Oracle AI理论与实践,企业落地篇干货满满
最近也是看到了圈子里的一位DBA好友,领导安排的工作是让负责AI的落地,而且也作为他业绩考核的指标,作为1名15年的DBA老兵来说,让AI落地面临的困难重重。

AI已经逐渐侵入到实际的生活中,最近我也是参加了Oracle官方在中国区举办的首场Oracle Al专家培训,我也在这里谈谈DBA与AI之间的关系,同时分享下这次培训学习到的技能。

1.DBA与AI
了解AI+DB,学习AI+DB,成为AI+DBA,AI展现了越来越多令人惊叹的成果和应用,业界对AI的应用研究与实践探索也步入深水区,数据库作为重要的基础软件,其与AI的应用融合也进一步引起了大家的探索和想象。AI就是这样的一个未来的存在,但最终你会和他融合在一起,接受他给你带来的一切。

AI大模型在制造层面的落地并非一帆风顺。调研了解到,尤其制造类企业的数据量庞大且碎片化严重,导致数据难以被有效汇总和发挥价值,这也给传统DBA带来了严重的挑战。
2.Oracle向量化
2.1 向量检索
Oracle向量检索分为精确检索以及近似检索,使用向量检索使得能够高效地搜索与查询进行语义匹配的文本,那么这两者的区别是?
如果结果的准确性,毫无疑问,在需要遍历的向量数据集较小时,精确检索是较优的方式。
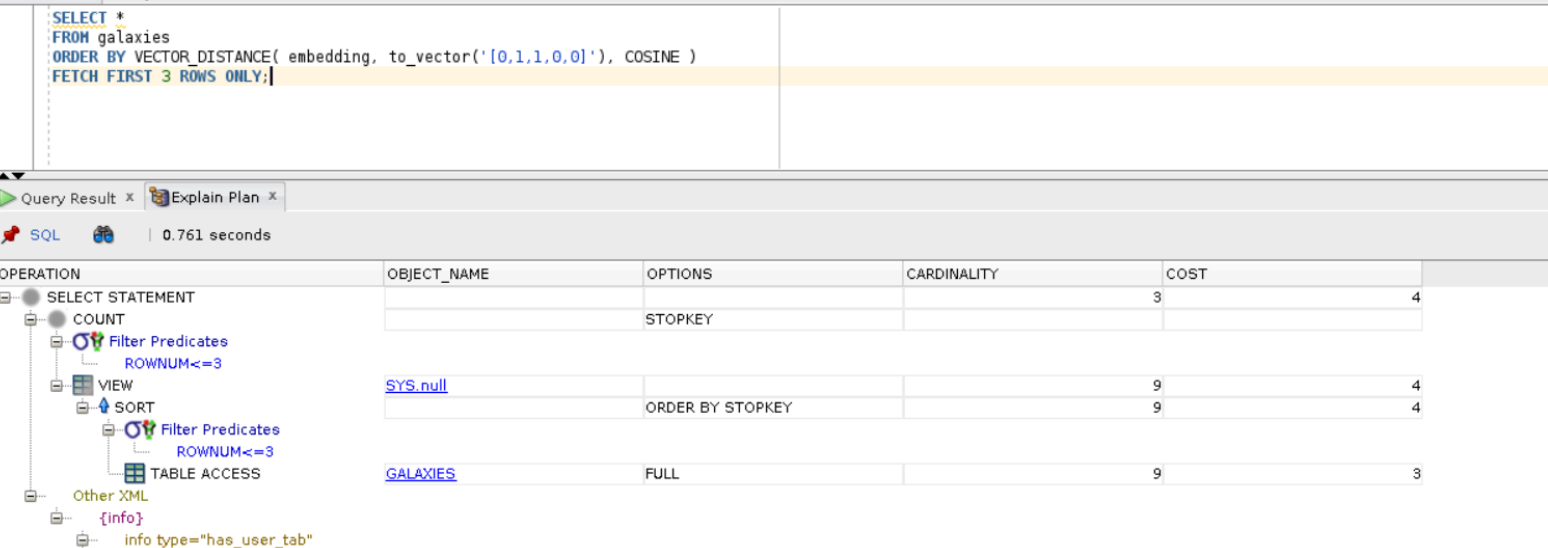
向量检索中,准确率和性能之间,往往需要寻找一个平衡。在大数据集上,为了提高性
能,利用索引进行向量近似检索是常用的方式。
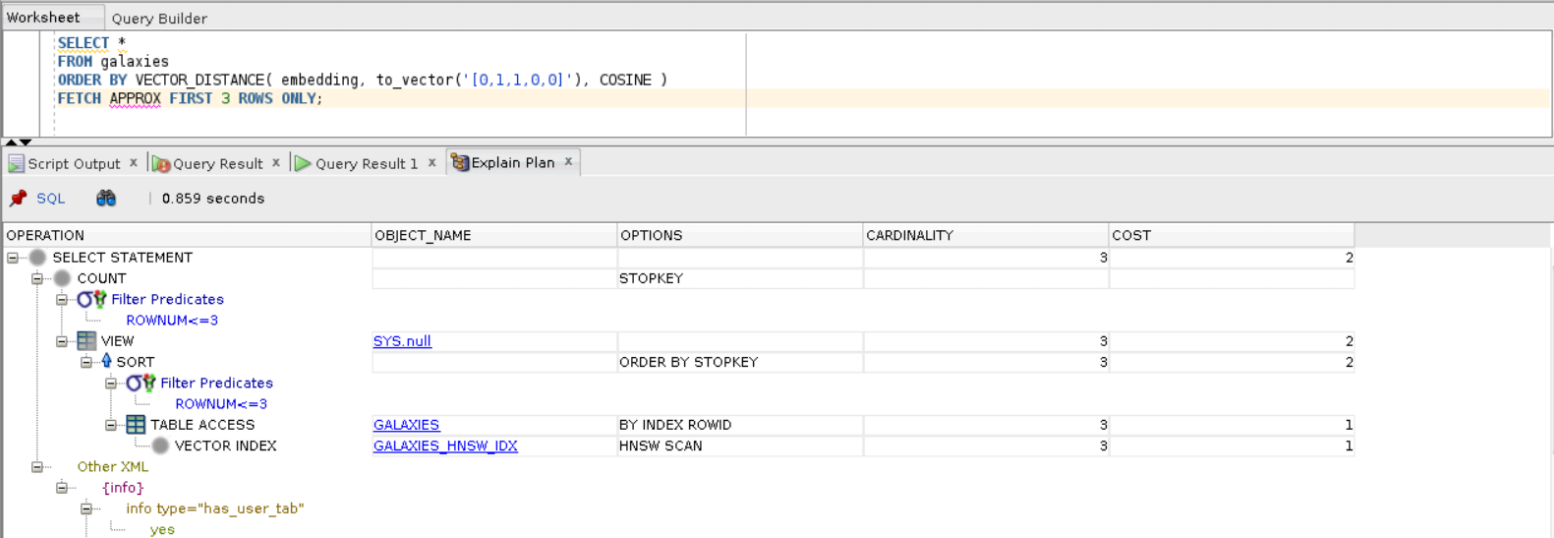
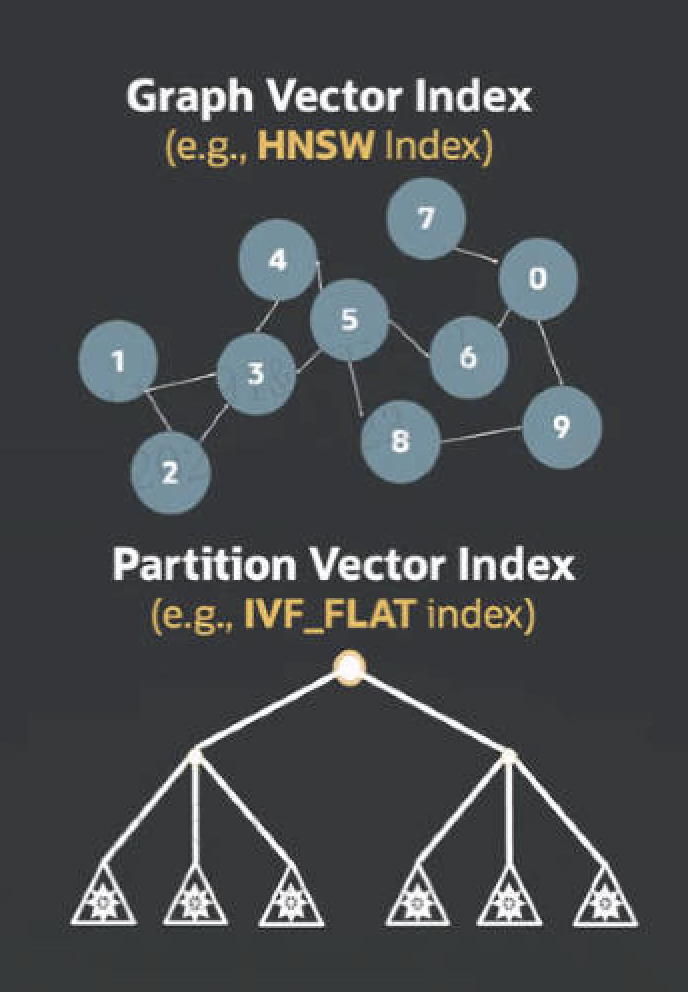
常见的向量索引有HNSW和IVF两种,具体的创建方式查阅官方文档,大家可以对比一下执行计划的不同。
2.2 向量嵌入模型
我们的向量数据是业务系统提供的,向量的维度也很小。那么,在现实环境中,向量数据是如何来的?答案是向量嵌入模型,分为库外向量化操作以及库内向量化操作。局限于数据库硬件资源现状,往往库外向量化方式使用更多。
库外向量化
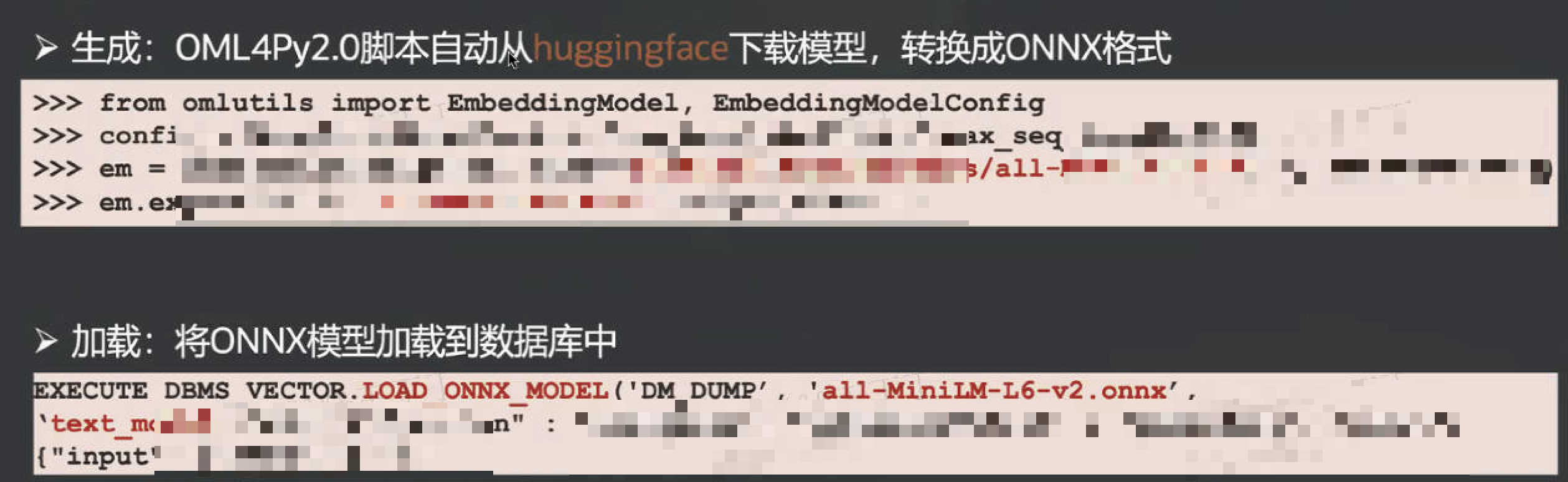
库外向量化指源数据由外部程序向量化之后,再插入或加载到数据库表中。可以使用
Python 程序将文本数据向量化之后,再调用Oracle客户包将数据插入到数据库中。
库内向量化
Oracle 数据库提供了库内向量化的特性,无需依赖外部的程序,这种方式很大程序的简化了向量数据的加载和检索,非常方便。
1.先将模型文件上传到/u01/models目录
2.创建数据库目录指向模型文件所在目录
create or replace directory MODELS_DIR as '/u01/models';
3.导入模型
BEGIN
DBMS_VECTOR.LOAD_ONNX_MODEL(
directory => 'MODELS_DIR',
file_name => 'bge-base-zh-v1.5.onnx',
model_name => 'mydoc_model'
);
END;
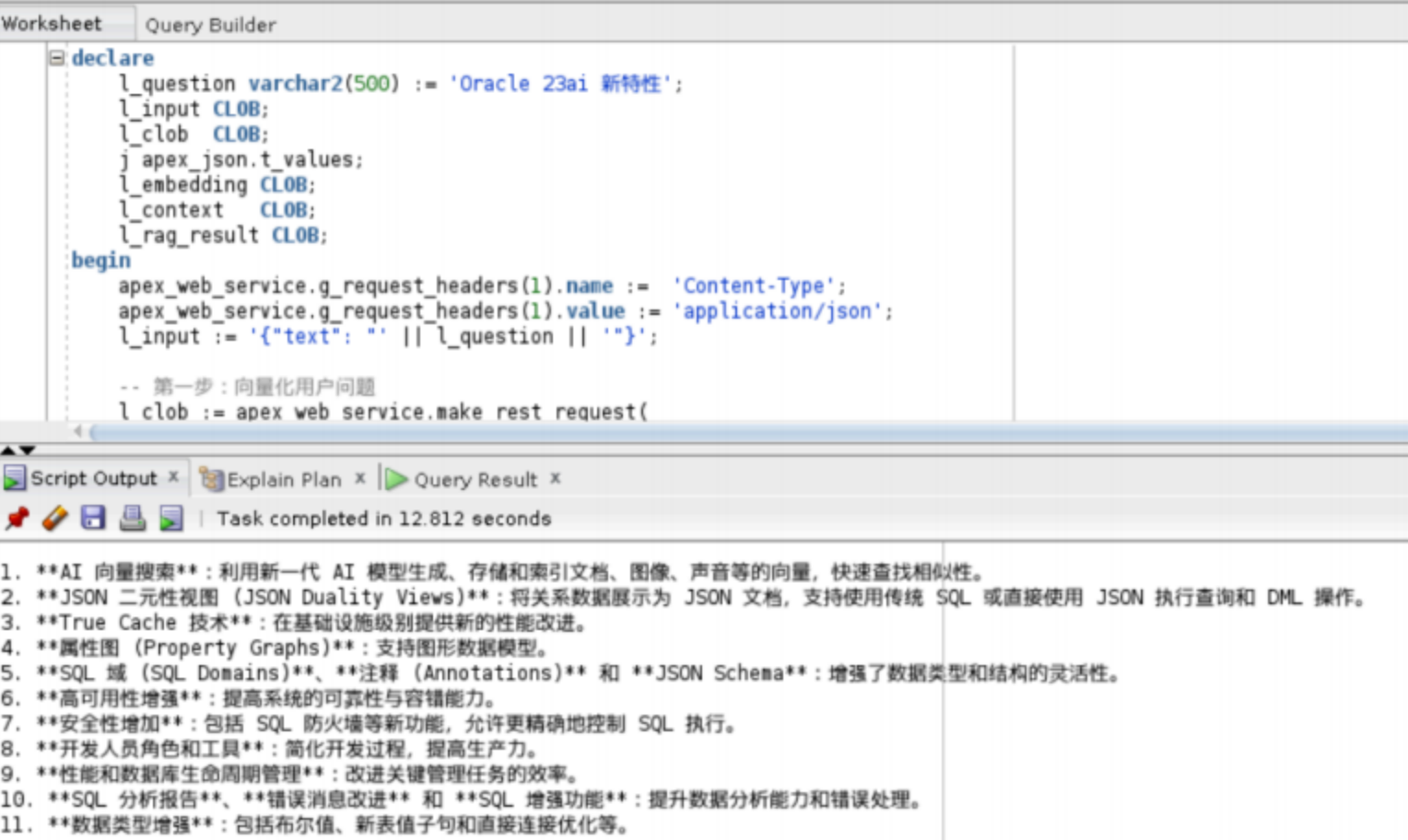
/4.相似度检索
select document,
json_value(cmetadata, '$.source') as src_file
from lab_vecstore2
where dataset_name='oracledb_docs'
order by
VECTOR_DISTANCE(embedding,
VECTOR_EMBEDDING(mydoc_model USING 'Oracle
23ai有哪些新特性?' as data), COSINE)
FETCH APPROX FIRST 3 ROWS ONLY;
3.Oracle向量与RAG应用
在RAG的解决方案中,组件要素主要包括:大语言模型(LLM)、向量嵌入模型(embedding model)、向量数据库 以及 Rerank模型。
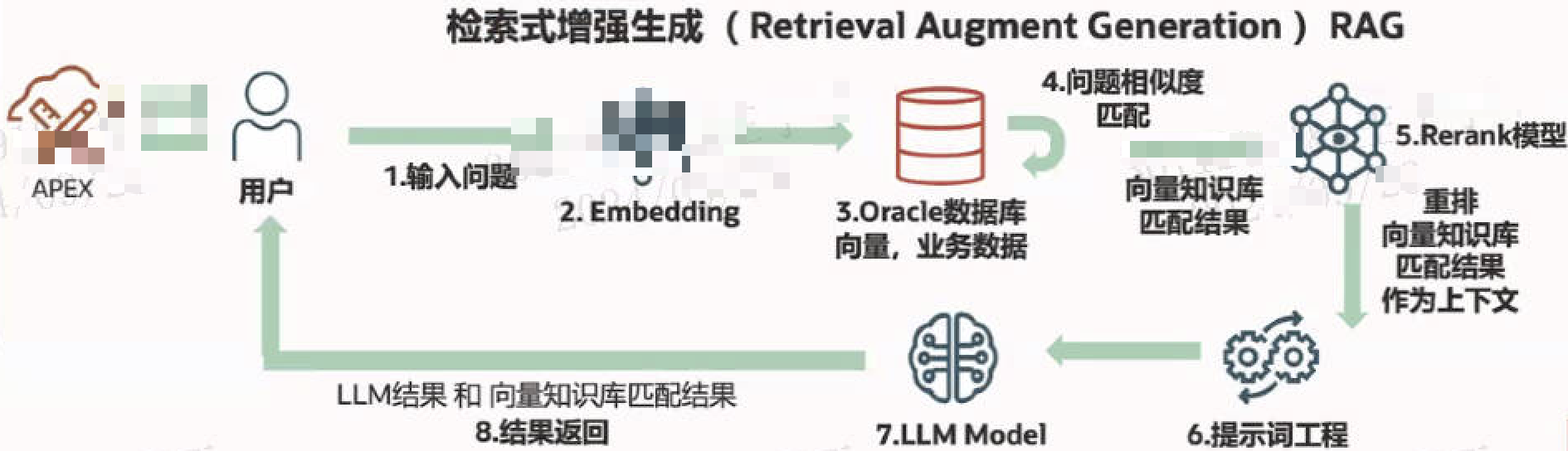
3.1 LLM对话
近年来,大语言模型 (LLM) 在语言理解和生成方面展现出了革命性的能力,但同时也面临着幻觉和内部知识过时等固有局限性。鉴于 RAG 在提供最新和有用辅助信息方面的强大能力,检索增强大语言模型应运而生,它利用外部权威知识库而不是仅仅依靠模型的内部知识来增强 LLM 的生成质量。
从下图可以看出,使用了RAG结合LLM后,输出的结果更为精准
3.2 向量化流水线
Oracle数据库提供一系列工具,让用户可以用极简单的方式将源数据向量化并加载到数据库中,在这里可以给大家分享一个文件加载检索的案例,比如
PDF文件 --> 文件文件 --> 文件分块 --> 生成向量数据
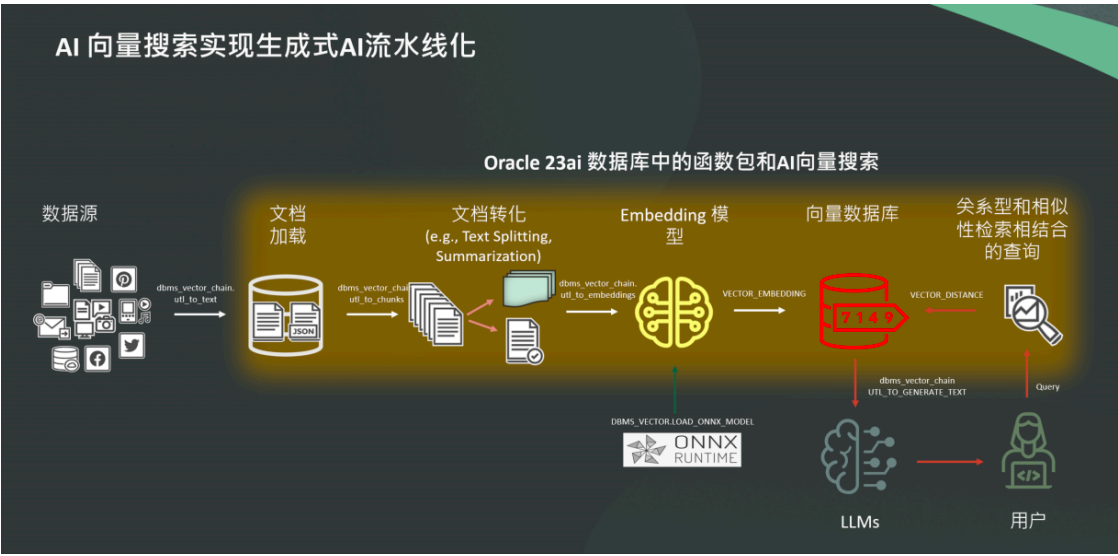
Oracle 数据库提供了一系列的工具方法,以方便向量的操作。
这些方法主要封装在 DBMS_VECTOR
DBMS_VECTOR_CHAIN 这两个包中,可以直接调用。
例如:
1.dbms_vector_chain.utl_to_text:
将文件转换为文本格式,如PDF格式转换为文本格式。
2.dbms_vector_chain.utl_to_chunks:
将文档以块的形式拆分成多个块
3.dbms_vector_chain.utl_to_embeddings:
将文档块进行向量化(批量形式)。
4.dbms_vector_chain.utl_to_generate_text:
调用大语言模型,生成RAG结果。
对于RAG应用,能否生成高质量的回答,除了大语言模型本身的能力外,还取决于高质量的输入文档和文档拆分技术或方式、构建相对合理的提示词(提示工程)、等等其它诸多方面,需要结合实际情况综合考虑。
4.总结
AI的发展趋势是我们无法左右的,AGI将会逐渐成熟,并深度影响整个世界,因此DBA要做好与AGI共存的准备,AI就是这样的一个未来的存在,但最终你会和他融合在一起,接受他给你带来的一切。