代码随想录算法训练营第51天 | 岛屿数量、岛屿的最大面积
目录
岛屿数量
题目描述
输入描述
输出描述
输入示例
输出示例
提示信息
1. 深搜解法
2. 广搜解法
岛屿的最大面积
题目描述
输入描述
输出描述
输入示例
输出示例
提示信息
1. 深搜解法
2. 广搜解法
岛屿数量
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1
输出示例
3
提示信息
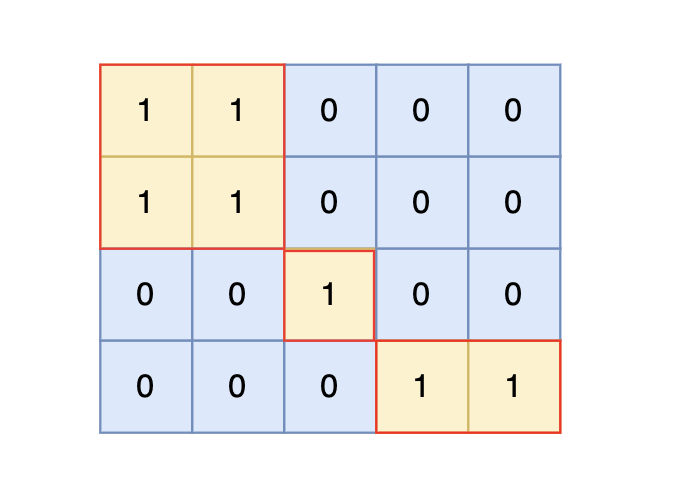
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
1 <= N, M <= 50
如果使用深搜或者广搜,其实还是比较基础的。下面介绍这两种方法。
1. 深搜解法
这里的深搜没有单独写终止条件,因为在循环里面用if判断过了,不满足情况是不会进入递归的,所以保证了其能够终止。
#include<iostream>
#include<vector>
using namespace std;int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void dfs(vector<vector<int>>& graph, vector<vector<bool>>& visited, int x, int y){for(int i = 0; i < 4; i ++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= graph.size() || nexty < 0 || nexty >= graph[0].size()) continue;if(!visited[nextx][nexty] && graph[nextx][nexty] == 1){//没有遍历过且地图上是陆地visited[nextx][nexty] = true;dfs(graph, visited, nextx, nexty);}}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> graph(n, vector<int>(m, 0));vector<vector<bool>> visited(n, vector<bool>(m, false));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){cin >> graph[i][j];}}int count = 0;for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){if(!visited[i][j] && graph[i][j] == 1){visited[i][j] = true;count ++;dfs(graph, visited, i, j);}}}cout << count << endl;
}当然也可以单独写终止条件,如下图所示。
#include<iostream>
#include<vector>
using namespace std;int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void dfs(vector<vector<int>>& graph, vector<vector<bool>>& visited, int x, int y){if(visited[x][y] || graph[x][y] == 0) return;//加上了终止条件visited[x][y] = 1;for(int i = 0; i < 4; i ++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= graph.size() || nexty < 0 || nexty >= graph[0].size()) continue;dfs(graph, visited, nextx, nexty);}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> graph(n, vector<int>(m, 0));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){cin >> graph[i][j];}}int count = 0;vector<vector<bool>> visited(n, vector<bool>(m, false));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){if(!visited[i][j] && graph[i][j] == 1){count ++;dfs(graph, visited, i, j);}}}cout << count << endl;return 0;
}2. 广搜解法
使用广度搜索需要注意标记的时候是在加入队列的时候就要标记,而不是在从队列里面取出来过后才标记,否则会出错。
#include<iostream>
#include<vector>
#include<queue>
using namespace std;int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void bfs(vector<vector<int>>& graph, vector<vector<bool>>& visited, int x, int y){queue<int> que;que.push(x);que.push(y);visited[x][y] = 1;while(!que.empty()){int x = que.front(); que.pop();int y = que.front(); que.pop();for(int i = 0 ;i < 4; i ++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= graph.size() || nexty < 0 || nexty >= graph[0].size()) continue;if(!visited[nextx][nexty] && graph[nextx][nexty] == 1){visited[nextx][nexty] = 1;que.push(nextx);que.push(nexty);//注意这里是在放入队列里面的时候就开始标记已经访问过了,而不是从队列里面取出来的时候才标记}}}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> graph(n, vector<int>(m, 0));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){cin >> graph[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));int count = 0;for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){if(!visited[i][j] && graph[i][j] == 1){count ++;bfs(graph, visited, i, j);}}}cout << count << endl;
}岛屿的最大面积
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,计算岛屿的最大面积。岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。后续 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的最大面积。如果不存在岛屿,则输出 0。
输入示例
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1
输出示例
4
提示信息
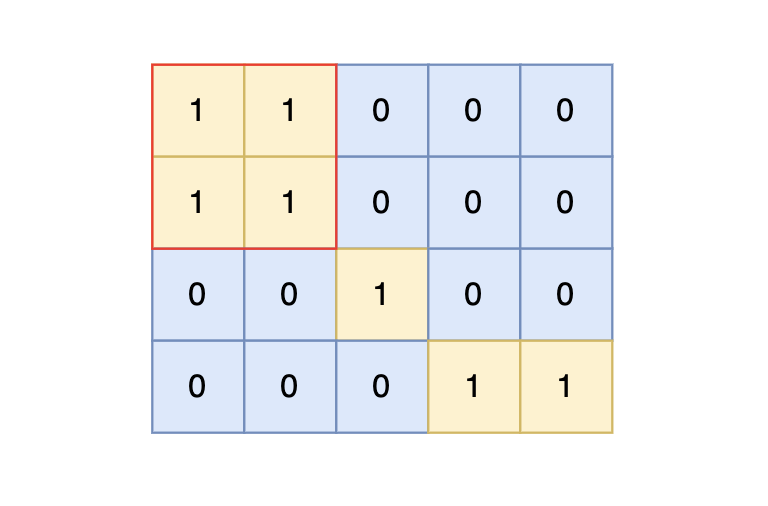
样例输入中,岛屿的最大面积为 4。
数据范围:
1 <= M, N <= 50。
思路:如果上面的题没问题,那这道题其实就非常容易了。
1. 深搜解法
这里是没有单独写终止条件的深搜。这里注意count需要在到达每一块新岛屿的时候从0开始计数。
#include<iostream>
#include<vector>
#include<queue>
using namespace std;int count = 0;
int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void dfs(vector<vector<int>>& graph, vector<vector<bool>>& visited, int x, int y){for(int i = 0; i < 4; i ++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= graph.size() || nexty < 0 || nexty >= graph[0].size()) continue;if(!visited[nextx][nexty] && graph[nextx][nexty] == 1){visited[nextx][nexty] = 1;count ++;dfs(graph, visited, nextx, nexty);}}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> graph(n, vector<int>(m, 0));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){cin >> graph[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));int result = 0;for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){if(!visited[i][j] && graph[i][j] == 1){count = 0;//这里需要注意计算每一个岛时都需要置count为0visited[i][j] = 1;count ++;dfs(graph, visited, i, j);result = max(result, count);}}}cout << result << endl;
}下面是单独写终止条件的深搜。
#include<iostream>
#include<vector>
#include<queue>
using namespace std;int count = 0;
int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void dfs(vector<vector<int>>& graph, vector<vector<bool>>& visited, int x, int y){if(visited[x][y] || graph[x][y] == 0) return;visited[x][y] = 1;count ++;for(int i = 0; i < 4; i ++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= graph.size() || nexty < 0 || nexty >= graph[0].size()) continue;dfs(graph, visited, nextx, nexty);}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> graph(n, vector<int>(m, 0));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){cin >> graph[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));int result = 0;for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){if(!visited[i][j] && graph[i][j] == 1){count = 0;//这里需要注意计算每一个岛时都需要置count为0dfs(graph, visited, i, j);result = max(result, count);}}}cout << result << endl;
}2. 广搜解法
下面是广搜的方法。
#include<iostream>
#include<vector>
#include<queue>
using namespace std;int count = 0;
int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void bfs(vector<vector<int>>& graph, vector<vector<bool>>& visited, int x, int y){queue<int> que;que.push(x);que.push(y);count ++;visited[x][y] = 1;while(!que.empty()){int curx = que.front(); que.pop();int cury = que.front(); que.pop();for(int i = 0 ;i < 4; i ++){int nextx = curx + dir[i][0];int nexty = cury + dir[i][1];if(nextx < 0 || nextx >= graph.size() || nexty < 0 || nexty >= graph[0].size()) continue;if(!visited[nextx][nexty] && graph[nextx][nexty] == 1){visited[nextx][nexty] = 1;que.push(nextx);que.push(nexty);//注意这里是在放入队列里面的时候就开始标记已经访问过了,而不是从队列里面取出来的时候才标记count ++;}}}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> graph(n, vector<int>(m, 0));for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){cin >> graph[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));int result = 0;for(int i = 0; i < n; i ++){for(int j = 0; j < m; j ++){if(!visited[i][j] && graph[i][j] == 1){count = 0;bfs(graph, visited, i, j);result = max(result, count);}}}cout << result << endl;
}感谢你的阅读,希望我的文章能够给你帮助,如果有帮助,麻烦点赞加收藏,或者点点关注,非常感谢。
如果有什么问题欢迎评论区讨论!