股价预测,非线性注意力更佳?
作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:
本文探讨了在 transformer 模型中使用非线性注意力来预测股票价格的概念。我们讨论了黎曼空间和希尔伯特空间等非线性空间的数学基础,解释了为什么非线性建模可能是有利的,并提供了在代码中实现这种方法的分步指南。
近年来,Transformer 的使用彻底改变了自然语言处理,并越来越多地改变了其他各种领域,例如时间序列分析和股票价格预测。传统的 transformer 架构依赖于线性点积注意力机制,该机制适用于许多任务。但是,这种线性方法可能无法捕获某些数据集(例如股票价格)中关系的全部复杂性,其中非线性依赖关系和复杂模式更为普遍。
一、了解非线性空间:黎曼空间和希尔伯特空间
为了理解为什么非线性注意力机制可能有用,我们需要深入研究几何和泛函分析的一些基本概念。让我们从机器学习中常用的欧几里得空间与黎曼空间和希尔伯特空间等更复杂的空间之间的区别开始。
1. 欧几里得空间
欧几里得空间是我们在初等几何学中学习的熟悉的平面空间。此空间中的距离使用欧几里得距离公式进行测量,点积用于测量向量之间的相似性。在传统的 transformer 中,注意力机制在这个欧几里得空间中运行。
2. 黎曼空间
黎曼空间是允许曲率的欧几里得空间的泛化。在黎曼空间中,测量距离和角度的度量可能因点而异,从而允许空间以复杂的方式弯曲。这种曲率使我们能够对更复杂的关系和依赖关系进行建模,而这些关系和依赖关系在平坦的线性空间中无法充分捕获。
3. 希尔伯特空间
希尔伯特空间是欧几里得空间的无限维泛化,配备了一个完整的内积。它是泛函分析和量子力学中的一个基本概念,为理解具有潜在无限维度的空间提供了一个框架。当我们使用核方法(如 Gaussian 或 Radial Basis Function 内核)时,我们会将数据从有限维欧几里得空间隐式映射到无限维希尔伯特空间。
二、为什么非线性注意力可能是一个好主意
股票价格预测本质上是非线性的。价格受多种因素影响,包括经济指标、新闻事件、投资者情绪和市场微观结构。这些关系通常是复杂的、非线性的和高维的。通过使用非线性注意力机制,我们可以将输入数据映射到更高维的空间,在那里这些复杂的关系可能会变得更加线性且更容易建模。
从本质上讲,使用非线性注意力有助于:
- 捕获数据中复杂的非线性依赖关系。
- 提供更丰富的数据点之间关系表示形式,从而有可能提高预测性能。
- 利用内核函数提供的到更高维度的隐式映射,使我们能够发现线性方法可能遗漏的模式。
三、具有非线性注意力的 Transformer
为了实现具有非线性注意力的 transformer 模型,我们引入了一种基于内核的自定义注意力机制。传统的 transformer 使用点积注意力,这是 inputs 的线性函数。我们的非线性注意力机制使用核函数(例如 Gaussian 或 Radial Basis Function 内核)来计算注意力分数。
非线性注意力机制:
1. 内核注意力层
KernelAttention 类使用查询 (Q) 和键 (K) 矩阵之间的欧几里得距离计算成对距离矩阵。然后使用高斯核转换此距离,该核将数据映射到更高维的空间。结果是反映数据中非线性关系的注意力权重矩阵。
2. 线性注意力层
为了进行比较,我们还使用 PyTorch 的内置 MultiheadAttention 类实现了标准的线性注意力机制。该层对 inputs 执行传统的点积关注。
3. Transformer Decoder 模型
transformer 解码器模型被设计为接受线性和非线性注意力机制,允许我们直接比较它们的有效性。输入序列首先通过线性层将其转换为所需的维数,然后是选定的注意力机制,最后是另一个线性层来输出预测。
四、代码解释
代码实现包括数据加载、预处理、模型定义、训练和评估。以下是关键组件:
1. 数据准备:我们使用 yfinance 库下载 Reliance Industries 的历史股票数据。使用 MinMaxScaler 对数据进行预处理和规范化。
2. 序列创建:使用滑动窗口方法创建输入序列和相应的标签以进行训练。
3. 模型架构:TransformerDecoder 类定义了线性和非线性注意力机制的选项。KernelAttention 类使用 Gaussian 内核实现非线性注意力。
4. 训练和评估:实现了一个 train_model 函数来训练和评估线性和非线性注意力模型。该函数计算训练集和测试集的损失、平均绝对误差 (MAE) 和平均绝对百分比误差 (MAPE)。
5. 可视化:matplotlib 用于绘制损失曲线并比较两个模型的实际价格与预测价格。
五、结果
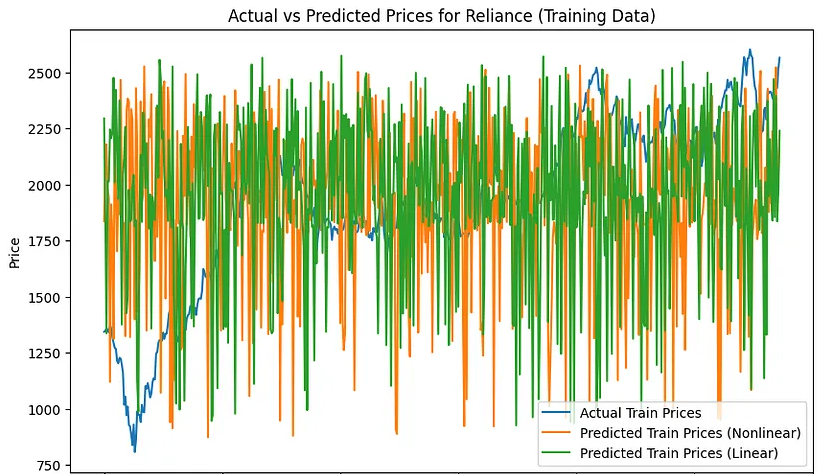
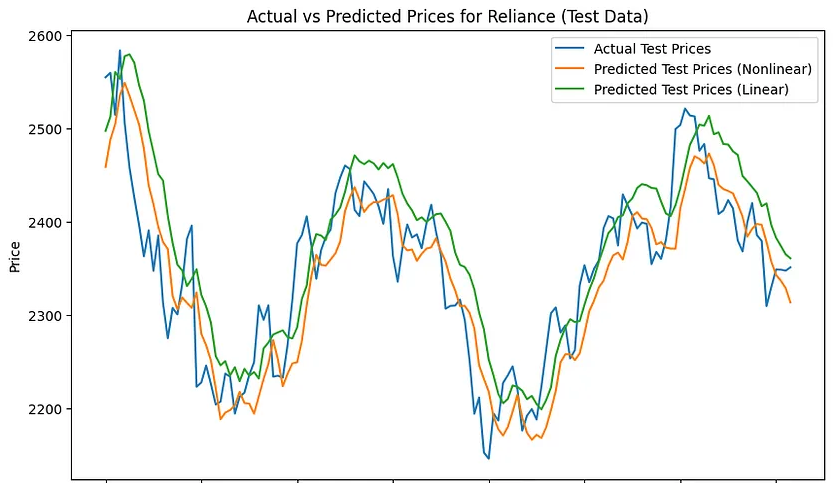
非线性注意力:训练集MAE:397.4294,训练集 MAPE:23.40% 非线性注意力:测试集 MAE:39.6702,测试集 MAPE:1.69%
线性注意力:训练集 MAE:397.2669,训练集 MAPE:23.18% 线性注意力:测试集 MAE:48.4979,测试集 MAPE:2.07%
在训练集中
在测试集上
六、结论
通过实现具有非线性注意力的 transformer,与线性注意力机制相比,我们有可能在股票价格数据中捕获更复杂的模式。我们的实验结果提供了两种方法之间的比较,展示了非线性注意力如何在损失、MAE 和 MAPE 方面提供更好的性能。
这种方法展示了从黎曼几何和泛函分析到金融时间序列预测的概念的实际应用。通过利用非线性注意力机制,我们为金融以外的各个领域的复杂关系建模开辟了新的可能性。此处介绍的代码和方法可作为进一步探索和实验的起点。研究人员和从业者可以基于此框架开发更复杂的模型、合并其他功能或将类似技术应用于其他时间序列预测任务。随着我们不断突破机器学习和人工智能的界限,将高级数学概念与实际实现相结合对于开发更强大、更准确的预测模型至关重要。