图数据库的力量:深入理解与应用 Neo4j
图数据库的力量:深入理解与应用 Neo4j
文章目录
- 图数据库的力量:深入理解与应用 Neo4j
- 1、什么是 Neo4j?
- 版本说明
- 2、Neo4j 的部署和安装
- Neo4j Web 工具介绍
- 3、体验 Neo4j
- 加载数据
- 查询数据
- 数据结构
- 4、Cypher 入门
- 创建数据
- 查询数据
- 关系深度查询
- 分页查询
- 更新数据
- 删除数据
- 索引
1、什么是 Neo4j?
Neo4j 是由 Java 实现的开源 NoSQL 图数据库。自 2003 年开始开发,2007 年正式发布第一版并将源码托管于 GitHub。作为图数据库的代表产品,Neo4j 已经在众多行业项目中广泛应用,如网络管理、软件分析、组织和项目管理及社交网络等。
Neo4j 官网: https://neo4j.com/
Neo4j 提供了专业数据库级别的图数据模型存储,具备完整的数据库特性,包括 ACID 事务支持、集群支持、备份和故障转移等功能。
它还支持声明式查询语言 Cypher,这种语言类似于关系型数据库中的 SQL,操作简单,表现力强,查询效率高,且具有良好的扩展性。
下图演示了 Neo4j 的典型数据存储方式:
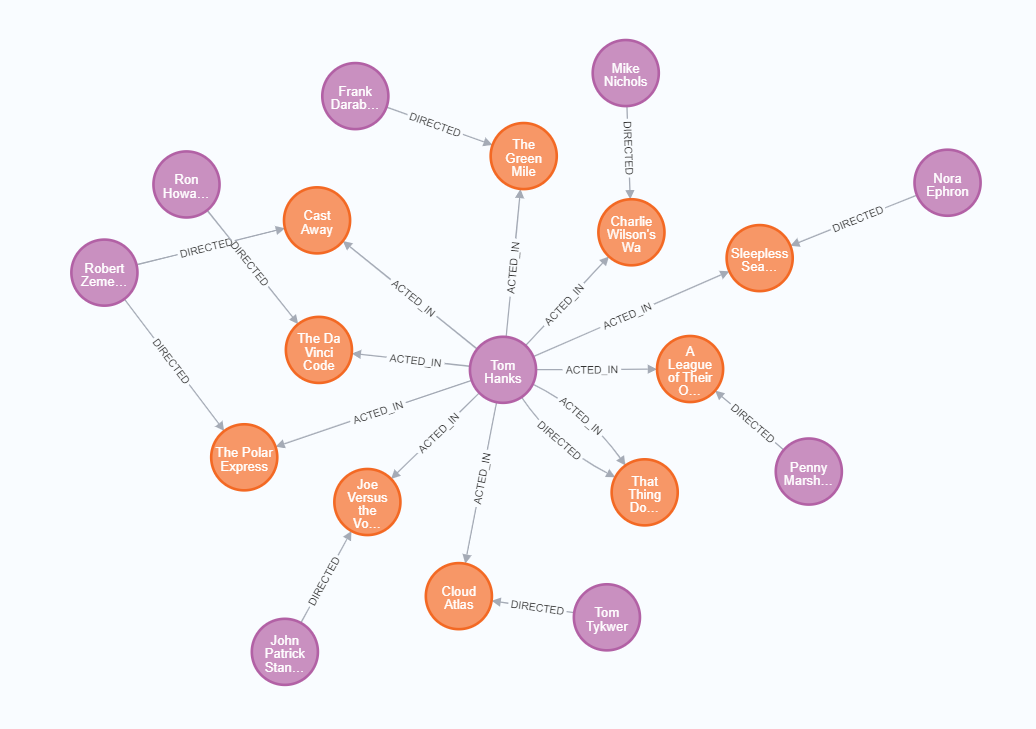
在上图中,紫色圆圈代表【人】数据,橙色圆圈代表【电影】数据,展示了人和电影之间参演或导演的关系。
版本说明
Neo4j 提供以下两个版本:
- 社区版(Community Edition):具备了基本功能,适合开发环境使用。
- 企业版(Enterprise Edition):相对于社区版增加了集群部署、高级监控、高级缓存、在线备份等功能,建议在生产环境中使用。
企业版从 3.2 版本开始支持集群,能够在不受地理位置限制的情况下实现事务 ACID 特性。更多信息请参考:Neo4j 企业版特性
2、Neo4j 的部署和安装
Neo4j 支持多个平台的部署和安装,包括 Windows、Mac 和 Linux 等系统。在安装 Neo4j 之前,请确保已安装 Java 虚拟机。
使用 Docker 进行安装的命令如下:
docker run \
-d \
--restart=always \
--name neo4j \
-p 7474:7474 \
-p 7687:7687 \
-v neo4j:/data \
neo4j:4.4.5# 7474 是 web 管理工具的端口,7687 是 Neo4j 协议端口用于数据通信
Neo4j Web 工具介绍
Neo4j 提供了一个便捷的 Web 工具,可以进行数据库的 CRUD 操作。
3、体验 Neo4j
以下是通过官方提供的电影数据来实战体验 Neo4j 的步骤:
加载数据
首先,选择并加载数据:
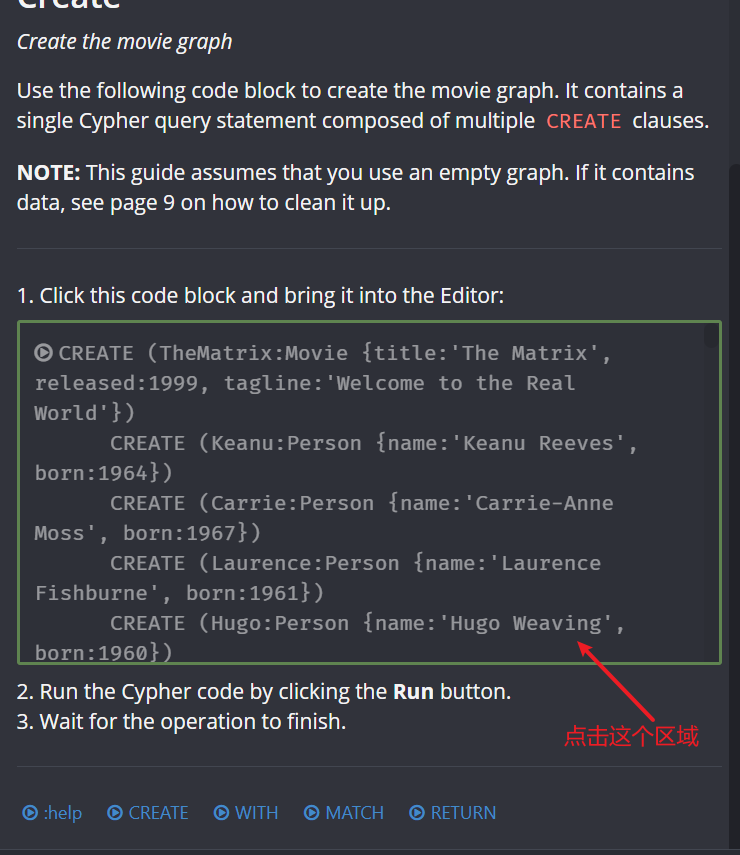
系统会自动将创建数据的 Cypher 语句加载到输入框中,点击执行:
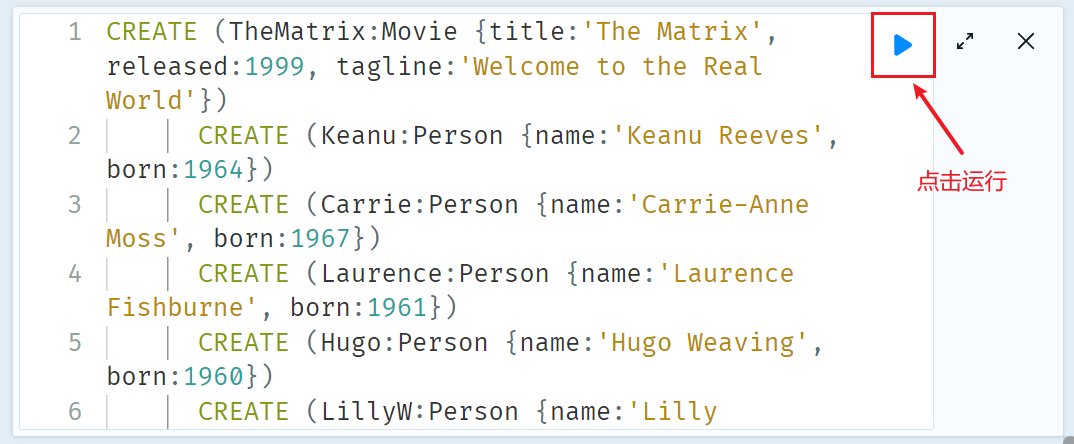
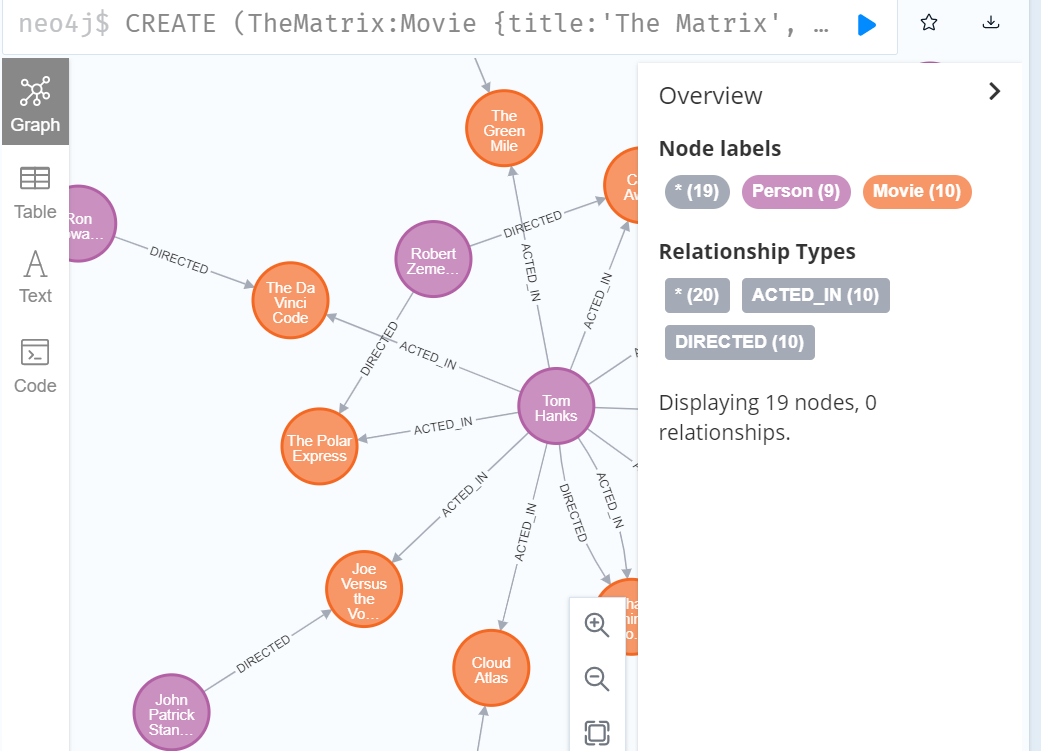
执行成功后,可以看到数据已经成功导入:
查询数据
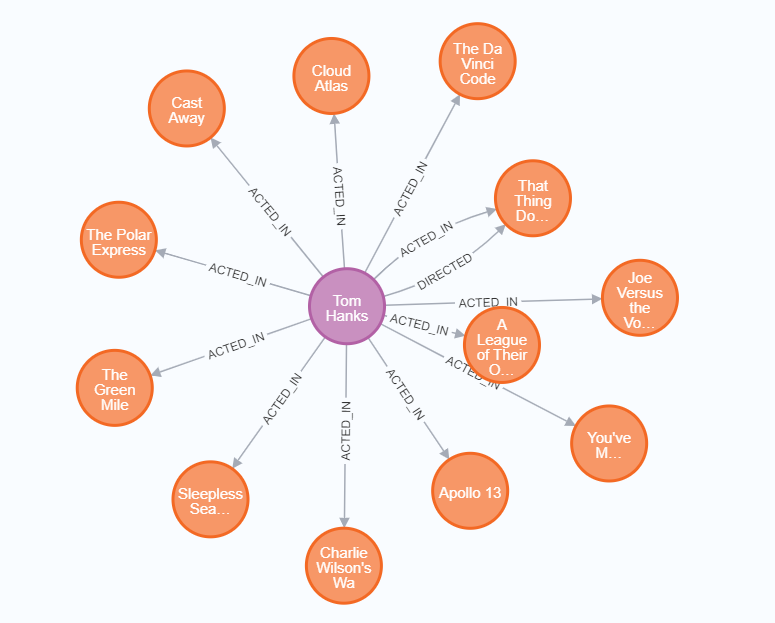
例如,查询【Tom Hanks】参演了哪些电影的 Cypher 语句如下:
MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(tomHanksMovies) RETURN tom, tomHanksMovies
查询结果如下图所示:
数据结构
在 Neo4j 中,数据通过节点、属性、关系和标签来存储。以下是具体说明:
- 节点:存储实体数据(如上图中的演员和电影),类似于关系型数据库中的表。
- 关系:存储节点之间的关系。每个关系只能有一个类型,必须有开始和结束节点,并且可以循环引用,但不能留空。
- 属性:节点和关系都可以有属性,由键值对组成。节点的属性类似于关系型数据库中的字段,而关系属性则进一步明确了关系属性。
- 标签:用于对节点进行分类,使 Neo4j 数据模型更易于构建。在上面的电影案例中,Movie 和 Person 即是标签。
4、Cypher 入门
Cypher 是 Neo4j 的查询语言,类似于关系型数据库中的 SQL,一些关键词来源于 SQL,比如:CREATE、WHERE、RETURN 等。下面我们一起学习 Cypher 的基本语句。
Cypher 语句的关键字对大小写不敏感。
创建数据
// 查询所有数据
MATCH (n) RETURN n// 删除所有节点和关系,慎用!
MATCH (n) DETACH DELETE n// 创建一个具有 name 属性的节点,变量 n 代表该节点,创建完成后返回该节点
CREATE (n {name: $value}) RETURN n// 创建一个指定标签($Tag)的节点
CREATE (n:$Tag {name: $value})// 创建 n 指向 m 的关系,并且指定关系类型为 KNOWS
CREATE (n)-[r:KNOWS]->(m)// 示例
// 创建节点,并赋予 name 属性
CREATE (n {name:'迪士尼营业部'})
CREATE (n:AGENCY {name:'航头营业部'})// 创建浦东新区转运中心、上海转运中心节点,并且创建关系类型为 IN_LINE,创建完成后返回节点和关系
// TLT -> Two Level Transport(二级转运中心)
// OLT -> One Level Transport(一级转运中心)
CREATE (n:TLT {name:'浦东新区转运中心'}) -[r:IN_LINE]-> (m:OLT {name:'上海转运中心'}) RETURN n,r,m// 关系可以是反向的,并且可以为关系指定属性
CREATE (n:TLT {name:'浦东新区转运中心'}) <-[r:OUT_LINE]- (m:OLT {name:'上海转运中心'}) RETURN n,r,m
在上面的示例中,我们先后创建了节点、指定标签的节点以及带有特定关系类型的节点。示例代码展示了如何创建双向关系,并且为关系指定属性。
查询数据
// 匹配某个条件的节点
MATCH (n:AGENCY {name: "航头营业部"}) RETURN n// 查询具有一定条件的节点及其关系,并按照一定顺序返回数据
MATCH (n)-[:KNOWS]->(m) WHERE m.name = "Tom Hanks" RETURN n, m ORDER BY n.name ASC
关系深度查询
可以指定关系的深度进行查询,语法格式:-[:TYPE*minHops..maxHops]->
例如,六度分隔(Six Degrees of Separation)理论表明,你和任何一个陌生人之间所间隔的中间人不会超过六个,也就是说,最多通过六个人你就能认识任何一个陌生人。
// 查询【北京市转运中心】关系中深度为 1~2 层的节点
MATCH (n:OLT {name:"北京市转运中心"}) -[*1..2]->(m) RETURN *// 可以简写为
MATCH (n:OLT {name:"北京市转运中心"}) -[*..2]->(m) RETURN *// 通过变量查询
MATCH path = (n:OLT {name:"北京市转运中心"}) -[*..2]->(m) RETURN path// 获取结果中的关系,WITH 语句将结果传递给下一个查询
MATCH path = (n:OLT {name:"北京市转运中心"}) -[*..2]->(m)
WITH n, m, relationships(path) AS r
RETURN r// 查询两个网点之间所有的路径,最大深度为 6
MATCH path = (n:AGENCY) -[*..6]->(m:AGENCY)
WHERE n.name = "北京市昌平区定泗路" AND m.name = "上海市浦东新区南汇"
RETURN path// 查询两个网点之间的最短路径,查询深度最大为 10
MATCH path = shortestPath((n:AGENCY) -[*..10]->(m:AGENCY))
WHERE n.name = "北京市昌平区定泗路" AND m.name = "上海市浦东新区南汇"
RETURN path// 查询两个网点之间所有路径中成本最低的一条路径,最大深度为 10
MATCH path = (n:AGENCY) -[*..10]->(m:AGENCY)
WHERE n.name = "北京市昌平区定泗路" AND m.name = "上海市浦东新区南汇"
UNWIND relationships(path) AS r
WITH sum(r.cost) AS cost, path
RETURN path ORDER BY cost ASC, LENGTH(path) ASC LIMIT 1// UNWIND 将列表数据展开
// sum() 是聚合函数,类似的还有 avg()、max()、min() 等
分页查询
// 分页查询网点,按照 bid 正序排序,每页查询 2 条数据// 第一页
MATCH (n:AGENCY)
RETURN n ORDER BY n.bid ASC SKIP 0 LIMIT 2// 第二页
MATCH (n:AGENCY)
RETURN n ORDER BY n.bid ASC SKIP 2 LIMIT 2
更新数据
更新数据使用 SET 语句进行标签、属性的更新。SET 操作是幂等性的。
// 更新或设置属性
MATCH (n:AGENCY {name:"北京市昌平区新龙城"})
SET n.address = "龙跃苑四区3号楼底商101号"
RETURN n// 移除属性
MATCH (n:AGENCY {name:"北京市昌平区新龙城"})
REMOVE n.address
RETURN n// 给没有 address 属性的节点增加 address 属性
MATCH (n:AGENCY)
WHERE n.address IS NULL
SET n.address = "暂无地址"
RETURN n
删除数据
删除数据通过 DELETE 和 DETACH DELETE 完成。DELETE 不能删除有关系的节点,删除关系需要使用 DETACH DELETE。
// 删除节点
MATCH (n:AGENCY {name:"航头营业部"})
DELETE n// 有关系的节点不能直接删除
MATCH (n:AGENCY {name:"北京市昌平区新龙城"})
DELETE n// 删除节点及其所有关系
MATCH (n:AGENCY {name:"北京市昌平区新龙城"})
DETACH DELETE n// 删除所有节点和关系,慎用!
MATCH (n)
DETACH DELETE n
索引
给节点添加索引以提高查询效率。
// 创建索引语法
CREATE [TEXT] INDEX [index_name] [IF NOT EXISTS]
FOR (n:LabelName)
ON (n.propertyName)
[OPTIONS "{" option: value[, ...] "}"]// 示例
CREATE TEXT INDEX agency_index_bid IF NOT EXISTS FOR (n:AGENCY) ON (n.bid)// 删除索引语法
DROP INDEX [index_name]// 示例
DROP INDEX agency_index_bid
通过对 Neo4j 的深入理解与应用,图数据模型的强大优势得以展现。无论是复杂关系存储还是高效查询,Neo4j 都表现出色。希望这些详细的示例和说明能帮助你更好地掌握 Neo4j,为实际项目应用打下坚实基础。