文本情感识别分析系统Python+SVM分类算法+机器学习人工智能+计算机毕业设计
一、介绍
使用Python作为开发语言,基于文本数据集(一个积极的xls文本格式和一个消极的xls文本格式文件),使用Word2vec对文本进行处理。通过支持向量机SVM算法训练情绪分类模型。实现对文本消极情感和文本积极情感的识别。并基于Django框架开发网页平台实现对用户的可视化操作和数据存储。
本项目通过开发一个基于Python语言的文本情感分析系统,能够自动识别文本中的情感倾向,并区分积极情感和消极情感。文本情感分析是自然语言处理中的一个重要应用领域,广泛应用于舆情监控、用户反馈分析和市场调研等场景。随着互联网的普及,海量的用户生成内容使得自动化的情感分析工具变得愈发重要和紧迫。
本项目的核心技术基于Word2Vec词向量模型对文本进行特征提取。Word2Vec通过将词汇映射到向量空间中,使得语义相似的词在空间中更加接近,从而更好地捕捉文本中的情感信息。文本特征提取完成后,我们使用支持向量机(SVM)算法对提取的特征进行训练,并构建了情感分类模型。SVM作为一种经典的监督学习算法,具备良好的分类性能,尤其在处理高维数据时表现优异。
为了便于用户操作和管理,本项目还基于Django框架开发了一个可视化的网页平台。该平台不仅能够提供用户友好的界面,使用户能够方便地上传文本并查看情感分析结果,还具备数据存储和管理功能,支持对分析结果的历史记录进行保存和检索。通过这一平台,用户可以直观地了解文本情感分析的过程和结果,提升了用户体验与系统的实用性。
二、效果图片展示
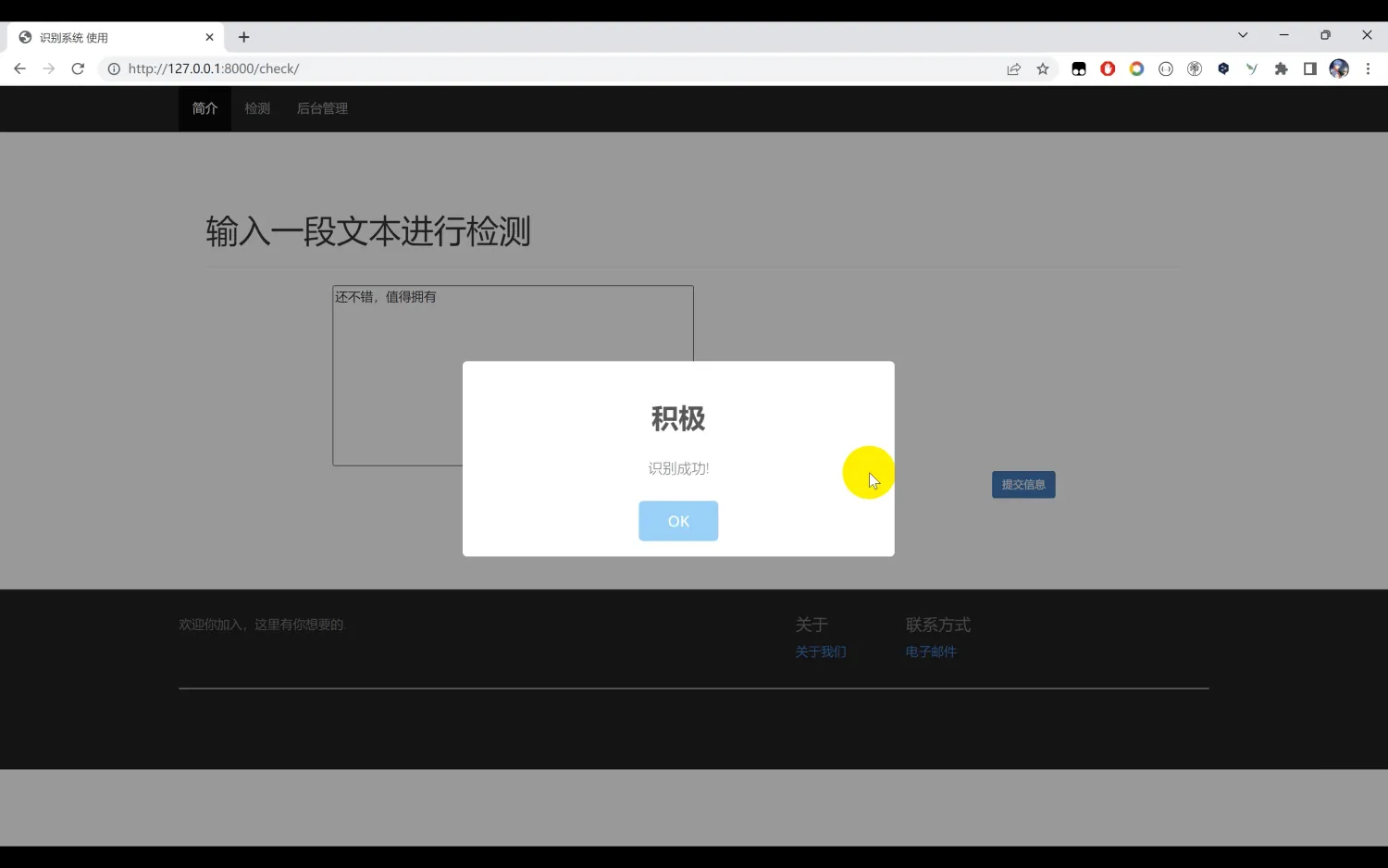

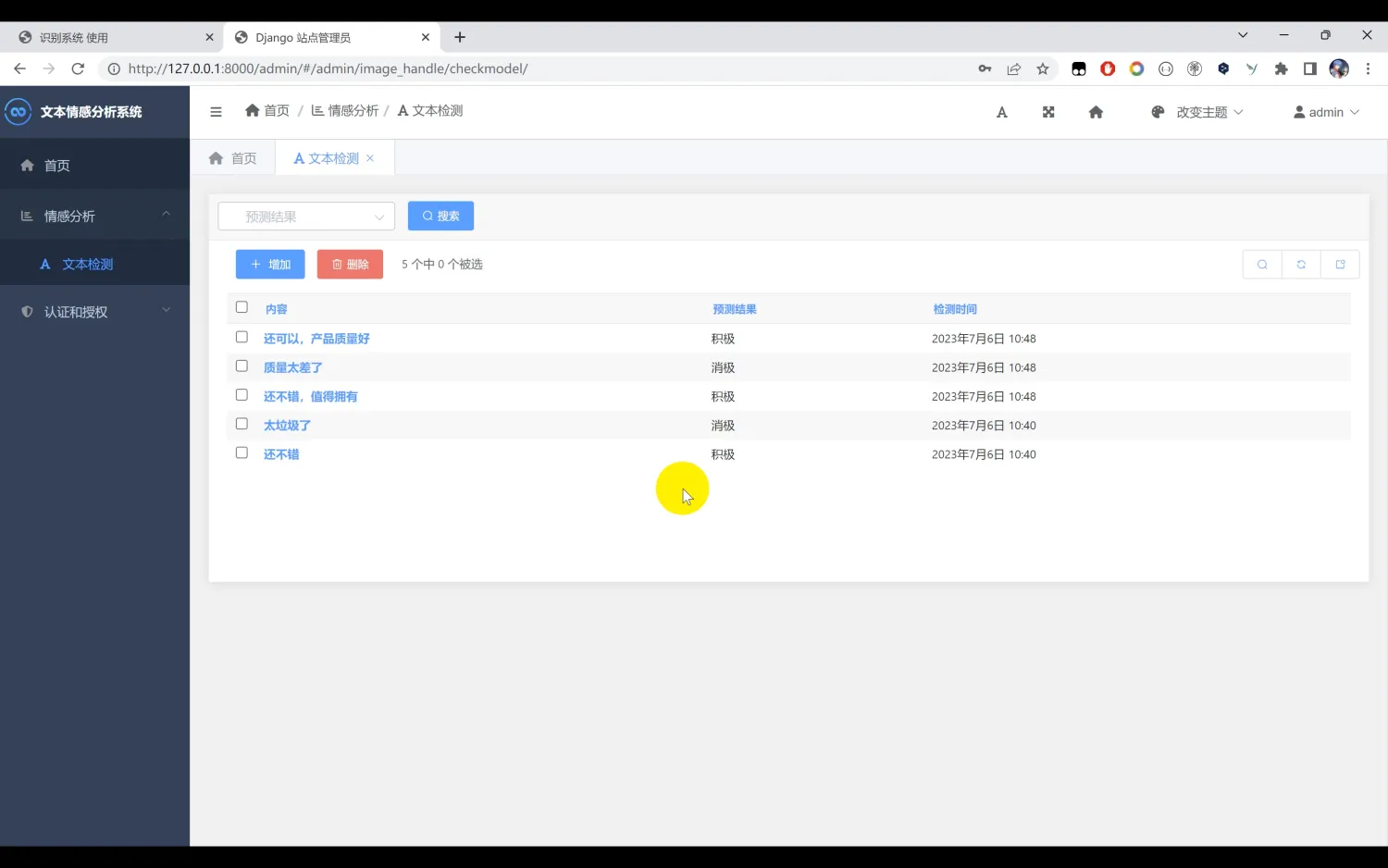
三、演示视频 and 完整代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/yn2icplnbkwafd10
四、SVM算法介绍
支持向量机(Support Vector Machine, SVM)是一种用于分类和回归分析的监督学习算法,广泛应用于文本分类、图像识别等领域。其基本思想是通过在特征空间中寻找一个最佳的超平面,将不同类别的数据进行划分。SVM尤其擅长处理高维数据,并在小样本、非线性问题中表现出色。
SVM 的核心是最大化分类间隔(Margin),即找到使得两类数据点之间距离最大的决策边界。通过这种方式,SVM 能有效地提高模型的泛化能力,减少过拟合的风险。对于线性不可分的数据,SVM 通过引入核函数(Kernel)将数据映射到更高维的空间,使其在新空间中线性可分。常用的核函数包括线性核、径向基核(RBF)和多项式核等。
在情感分析任务中,SVM可以通过处理文本的高维特征向量来实现分类。借助于Word2Vec等特征提取方法,SVM能利用文本的语义信息,将文本映射到向量空间后进行情感分类。其优异的分类性能和对高维数据的处理能力使得SVM在文本情感分类领域得到了广泛应用。
以下是一个使用支持向量机(SVM)进行文本情感分类的简单示例代码,假设我们已经对文本数据进行了特征提取(例如通过Word2Vec或TF-IDF),并将数据转化为数值特征矩阵进行训练和测试:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score# 假设我们有一个文本数据集和对应的标签(积极/消极)
data = pd.read_csv('text_sentiment_data.csv') # 数据集,包含两列:'text' 和 'label'# 使用TF-IDF对文本进行特征提取
vectorizer = TfidfVectorizer(max_features=5000) # 选择5000个最重要的特征
X = vectorizer.fit_transform(data['text']) # 将文本转化为特征矩阵
y = data['label'] # 标签(积极或消极)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化SVM分类器
svm_model = SVC(kernel='linear') # 使用线性核# 训练模型
svm_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = svm_model.predict(X_test)# 输出分类结果
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:")
print(classification_report(y_test, y_pred))
代码说明:
- 数据加载:假设我们有一个包含文本和情感标签的数据集。
- 特征提取:使用
TfidfVectorizer对文本进行特征提取,将文本转化为数值特征矩阵。也可以使用其他方法如Word2Vec。 - 模型训练:使用
SVC来构建支持向量机模型,并选择线性核函数。 - 预测与评估:在测试集上进行预测,并输出模型的准确率和分类报告。
这是一个简化的示例,在实际应用中可以根据需求调整特征提取方式和模型参数。