机器学习周报第五十七周 GATRes
文章目录
- week56 HA-GNN
- 摘要
- Abstract
- 一、大数据相关
- 1. 单机zookeeper
- 2. 与hbase对接的技术
- 2.1 使用hive操作hbase——直接与hbase对接(非接口技术)
- 使用 `pyhive` 操作 Hive
- 2.2 mysql操作hbase(非接口技术)
- 导出 HBase 数据到 MySQL
- 导入 MySQL 数据到 HBase
- 2.3 使用phoenix JDBC驱动
- 安装 Phoenix JDBC 驱动
- 创建 Phoenix 表映射到 HBase
- 使用 JDBC 连接到 Phoenix
- 2.4 使用 Python 操作 Phoenix
- 二、文献阅读
- 1. 题目
- 2. Abstract
- 3. 文献解读
- 3.1 Introduce
- 3.2 创新点
- 4. 网络框架
- 4.1 部分观测数据和真实模型评估
- 4.2 将水网转换为图
- 4.4 GATRes 框架
- 4.5 GATRes
- 5. 实验过程
- 6.结论
week56 HA-GNN
摘要
本周阅读了题为Graph Neural Networks for Pressure Estimation in Water Distribution Systems的论文。这项研究融合了基于物理的建模与图神经网络(GNN)这一数据驱动的技术,旨在解决压力估计的问题。该工作的两大核心贡献如下:首先,通过采用一种针对随机传感器位置的训练方法,使GNN模型在面对传感器故障或位置变动时具备更强的适应能力。其次,提出了一种贴近实际应用的评估框架,该框架不仅纳入了真实的时间序列特征,还引入了噪声模拟,以此来反映现实环境中的不确定性因素。基于此,我们开发了一个先进的模型——带有残差连接的GAT,用于进行压力估计。实验结果显示,该模型在多个水分配网络(WDN)基准测试中超越了先前的研究成果,平均绝对误差降低了大约40%。
Abstract
This week’s weekly newspaper decodes the paper entitled Graph Neural Networks for Pressure Estimation in Water Distribution Systems. This work combines physics-based modeling with graph neural networks (GNN), a data-driven approach, to tackle the pressure estimation problem. It makes two primary contributions. First, training with a strategy that uses random sensor locations makes the GNN-based estimation model robust against changes in faulty sensor positions. Second, it introduces a realistic evaluation scheme that considers true temporal patterns and injects noise to simulate the inherent uncertainties of real-world scenarios. As a result, an advanced model, GAT with residual connections, is used for pressure estimation. The model outperforms previous research on several WDN benchmarks, reducing the average absolute error by about 40%.
一、大数据相关
1. 单机zookeeper
-
下载zookeeper基于清华镜像
-
上传至虚拟机并解压
tar -zxvf zookeeper -C $路径
-
转至解压目录下
cd $路径 -
重命名
mv -i zookeeper zookeeper -
转至zk目录下
cd zookeeper -
转至配置目录下
cd conf -
复制样本配置文件
cp zoo_sample.cfg zoo.cfg,复制后的才能作为运行时调用配置文件-
注:最后为服务器列表,server后的数字需要与hosts的最后一位相同
-
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/soft/apache-zookeeper-3.9.2-bin/data dataLogDir=/usr/local/soft/apache-zookeeper-3.9.2-bin/log # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # 授权监听所有ip quorumListenOnAllIPs=true # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=node11:2888:3888 server.2=node12:2888:3888 server.3=node13:2888:3888
-
-
修改数据存储地址
dataDir=/opt/module/zookeeper/zkData,任意路径均可 -
在文件home路径下创建日志文件夹
mkdir logs -
在
/zookeeper/bin目录下执行./zkServer.sh start- 若出现授权相关问题,则分别为上述两个文件夹授权,同时为zkData下
.pid文件授权
- 若出现授权相关问题,则分别为上述两个文件夹授权,同时为zkData下
-
配置环境变量
sudo vim ~/.bashrcexport ZK_HOME=/usr/local/zookeeperexport PATH=${ZK_HOME}/bin:$PATH
-
更新配置文件
source ~/.bashrc -
最后再运行
./zkServer.sh start

2. 与hbase对接的技术
2.1 使用hive操作hbase——直接与hbase对接(非接口技术)
Hive 和 HBase 是两种不同的数据存储系统,它们各有侧重,但也可以通过一定的机制相互配合使用。Hive 主要用于批处理和数据仓库场景,而 HBase 则用于实时读写和存储大规模稀疏数据集。虽然它们各自有不同的用途,但在某些情况下,你可能需要在 Hive 和 HBase 之间进行数据交换。
Hive 与 HBase 的互操作性
- Hive on HBase
Hive 支持直接操作 HBase 表的方式,即所谓的“Hive on HBase”。这种方式下,Hive 表可以直接映射到 HBase 表,使得 Hive 能够像操作普通的 Hive 表一样操作 HBase 表。
- 创建 Hive 表映射到 HBase
要在 Hive 中创建一个映射到 HBase 表的 Hive 表,你需要使用特殊的存储处理程序(Storage Handler)以及指定 HBase 表的相关参数。
假设你有一个 HBase 表 example_table,它有一个列族 cf,你可以这样创建一个映射到这个 HBase 表的 Hive 表:
CREATE TABLE hive_hbase_table (row_key STRING,col1 STRING,col2 INT
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf:col1,cf:col2"
)
TBLPROPERTIES ("hbase.table.name" = "example_table"
);
这里的 hbase.columns.mapping 参数指定了 HBase 表中的列族和列如何映射到 Hive 表中的字段,hbase.table.name 指定了 HBase 表的名字。
使用 pyhive 操作 Hive
from pyhive import hive# 连接到 Hive
conn = hive.Connection(host='localhost', port=10000, username='your_username')# 创建游标
cursor = conn.cursor()# 执行查询
cursor.execute("""
CREATE TABLE hive_hbase_table (row_key STRING,col1 STRING,col2 INT
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf:col1,cf:col2"
)
TBLPROPERTIES ("hbase.table.name" = "example_table"
);
""")# 查询数据
cursor.execute("SELECT * FROM hive_hbase_table WHERE row_key = 'row1'")
results = cursor.fetchall()
for row in results:print(row)# 关闭连接
conn.close()
通过上述方法,你可以在 Hive 中创建映射到 HBase 表的表,并通过 Python 脚本进行操作。这种方式可以实现 HBase 和 Hive 之间的数据共享和操作。如果需要进一步的帮助或遇到具体问题,请提供详细的错误信息或日志文件。
限制和注意事项
- 性能考量:虽然 Hive on HBase 可以实现数据的互操作,但由于 Hive 是一个批处理系统,而 HBase 是一个实时存储系统,因此在执行实时查询时可能会遇到性能瓶颈。
- 数据一致性:由于 Hive 和 HBase 有不同的事务模型,直接通过 Hive 操作 HBase 表可能会影响到数据的一致性和完整性。
- 兼容性:Hive on HBase 的支持在不同的 Hive 和 HBase 版本中可能存在差异,因此需要确保你的版本兼容。
- 可以使用hive的基于sql的接口技术操作hbase
2.2 mysql操作hbase(非接口技术)
MySQL 和 HBase 是两种不同的数据库系统,它们分别针对不同的应用场景设计。MySQL 是一个关系型数据库管理系统(RDBMS),主要用于结构化数据的存储和管理;而 HBase 是一个分布式的、面向列的 NoSQL 数据库,主要用于存储大规模稀疏数据集,并提供实时读写能力。
MySQL 与 HBase 的互操作性
尽管 MySQL 和 HBase 是两个独立的系统,但在某些情况下,你可能需要在这两个系统之间进行数据交换或实现某种程度的互操作。以下是一些常见的方法和技术来实现这一点:
- 使用 ETL 工具
ETL(Extract, Transform, Load)工具可以帮助你在不同的数据存储系统之间进行数据迁移。常用的 ETL 工具包括 Apache Nifi、Apache Sqoop、Apache Beam 等。
Apache Sqoop 是一个用于在 Hadoop 和传统的关系型数据库之间传输数据的工具。你可以使用 Sqoop 将 HBase 中的数据导入到 MySQL 中,反之亦然。
导出 HBase 数据到 MySQL
sqoop export \
--connect jdbc:mysql://localhost:3306/yourdb \
--username your_username \
--password your_password \
--table your_mysql_table \
--hbase-table your_hbase_table \
--fields-terminated-by '\001' \
--columns "row_key,cf:col1,cf:col2" \
--hbase-create-table
导入 MySQL 数据到 HBase
sqoop import \
--connect jdbc:mysql://localhost:3306/yourdb \
--username your_username \
--password your_password \
--table your_mysql_table \
--hbase-table your_hbase_table \
--fields-terminated-by '\001' \
--hbase-row-key row_key \
--hbase-create-table
总结
相较于hive,mysql具有更加成熟的接口技术,但两个是独立的系统,可能需要通过导入导出间接实现两者数据的沟通
2.3 使用phoenix JDBC驱动
一些桥接技术可以让你通过 SQL 接口访问 HBase,例如 Apache Phoenix。
Apache Phoenix 是一个 SQL 的接口层,它允许你使用标准的 JDBC 接口访问 HBase。这意味着你可以使用 SQL 语句来操作 HBase 表,就像操作关系型数据库一样。
安装 Phoenix JDBC 驱动
wget http://apache.claz.org/phoenix/phoenix-5.0.0-HBase-2.0/phoenix-5.0.0-HBase-2.0-client.jar
创建 Phoenix 表映射到 HBase
CREATE TABLE phoenix_table (row_key VARCHAR PRIMARY KEY,col1 VARCHAR,col2 INTEGER
) SALT_BUCKETS = 4;
使用 JDBC 连接到 Phoenix
import java.sql.*;public class PhoenixExample {public static void main(String[] args) {try (Connection conn = DriverManager.getConnection("jdbc:phoenix:hadoop01,hadoop02,hadoop03:2181;/hbase;securityEnabled=false;ssl=false;auth=SIMPLE;principal=");Statement stmt = conn.createStatement()) {// 插入数据stmt.executeUpdate("UPSERT INTO phoenix_table (row_key, col1, col2) VALUES ('row1', 'value1', 1)");// 查询数据ResultSet rs = stmt.executeQuery("SELECT * FROM phoenix_table WHERE row_key = 'row1'");while (rs.next()) {System.out.println(rs.getString(1) + "\t" + rs.getString(2) + "\t" + rs.getInt(3));}} catch (SQLException e) {e.printStackTrace();}}
}
虽然 MySQL 和 HBase 是不同的数据库系统,但你可以通过 ETL 工具(如 Apache Sqoop)或桥接技术(如 Apache Phoenix)实现它们之间的数据交换和一定程度的互操作。Apache Phoenix 特别适合那些希望使用 SQL 语句操作 HBase 数据的用户。
如果你需要在 Python 中操作 HBase 和 MySQL,可以使用相应的 Python 库,如 happybase 和 pymysql。通过上述方法,你可以在不同数据库系统之间进行数据迁移和操作。如果需要进一步的帮助或遇到具体问题,请提供详细的错误信息或日志文件。
2.4 使用 Python 操作 Phoenix
如果你需要在 Python 中操作 Phoenix 表,可以使用 pymysql 或者 sqlalchemy 库来连接 Phoenix 并执行 SQL 语句。
import pymysql# 连接到 Phoenix
conn = pymysql.connect(host='hadoop01',port=2181,database='/hbase',user='',password='',connect_timeout=5,ssl={'enabled': False},auth_plugin='PLAIN'
)
二、文献阅读
1. 题目
标题:Graph Neural Networks for Pressure Estimation in Water Distribution Systems
作者:Huy Truong, Andrés Tello, Alexander Lazovik, and Victoria Degeler
发布:Water Resources Research
链接:doi:10.1029/2023WR036741
2. Abstract
这项工作结合了基于物理的建模和图神经网络(GNN),一种数据驱动的方法,来解决压力估计问题。工作有两个主要贡献。首先,基于随机传感器位置的训练策略使得基于GNN的估计模型对故障传感器位置变化具有鲁棒性。其次,一个现实的评估方案,考虑真实的时间模式和噪声注入,以模拟真实世界场景固有的不确定性。因此,一种新的状态-最先进的模型,GAT与残差连接,压力估计是可用的。模型在几个wdn基准上的表现超过了以前的研究,平均减少了约40%的绝对误差。
3. 文献解读
3.1 Introduce
在这项工作中,通过利用基于物理的仿真模型和基于GNN的数据驱动方法来关注压力估计。依靠利用EPANET仿真工具的数据生成方法来克服模型训练所需数据的缺乏。然而,在方法中,包括了所有在以前的工作中没有考虑到的动态参数(例如,水库总水头、储罐液位、粗糙度系数)。这有助于数据的多样性,并避免了由于模型简化误差而导致的不确定性传播(Du et al., 2018)。
GATRes能够重建Oosterbeek(荷兰的一个大尺度WDN)的结压力,平均绝对误差为1.94 m,与其他模型相比提高了8.57%。同样,模型在其他wdn基准数据集上优于以前的方法。C‐Town WDN的改进幅度最大(Ostfeld等人,2012年),绝对误差降低了52.36%,Richmond (Van Zyl, 2001年)的误差降低了5.31%,L‐Town的误差降低了40.35% (Vrachimis等人,2022年)。此外,对模型泛化的第一次尝试表明,多图预训练和微调有助于提高模型的性能。采用泛化策略后,Oosterbeek网络的绝对误差降低了约2%。
3.2 创新点
主要贡献如下
- 由于所提出的训练策略依赖于随机传感器位置,基于GNN的估计模型对意外传感器位置变化具有鲁棒性。
- 评估方案考虑了实时依赖模式,并额外注入了真实世界场景固有的不确定性。结果是一个新的基于GNN的最先进的模型,带有剩余连接的GAT (GATRes),用于wdn中的压力估计。
4. 网络框架
液压专家使用流量、需求和压力等基本测量来管理wdn。这些测量提供了WDN的全面视角,为预测、泄漏检测和操作控制等各种监督任务奠定了基础。出于这个原因,本研究的重点是解决水网络中所有节点位置的近似测量的基本挑战。在本研究中,最初假设先验知识(即历史数据)不可用,并且在典型条件下离散地记录网络状态,忽略泄漏、地震或火灾等不可预见的事件。此外,假设网络中两个邻域之间的测量状态表现出一定程度的相似性。这些假设对于采用从有效案例中训练出来的数据驱动的机器学习模型至关重要,同时避免了供水网络复杂性过高。
现实生活中的WDN由不同的组件组成,如水箱,阀门,泵,水库和数千个客户连接点,其测量状态对管理至关重要。在本研究中,缩小了范围,并倾向于将压力作为主要测量,因为与流量相比,压力易于安装,价格更实惠。然而,由于基础设施的限制和隐私问题,这些压力传感器在实践中受到限制。因此,收集到的数据,即结节点的压力状态,是稀缺的。这些状态在训练数据驱动的方法中扮演着至关重要的角色,这些方法与机器学习模型相一致,通常需要大量的数据。作为先决条件,压力状态应该是完全可观察的,以最小化整个供水网络中所有客户位置的训练模型的估计损失。这种矛盾给应用机器学习方法解决压力估计任务带来了挑战。
4.1 部分观测数据和真实模型评估
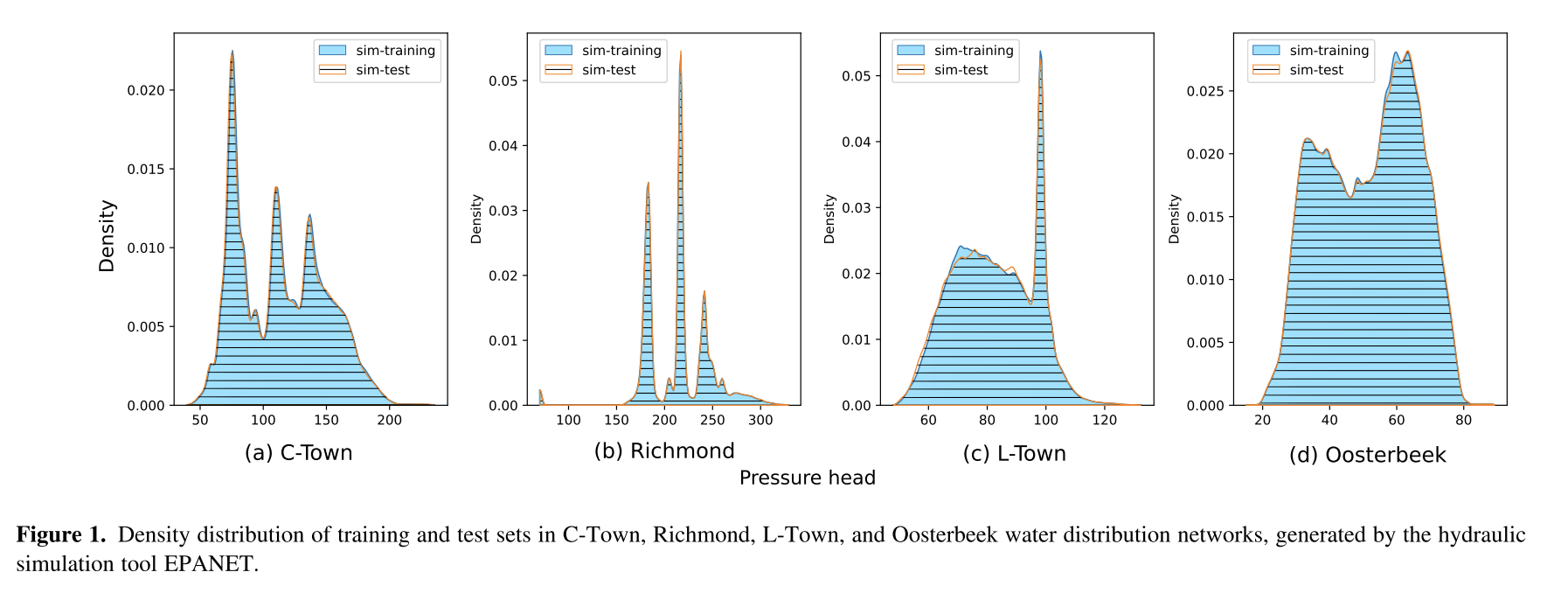
由液压仿真工具EPANET生成的来自不同wdn的训练集和测试集的压力密度分布如图1所示。在这种情况下,模拟的动态参数,例如油藏总扬程、连接处需求、泵速,在每次运行时随机调整。如前所述,只考虑正常条件下的WDN状态。因此,所有静态参数,如节点标高、管道长度、管径等都是固定的。在给定输入参数值的特定组合的情况下,每次模拟运行都会产生网络的任意状态(快照)。该算法一直运行到50000个稳定的网络状态。然后,将数据按60:20:20的比例随机划分为训练集、验证集和测试集。这些图是从训练集和测试集中随机抽取2000个快照生成的,其中每个快照代表所有连接点的压力。尽管如此,从图中可以明显看出,水力模拟生成的训练集和测试集的分布在所有示例中都是相同的。在这种情况下,评估由同一算法生成的数据上的重建模型只是评估模型重建训练过程中已经看到的信号的能力。
在工作中,提出了一个现实的测试集生成过程,它依赖于基于时间的需求模式。此外,在模拟之前注入高斯噪声以模拟现实世界场景固有的不确定性。结合基于时间的需求模式和噪声注入,可以创建真实的场景来评估模型推广到OOD数据的能力,训练集和测试集之间的密度分布存在明显差异。
4.2 将水网转换为图
在数学上,快照被表示为一个有限的、齐次的、无向的图G = (X, E, a),它有N个节点和M条边。边代表管道、阀门和泵,而节点可以是连接点、水库和储罐。节点特征存储在矩阵 X ∈ R N × d n o d e \mathbf X∈\mathbb R^{N×d_{node}} X∈RN×dnode中,其中 d n o d e d^{node} dnode为节点特征维数。在这项工作中,压力是唯一的节点特征,因为它被认为是监测WDN中最重要的稳定因素,并与先前的研究。因此,将X称为压力垫
E ∈ R M × d e d g e \mathbf E∈\mathbb R^{M×d_{edge}} E∈RM×dedge为边缘特征矩阵,其中 d e d g e d_{edge} dedge为边缘维数。根据特定的模型,如果没有使用这些边缘属性,将 h e d g e h_{edge} hedge设置为0,或者设置为2,这表示支持管道长度和直径。节点的连接用邻接矩阵 A ∈ R N × N \mathbf A∈\mathbb R^{N×N} A∈RN×N表示,其中 a i j a_{ij} aij = 1表示节点i和节点j通过链路连接, a i j a_{ij} aij = 0表示不通过链路连接。
由于部分可观测性,观测整个水网的精确压力X具有挑战性。因此,依靠基于物理的仿真模型来构建合成压力作为模型的训练样本。具体地说,仿真包括各种参数,包括静态和动态。静态参数(如节点高度和管径)保持不变,而动态参数(如连接处需求和储罐设置)则随时间而波动。然后,通过求解水力方程来估计WDN中未知节点的压力和流量。
尽管传统模拟的可用性,但它们需要手动校准过程以保持与实际物理水网的同步。鉴于这些限制,采取了另一种战略选择。特别是,仅仅利用模拟模型来生成合成样本来训练无校准模型。训练后的模型可以推断部署中任何水网的压力。
4.4 GATRes 框架
该模型有望从现有的已知信号中学习图形表示来估计未知的压力。此外,为了准确地估计距离传感器较远位置的压力,有一种方法将(推断的)测量数据从计量节点和中间节点有效地收集到距离较远的邻居是至关重要的。首先概述消息传递神经网络(MPNN) (Gilmer等人,2017),这是空间gnn的通用框架。然后,讨论图注意力网络(GAT) (veli<e:1> kovic等人,2018)作为基本组成部分之一。鉴于此,建议将GATRes作为主要模块,并设计如图3所示的整体架构。
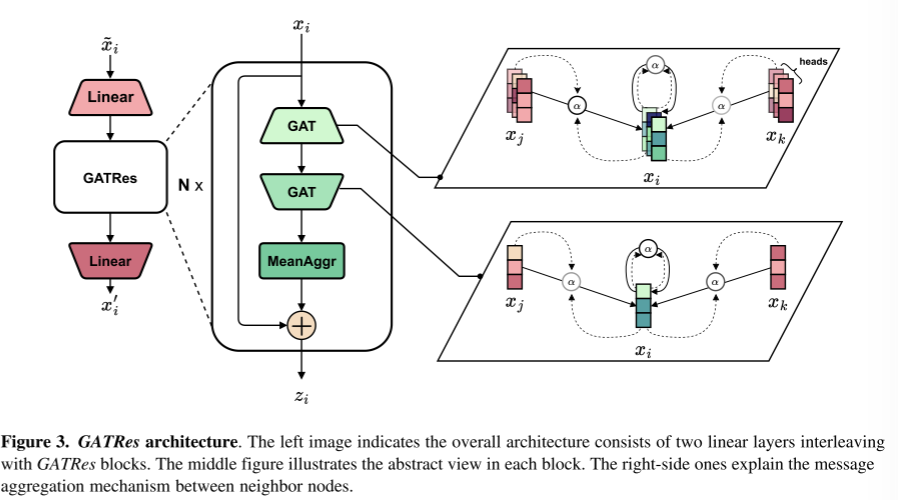
考虑到GNN是一系列堆叠的层,MPNN描述了一个特定的层,通过消息传播将先前的表示转换为连续的表示。为了简单起见,省略了层索引,并将目标节点i的表示形式表示为xi。值得注意的是,第一个表示是被称为压力值的输入特征。然后,连续层的输出表示计算如下:
z i = U P D A T E ( x i , ⊕ j ∈ N ( i ) M A S G ( x j ) ) (1) z_i=UPDATE(x_i, \oplus_{j\in \mathcal N(i)}MASG(x_j))\tag{1} zi=UPDATE(xi,⊕j∈N(i)MASG(xj))(1)
根据特定任务的目的,存在许多定义消息聚合器的方法。理想情况下,⊕被设计成以稀疏的方式从周围节点传播消息,这只对非零值有影响。因此,该方案在处理庞大的图形时可以有效地扩展,并且经济地节省了内存分配预算。(使用简单的聚合操作向邻接节点传递信息)
接下来,从目标节点i的角度来解释GAT。具体地说,GAT关注的是目标节点i和它的一个1跳邻居j之间的中间表示关系。如果一个节点与自己成对,它就形成了一个自注意关系。因此,策略性地在每个节点中建立一个虚拟的自环路链路,将自身表示与邻居的聚合表示进行权重比较。数学上,根据式1将GAT公式改写为:
z i = ∥ h H ∑ j ∈ N ( i ) ∪ { i } α i j h Θ x j = G A T ( x i ) z_i=\Vert_h^H\sum_{j\in\mathcal N(i)\cup\{i\}}\alpha^h_{ij}\Theta x_j=GAT(x_i) zi=∥hHj∈N(i)∪{i}∑αijhΘxj=GAT(xi)
其中H为注意头数, ∥ \Vert ∥为连接算子, Θ ∈ R d i n × d o u t \Theta∈\mathbb R^{d_{in}×d_{out}} Θ∈Rdin×dout为层权矩阵, d i n d_{in} din和 d o u t d_{out} dout分别为输入和输出表示维度。具体来说,选择一个求和作为UPDATE函数来聚合节点消息。对于每个节点,其MSG函数用α乘以可学习权值 Θ \Theta Θ和节点输入 x j x_j xj的线性组合来表示。其中, α \alpha α为注意系数,计算公式为:
a i j = s o f t m a x ( σ ( α T [ Θ x i ∣ ∣ Θ x j ] ) ) a_{ij}=softmax(\sigma(\alpha^T[\Theta x_i||\Theta x_j])) aij=softmax(σ(αT[Θxi∣∣Θxj]))
s o f t m a x ( x ) = e x i ∑ j ∈ N ( i ) ∪ { i } e x j softmax(x)=\frac{e^{x_i}}{\sum_{j\in\mathcal N(i)\cup \{i\}}e^{x_j}} softmax(x)=∑j∈N(i)∪{i}exjexi
4.5 GATRes
根据经验建议使用额外的GAT层来评估从前一层生成的头部视图。将这种方法命名为GATRes。数学上,定义GATRes如下:
z i = x i + 1 ∣ N ( i ) + 1 ∣ ∑ j ∈ N ( i ) ∪ { i } G A T ( G A T ( x j : α , Θ ) ; β , Ψ ) z_i=x_i+\frac 1{|\mathcal N(i)+1|}\sum_{j\in\mathcal N(i)\cup\{i\}}GAT(GAT(x_j:\alpha,\Theta);\beta,\Psi) zi=xi+∣N(i)+1∣1j∈N(i)∪{i}∑GAT(GAT(xj:α,Θ);β,Ψ)
与图3中的中间图像一样,将中间输入xi依次提供给两个GAT layer。对于目标节点i,内部 G A T : R N × d m → R N × H d o u t GAT:\mathbb R^{N\times d_m}\rightarrow \mathbb R^{N\times Hd_{out}} GAT:RN×dm→RN×Hdout设计了多个头部视图,并在其1跳邻居中对它们进行加权。换句话说,它利用来自周围节点的消息聚合,进一步丰富了多头视图的多样性。
考虑了邻域中压力值的分布,因此根据经验地对当前表示应用均值聚合器。之后,使用中间输入xi的非参数残差连接,允许深度扩展并减少过拟合问题(。
如图3所示,整个结构是由许多GATRes块组成的堆栈。由于每个块考虑1跳邻居,堆叠多个块允许消息传播到图中的远邻居。在消息传播层之前,采用共享权重线性变换将被屏蔽的输入节点特征投影到高维空间。将第一个线性层称为steaming layer,这在计算机视觉任务中是众所周知的。在消息传播后,最后的线性层充当解码器,将高维表示投影回原始维度(即dnode = 1)。端到端模型随后将输出一个即时快照,其中任何节点的所有压力值都被恢复。
5. 实验过程
数据集:
本研究的主要用例是使用荷兰Oosterbeek地区的私有大型WDN进行的。该网络包括5,855个结点和6,188个管道。图5a显示了Oosterbeek WDN随机快照的拓扑结构和节点压力。
还使用了四个公开可用的wdn基准,即Anytown (Walski等人,1987年)、C‐Town (Ostfeld等人,2012年)、L‐Town (Vrachimis等人,2022年)和Richmond (Van Zyl, 2001年),为评估和再现工作提供了基线。最后,在与模型泛化相关的实验中,使用了两个额外的公共数据集Ky13 (Hernadez等人,2016)和一个名为“Large”的匿名WDN (Sitzenfrei等人,2023)。本研究中使用的wdn在大小和结构上各不相同,从小型和中型到大型网络(如“large”和Oosterbeek),如图5所示。表2显示了每种网络的主要特征。
数据描述:
对于节点分类任务,使用了几个开放的网络数据集,包括引文网络数据集(Cora[45]、CiteSeer[32]和PubMed[46])和合著者网络数据集(CS和Physics[47])。在引文网络数据集中,每个节点代表一篇论文,每个边代表一个引文关系。每篇论文都有一个称为节点标签的标签和一个称为节点特征的词袋表示。在合著者网络数据集中,节点代表作者,如果他们合著了一篇论文,则边缘将它们连接起来。每个节点的特征是每个作者论文的索引项,标签是作者工作的区域。
基线:
一般来说,两个目标决定了基线的选择。第3节提到了第一个目标:在节点级回归问题上尝试流行的GNN架构。其目的是在对来自未知“自然”分布的数据点进行测试时实现可接受的误差。第二个目标是探索现有框架,从综合数据查询和模型训练到评估阶段。目标是为与wdn相关的压力估计任务或问题建立一个可靠的基准框架。换句话说,在测试中表现更好的模型应该在实际应用中更有用。
为此,将GATRes架构与流行的gnn进行了比较,包括GCNii和GAT。除此之外,GraphConWat (GCW)和mGCN也是使用稀疏信息的GNN解决压力估计的主要方法,在比较中也被考虑在内。表3总结了模型设置。
带超参数的GATRes‐small是优化过程后的最优版本。为了研究模型大小的影响,还引入了在参数数量方面接近mGCN的GATRes - large尺度。
评估标准:
用于评估回归模型性能的最常用评估指标是RMSE(Root Mean Square Error)、MAE和平均绝对百分比误差(MAPE)。应该使用相对和绝对误差度量来评估模型。因此,模型使用MAE和MAPE进行评估。此外,纳入了Nash和Sutcliffe效率系数(NSE),该系数被广泛用于评估水文模型的性能。最后,使用了一个精度度量,定义为正预测与预测值总数的比率。正预测是那些至多偏离某个阈值的预测。
实验结果:
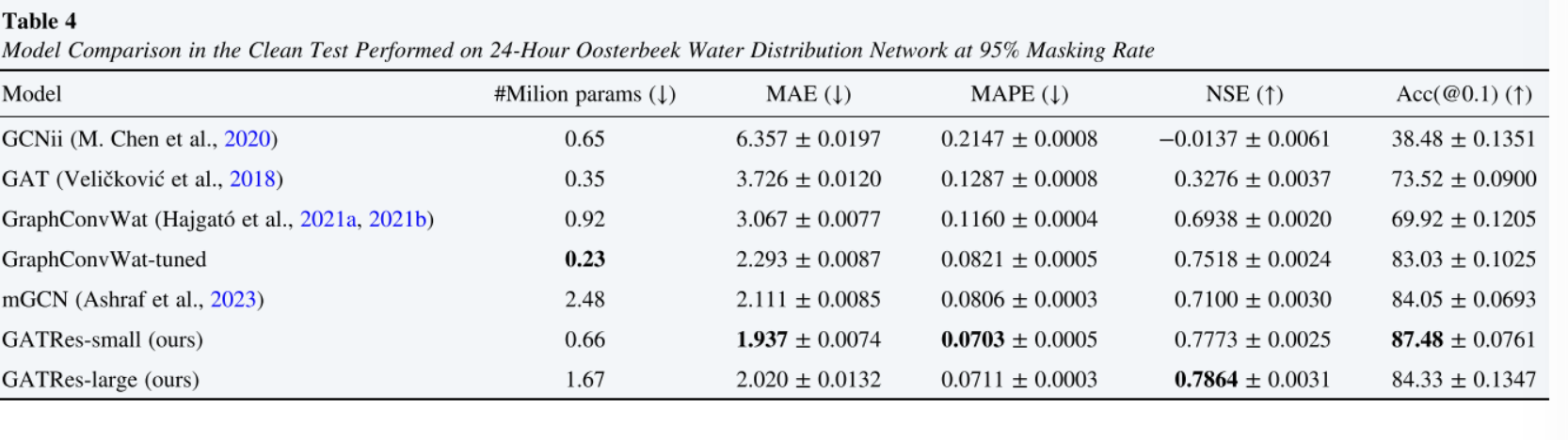
为了评估,在24小时的Oosterbeek上测试了基线模型,重复了100次。结果的均值和标准差见表4。除非另有说明,否则在实验中默认为干净测试。表5给出了噪声测试的结果。
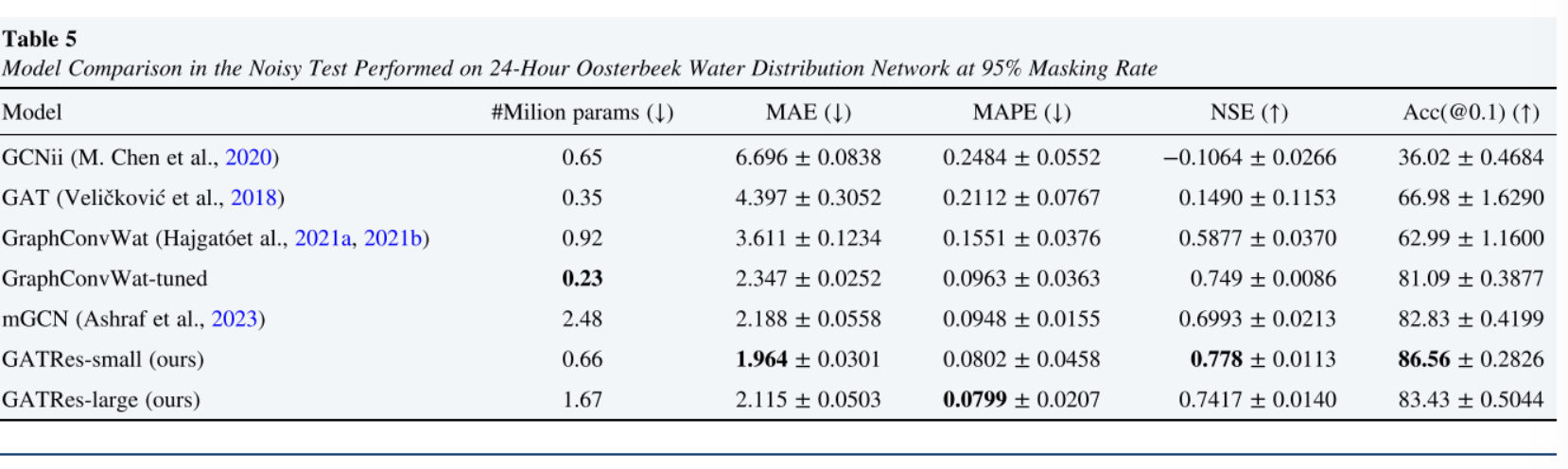
6.结论
在这项工作中,提出了一种基于物理和数据驱动的混合方法来解决wdn中的状态估计问题。利用数学模拟工具和gnn来重建网络中95%的连接处的缺失压力,而在训练期间只看到了5%的连接。还在更极端的传感器稀疏情况下测试了方法,达到99%的掩蔽率。工作成果是wdn压力估计的新技术,主要有两个贡献。首先,基于随机传感器位置的训练策略使基于GNN的估计模型对意外传感器位置变化具有鲁棒性。其次,一个现实的评估方案,考虑真实的时间模式和噪声注入,以模拟真实世界场景固有的不确定性。
The data set generation tool and GATRes model are publicly available on https://github.com/DiTEC‐project/gnn‐pressure‐estimation (Truong et al., 2023).