音视频开发之旅(94)-多模态之Blip-2
目录
1. 背景和问题
2. BLIP-2模型结构
3.Q-Former
4. 实验效果
5. 资料
一、背景与问题
前面我们在学习clip时,知道它是通过大量的图像-文本对进行预训练,做到对不同图像zero-shot,但还是从给定的图-文对中进行相似度计算来选择,如果用于训练的图-文对没有相关的内容,得到相似度最高的文本描述也可能和图片不相符。是否可以兼顾理解任务的高效性以及生成任务的灵活性,输出更符合图像的文本描述呐?
我们可能会想到把 预训练的图像编码器(VIT)是否可以和具有涌现能力的大语言模型(eg:llama、gpt)相结合进行训练或者微调,直接提升多模态在视觉知识推理、视觉问答以及图像到文本的生成上的能力。但这种端到端重新预训练的模式需要大量的数据以及负责的模型结构,训练成本高;如果基于LLM进行finetune微调,直接将单模态的模型加入到多模态的联合训练 可能会出现灾难性遗忘的问题。
另外用于训练多模态的图像-文本对,大多数都是从网上获取,这些数据往往存在一定噪声,图文不一致的情况,是否可以过滤掉噪声数据,从而提升模型准确性呐?
blip和blip2系列从这些问题出发解决,创新性的提出并实现
1、Captioner和Filter 文本生成器和文本过滤器,减少图像-文本对噪声,提升数据的质量
2、将单模态的预训练模型参数进行冻结,训练轻量化的Q-former将图像和文本进行对齐,降低多模态的训练成本
二、模型结构
本论文作者提出了一种通用且高效的Vision-Language Pre-training(VPL) 方法:基于现成的预训练好的视觉和语言模型,并对它们进行冻结,设计一个中间转换对齐器,对不同图像和文本进行对齐,降低计算量且避免灾难性遗忘。这里的关键是如何对不同模态进行对齐,由于大语言模型 LLM 在训练的时候并没有见过图像,简单的冻结参数无法达到预期的效果,作者提出了 Querying Transformer(Q-Former),并且使用 two-stage pre-training 的方式来训练 Q-Former
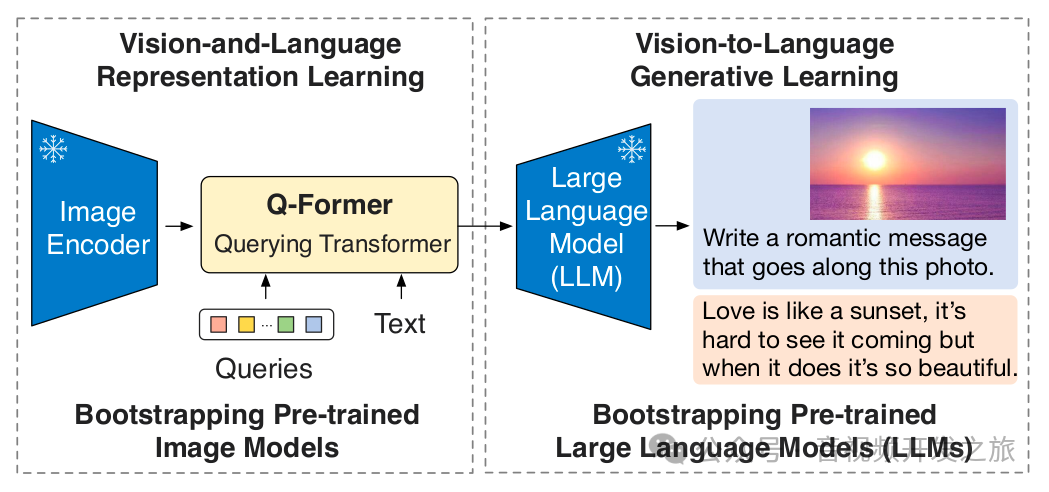
如上图所示,blip2的预训练包含两个阶段
-
视觉-语言表征学习(Vision-and-Language Representaion Learning),使Q-Former学习 与文本相关的视觉表征
-
视觉到文本的生成学习(Vision-to-Language Generative Learning),使Q-Former输出的视觉表征能够被LLM理解
三、 Q-Former
3.1 阶段 1: Representation Learning(表征学习)
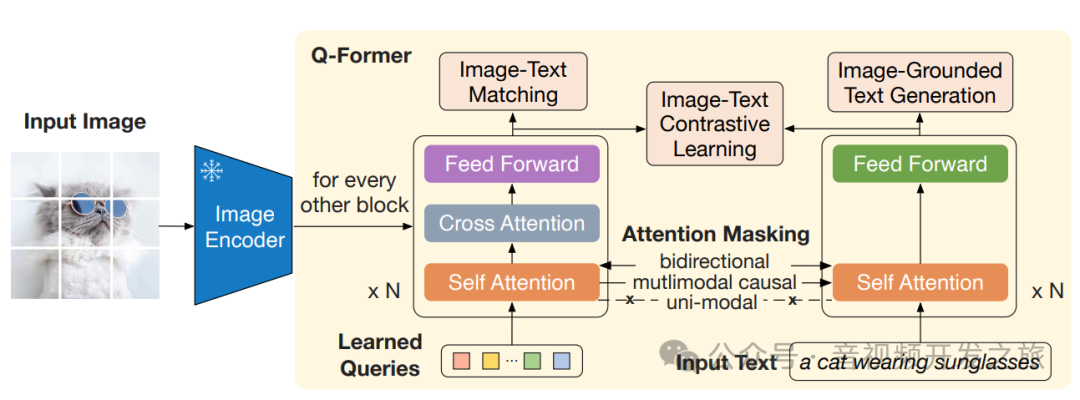
第一个阶段 ,使一组可学习的检索向量(Learned queries)从冻结的 image encoder 中来抽取与文本相关的图像特征,为此设计了三个训练目标:
-
ITC(Image-Text Contrastive Learning 图像文本对比学习):学习对齐图像和文本的特征,使得他们的交互信息最大化
-
ITG(Image-Grounded Text Generation 基于图像的文本生成):将输入的图片作为条件,训练Q-Former生成文本
-
ITM(Image-Text Matching 图像文本匹配):学习图像和文本特征之间的细粒度对齐
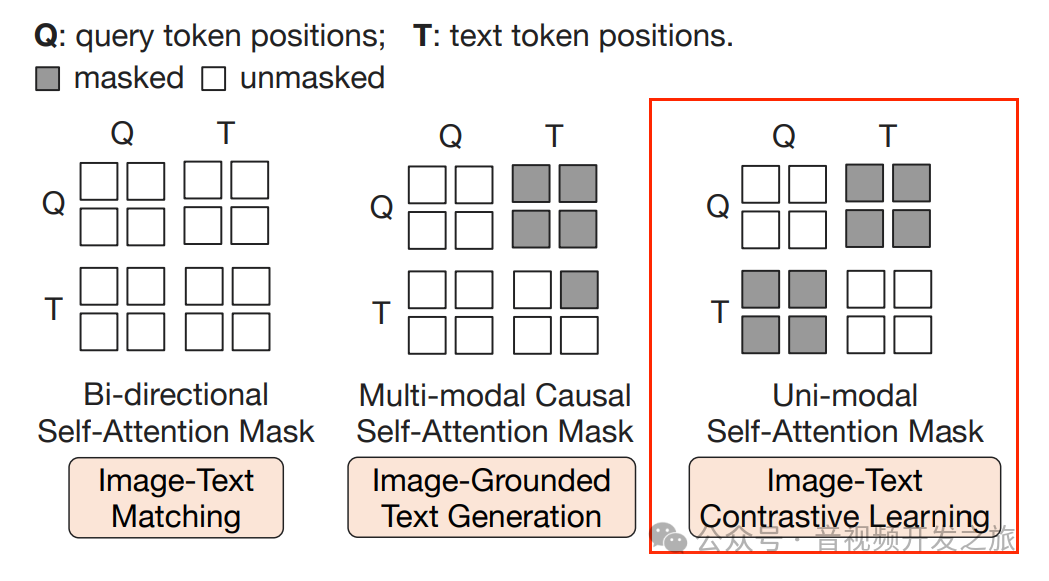
3.1.1、 ITC(Image-Text Contrastive Learning 图像文本对比学习)
将图像Transformer输出的Query representation(图像查询表征)Z 与 文本Transformer的文本表征 T 进行对齐,其中T是[CLS]的输出向量,由于Z包含多个输出向量(每个Query一个共有,Q-Former网络中有个32个Query,每个的维度768维),首先计算每个Query输出与t之间的相似度,然后选择最高的一个做为图像文本相似度。
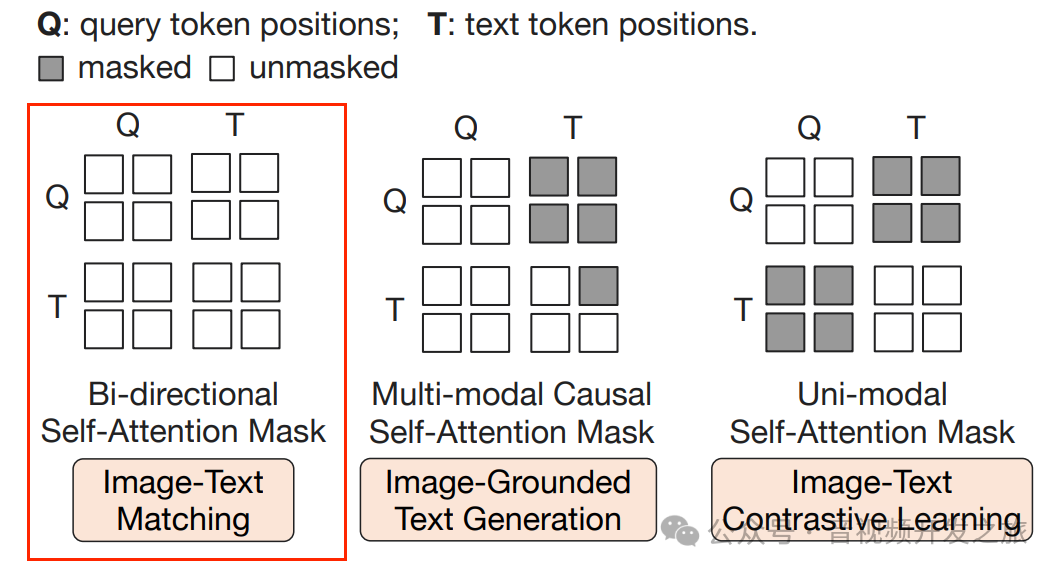
为了避免信息泄露,采用单模态的自注意力掩码,使Query 与text 相互无法看到
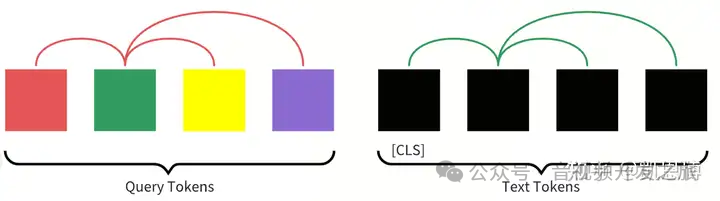
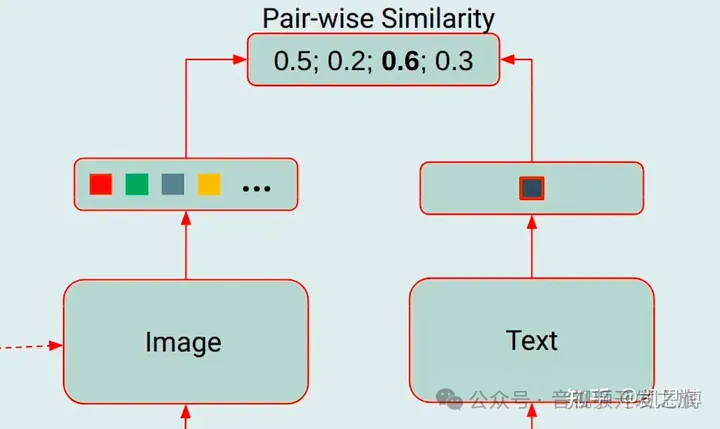
图片来自:多模态大模型系列:BLIP-2
3.1.2、ITG(Image-Grounded Text Generation 基于图像的文本生成)
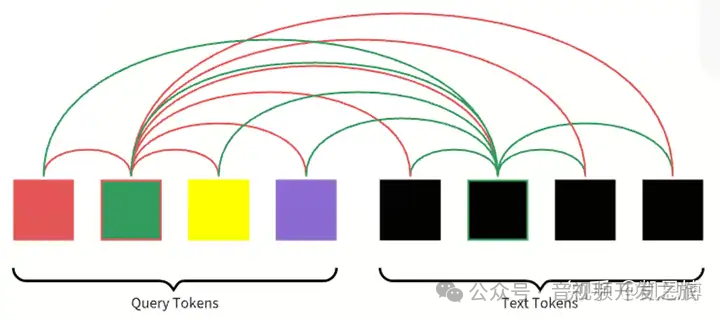
Q-Former不允许冻结的图像编码器(frozen image encoder)和文本token之间直接交互,learned queries用来提取包含相关文本信息的图像特征,然后经过self-attention传递给文本token。
使用Multimodal Causal Self-attention Mask(多模态因果自注意力Mask)来控制query-text之间的交互,Text 可以和所有的query tokens 及 当前token之前的text tokens做attention
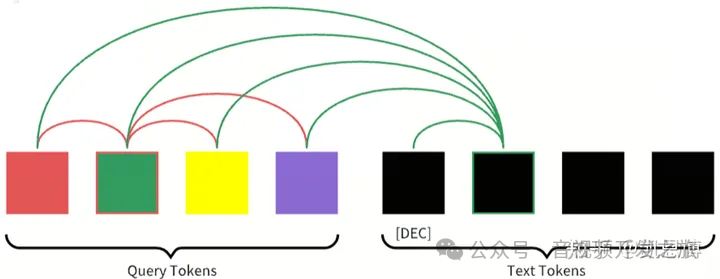
图片来自:多模态大模型系列:BLIP-2
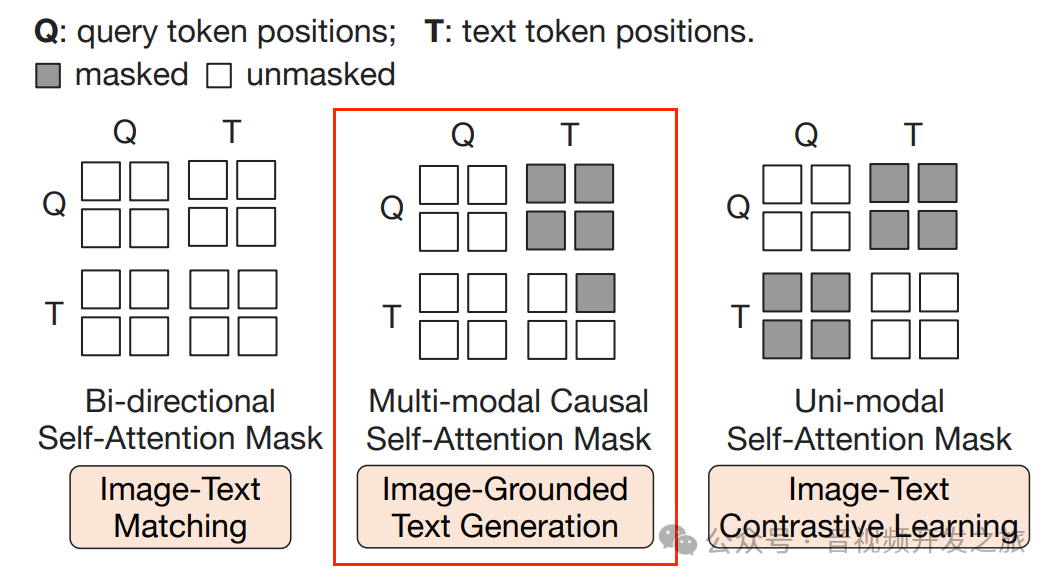
3.1.3、 ITM(Image-Text Matching 图像文本匹配)
目的是学习图像特征和文本特征之间的细粒度对齐,这是一个二分类任务,模型被要求预测图像-文本对是正样本(匹配)还是负样本(不匹配)。
使用了bi-directional self-attention mask(双向自注意力掩码),所有的Qeury和Text都可以相互关注
输出的查询向量Z(output query embeddings )能够捕获多模态信息,然后将Z输入到一个二分类线性分类器中获取一个logit,将logit平均后做为输出的匹配得分。
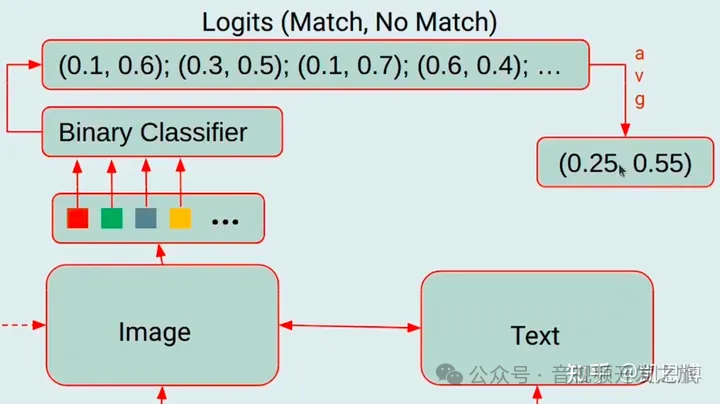
图片来自:多模态大模型系列:BLIP-2
3.2 阶段 2: Generative Learning(生成学习)
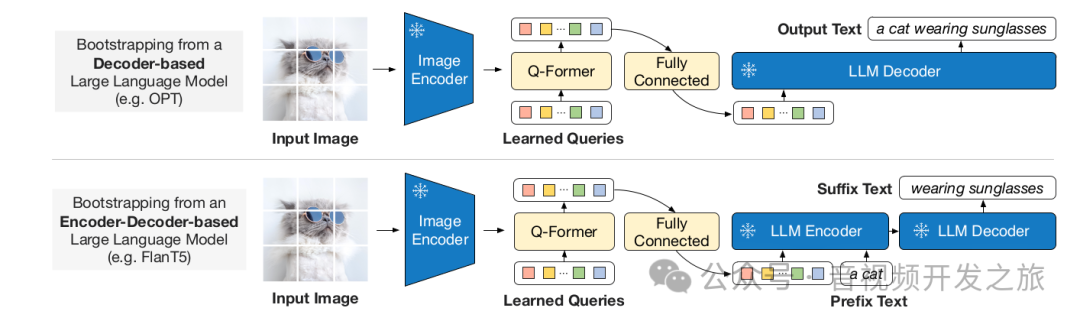
在生成任务的预训练阶段,作者将 Q-Former(已经基于 frozen image encoder 预训练过的)和 冻结的LLM 进行结合,来获得 LLM 的语言生成能力.
整个流程如下:
-
输入图像经过冻结的Image Encoder图像编码器生成原始的图像特征,
-
query tokens和Q-Former从原始图像特征中生成转换后的带文本信息的图像特征
-
将图像特征经过全连接层映射到LLM的文本embedding空间,这些映射后的图像特征就相当于视觉prompts
-
将图像特征和文本embedding一起 ,输入到冻结的LLM中,生成目标文本
其中LLM可以是Decoder类型也可以是Encoder-Decoder类型,其中通过Encoder-Decoder类型,可以使得模型具有更大的泛化能力,在模型推理阶段,可以加入任意的text prompt,生成更相关的文本。

四 、实验结果
4.1 预训练数据
(1) 129M images , 包含 COCO, Visual Genome, CC3M, CC12M, SBU
(2) 115M images, LAION400M
(3) 使用CapFilt方法生成网页图片的合成字幕,使用BLIP_large字幕模型生成10条字母,对字幕进行排序。为每张图片保留 top-2 字母,并在预训练阶段随机选择一个字幕。
4.2 预训练的image encoder和LLM
(1) 冻结的 image encoder
使用了最优的两个预训练vision transformer模型:
① ViT-L/14 from CLIP ② ViT-g/14 from EVA-CLIP
(2) 冻结的语言模型
① decoder-base LLMs : 无监督训练的OPT模型家族
② encoder-decoder-based LLMs : 基于指令训练的FlanT5模型家族
4.3 实验结果
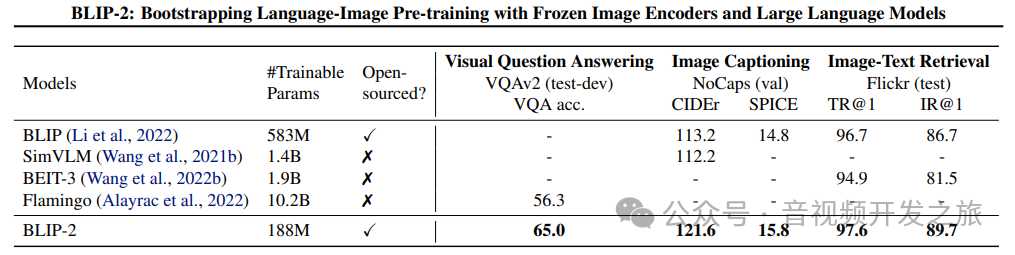
blip2使用更少的数据集,在视觉问答,图像理解,图像-文本检索任务上确定更好的结果
4.4 视觉问答的流程和代码demo
在视觉问答(Visual Question Answering VQA)任务中,blip-2结合对图像和文本的理解来回答问题,将问题Question通过文本编码器进行编码,然后和图像编码器的输出一起输入到Q-Former,Q-Former融合了图像和文本的信息,理解问题并生成答案.
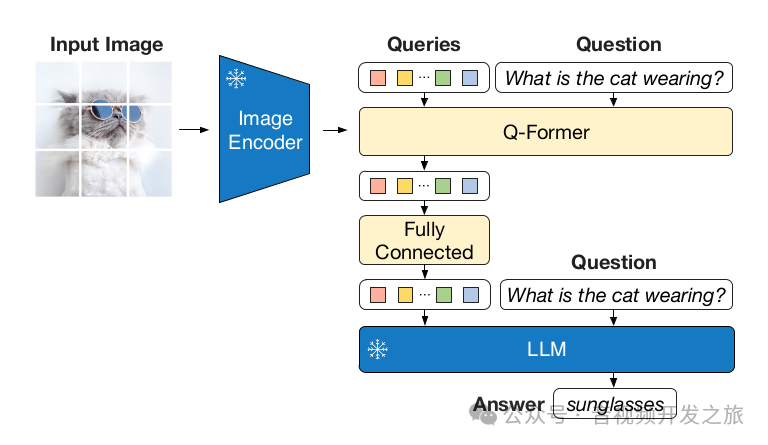
#https://huggingface.co/Salesforce/blip2-opt-2.7b/tree/mainfrom PIL import Imageimport requestsfrom transformers import Blip2Processor, Blip2ForConditionalGenerationimport torchdevice = "cuda" if torch.cuda.is_available() else "cpu"processor = Blip2Processor.from_pretrained("my_blip2/blip2-opt-2.7b")model = Blip2ForConditionalGeneration.from_pretrained("my_blip2/blip2-opt-2.7b", torch_dtype=torch.float16)model.to(device)url = "http://images.cocodataset.org/val2017/000000039769.jpg"image = Image.open(requests.get(url, stream=True).raw)inputs = processor(images=image, return_tensors="pt").to(device, torch.float16)generated_ids = model.generate(**inputs)generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()print(generated_text)
五、资料
1. blip2论文:https://arxiv.org/pdf/2301.12597
2. blip2源码:https://github.com/salesforce/LAVIS/tests/models/test_blip2.py
3. https://github.com/salesforce/LAVIS/tree/main
4. https://www.bilibili.com/video/BV1uT411q7ef
5. https://www.bilibili.com/video/BV1yw4m1a7YP
6. 多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读 https://zhuanlan.zhihu.com/p/653902791
8. 多模态学习6—深入理解BLIP-2 https://zhuanlan.zhihu.com/p/664601983
9. 多模态大模型系列:BLIP-2 https://zhuanlan.zhihu.com/p/681595636
10. BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练 https://blog.csdn.net/jiaoyangwm/article/details/130048612
11. BLIP2-图像文本预训练论文解读 https://blog.csdn.net/qq_41994006/article/details/129221701
12.一文读懂BLIP和BLIP-2多模态预训练 https://zhuanlan.zhihu.com/p/640887802
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流