1028, -1.1913, 0.0523],[-0.2654, -1.0150, 0.4967],[-0.4653, -1.9941, -1.7128],[ 0.3894, -0.9368, 1.5543],[-1.1358, -0.2493, 0.6290],[-1.4935, 1.1509, -1.8723],[-0.0421, 1.2857, -0.4009],[-0.2699, -0.8918, -1.0352],[-1.3443, 0.4688, 0.1536],[ 0.3638, 0.1003, -0.2809],[ 1.4208, -0.0393, 0.7823],[-0.4473, -0.4605, 1.2681],[ 1.1315, -1.4704, 0.2809],[ 0.4270, -0.2067, -0.7951],[-1.0129, 0.0706, -0.3417],[ 1.4999, -0.2527, 0.4287],[-1.9280, -0.6485, 0.4660],[ 0.0670, -0.5822, 0.0996],[-0.7058, 0.2849, 1.1725]], grad_fn=<EmbeddingBackward0>)
如果向它传递与之前相同的索引序列 [11,23,21,22,5,15],输出将是一个维度为(6,3)矩阵,其中每个标记Token均由其三维嵌入向量表示。索引必须是张量形式,数据类型为integer或long。
indices = torch.Tensor(sequence).long()
embeddings = lut(indices)
print(embeddings)
输出如下:
tensor([[ 0.7584, 0.2332, -1.2062],[-0.2906, -1.2168, -0.2106],[ 0.1837, -0.9425, -1.9011],[-0.7708, -1.1671, 0.2051],[ 1.5548, 1.0912, 0.2006],[-0.8765, 0.8829, -1.3169]], grad_fn=<EmbeddingBackward0>)
07
Transformer中的嵌入层
在原论文中,编码器和解码器均都使用了嵌入层。nn.Embedding 模块中唯一增加的是一个标量。嵌入层的权重乘以 √(d_model)。这有助于在下一步将单词嵌入添加到位置编码中时保留基本含义。这实质上使位置编码相对变小,减少了对单词嵌入向量的影响。Stack Overflow 的这一主题对此进行了更多讨论。
网址:https://stackoverflow.com/questions/56930821/why-does-embedding-vector-multiplied-by-a-constant-in-transformer-model
为了实现这一点, 我们可以创建一个类,它将被称为Embeddings,并利用PyTorch 的 nn.Embedding 模块。该实现基于 The Annotated Transformer 的实现。
网址:https://nlp.seas.harvard.edu/annotated-transformer/#embeddings-and-softmax
代码如下:
class Embeddings(nn.Module):def __init__(self, vocab_size: int, d_model: int):"""Args:vocab_size: size of vocabularyd_model: dimension of embeddings"""# inherit from nn.Modulesuper().__init__() # embedding look-up table (lut) self.lut = nn.Embedding(vocab_size, d_model) # dimension of embeddings self.d_model = d_model def forward(self, x: Tensor):"""Args:x: input Tensor (batch_size, seq_length)Returns: embedding vector """# embeddings by constant sqrt(d_model)return self.lut(x) * math.sqrt(self.d_model)
前向过程:
上述Embeddings类的工作方式与 nn.Embedding类相同。下面的代码演示了它与前面示例中使用的单个输入序列的用法。
lut = Embeddings(vocab_size, d_model)
print(lut(indices))
输出如下:
tensor([[-1.1189, 0.7290, 1.0581],[ 1.7204, 0.2048, 0.2926],[-0.5726, -2.6856, 2.4975],[-0.7735, -0.7224, -2.9520],[ 0.2181, 1.1492, -1.2247],[ 0.1742, -0.8531, -1.7319]], grad_fn=<MulBackward0>)
07
批量推理
到目前为止,每次嵌入都只使用一个序列。然而,模型通常是用一批次序列来训练的。此时,输入基本上是一个序列列表,并将其转换为索引,然后进行嵌入。如下图所示。

我们来看个例子:
# list of sequences (3, )
sequences = ["I wonder what will come next!","This is a basic example paragraph.","Hello, what is a basic split?"]
虽然前面的例子比较简单,但它可以将其推广到成批次的序列。上图所示的例子是一个包含三个序列的批次batch;经过Tokenization后,每个序列由六个Token构成。Tokenize后的序列形状为(3,6),与(batch_size,seq_length)相关。本质上,这是由三个句子构成,每个句子由六个单词构成。
# tokenize the sequences
tokenized_sequences = [tokenize(seq) for seq in sequences]
print(tokenized_sequences)
输出如下:
[['i', 'wonder', 'what', 'will', 'come', 'next'],['this', 'is', 'a', 'basic', 'example', 'paragraph'],['hello', 'what', 'is', 'a', 'basic', 'split']]
然后,这些Tokenize序列就可以使用词汇表转换为索引表示法。
# index the sequences
indexed_sequences = [[stoi[word] for word in seq] for seq in tokenized_sequences]
print(indexed_sequences)
输出如下:
[[11, 23, 21, 22, 5, 15], [20, 13, 0, 3, 7, 17], [10, 21, 13, 0, 3, 18]]
最后,这些索引序列可以转换成张量,并传递到嵌入层,如下:
# convert the sequences to a tensor
tensor_sequences = torch.tensor(indexed_sequences).long()
print(lut(tensor_sequences))
结果如下:
tensor([[[ 0.1348, -1.3131, 2.8429],[ 0.2866, 3.3650, -2.8529],[ 0.0985, 1.6396, 0.0191],[-3.8233, -1.5447, 0.5320],[-2.2879, 1.0203, 1.5838],[ 0.4574, -0.4881, 1.2095]],[[-1.7450, 0.2474, 2.4382],[ 0.2633, 0.3366, -0.4047],[ 0.2921, -1.6113, 1.1765],[-0.0132, 0.5255, -0.7268],[-0.5208, -0.9305, -1.1688],[ 0.4233, -0.7000, 0.2346]],[[ 1.6670, -1.7899, -1.1741],[ 0.0985, 1.6396, 0.0191],[ 0.2633, 0.3366, -0.4047],[ 0.2921, -1.6113, 1.1765],[-0.0132, 0.5255, -0.7268],[-0.4935, 3.2629, -0.6152]]], grad_fn=<MulBackward0>)
输出将是一个(3,6,3)矩阵,与(batch_size、seq_length、d_model)相关。从本质上讲,每个索引Token都会被相应的三维嵌入向量取代。
在进入下一节之前,了解这些数据的形状(batch_size、seq_length、d_model)极为重要:
-
batch_size: 每次提供的序列数目有关,通常为8,16,32,64
-
seq_length: 与tokenization化后每个序列中的token数目相关
-
d_model: 与每个token嵌入向量的维度有关
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
