PointNet++改进策略 :模块改进 | PointNetXt ,利用训练测量大幅提升PointNet模型性能

- 论文题目:PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
- 发布期刊:NeurIPS
- 通讯地址:1阿卜杜拉国王科技大学 (KAUST)、2微软研究院
- 代码地址:https://github.com/guochengqian/pointnext
介绍
这篇名为《PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies》的论文主要讨论了对经典的3D点云网络架构PointNet++进行的改进。作者提出了新的训练策略和模型扩展方法,旨在提高PointNet++的性能。论文的核心观点和贡献包括:
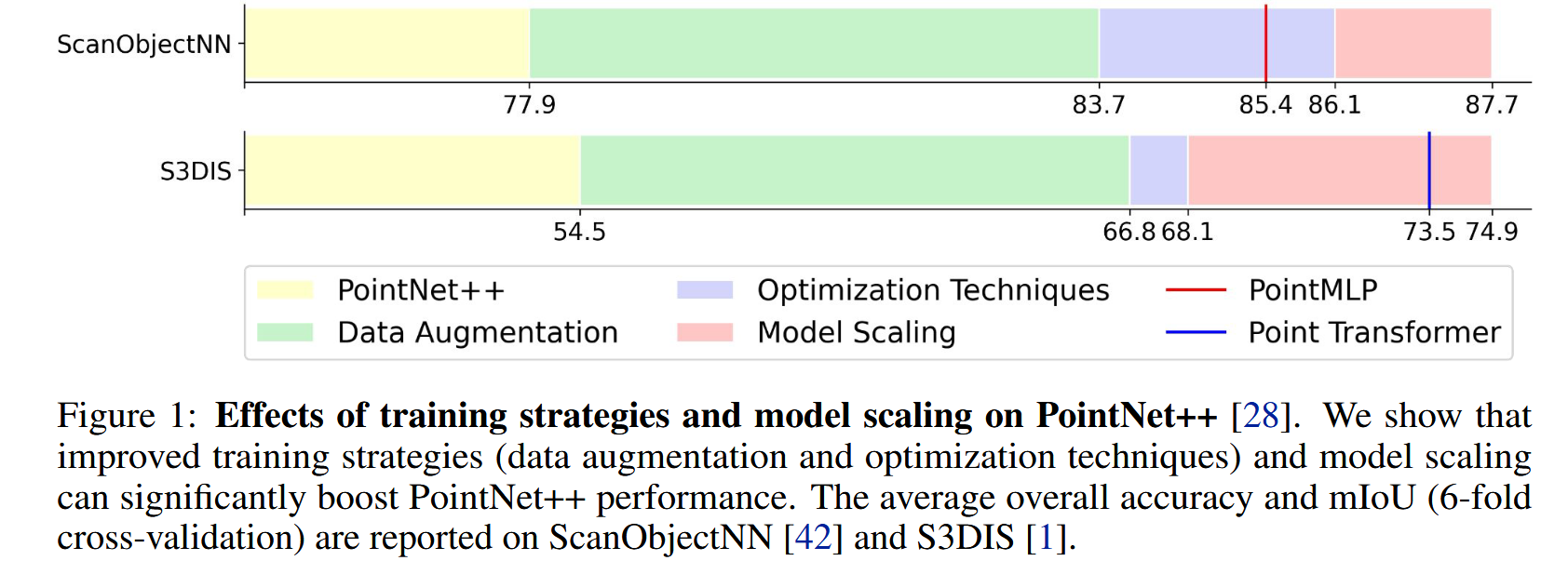
- 改进训练策略:通过系统地研究数据增强和优化技术,作者发现很多新网络(如PointMLP和Point Transformer)性能提升主要是由于更好的训练策略而非架构上的创新。因此,作者提出了一组改进的训练方法,使得PointNet++的性能大幅提升。例如,在ScanObjectNN数据集上的分类准确率从77.9%提升至86.1%,超越了最新的PointMLP方法。
- 引入PointNeXt架构:作者通过在PointNet++中引入倒置残差瓶颈设计和可分离MLP(多层感知机),提出了新架构PointNeXt。PointNeXt可以进行灵活的模型扩展,在3D分类和分割任务中超越了最先进的模型,并且推理速度更快。
- 系统性分析与实验验证:通过在多个基准数据集上的实验,如ScanObjectNN、S3DIS等,论文证明了改进训练策略和模型扩展的有效性。PointNeXt在语义分割任务中达到了新的SOTA(State-of-the-art)水平,并且在分类任务中比PointMLP快10倍。
核心思想及其实现
PointNeXt的核心思想是在经典的3D点云处理架构PointNet++的基础上,通过改进训练策略和模型扩展方法,充分挖掘其潜力,使其能够达到并超越当前最先进的方法(SOTA),而不依赖于复杂的架构创新。
- 优化训练策略:许多现代3D点云网络(如PointMLP、Point Transformer)性能的提升更多依赖于训练策略的改进,而非架构上的重大变革。因此,PointNeXt通过系统研究现代训练方法,尤其是数据增强和优化技术,来提升PointNet++的表现。
- 模型扩展与优化:PointNet++的原始架构虽然有效,但其规模较小,难以适应更大规模的数据或更复杂的任务。因此,PointNeXt通过在架构上引入倒置残差瓶颈(Inverted Residual Bottleneck)和可分离MLP(Separable MLP),使得模型能够更有效地扩展,同时提高性能和推理速度。
优化训练策略
- 训练现代化(Training Modernization):
- 数据增强:作者系统性地研究了各种数据增强策略的影响,包括点采样(point resampling)、高度附加(height appending)、随机颜色丢弃(color drop)等。这些策略可以显著提升PointNet++在不同任务上的表现。
- 优化技术:通过优化损失函数、优化器(如AdamW取代Adam)和学习率调度器(如Cosine Decay),进一步提升了模型的训练效果。比如,使用标签平滑(label smoothing)可以提高分类任务的准确率。
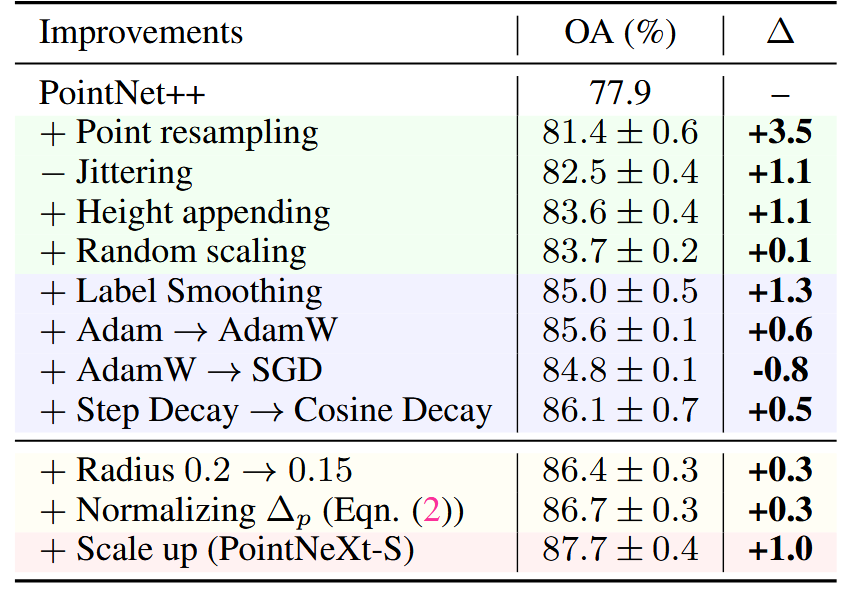
表在 ScanObjectNN 上顺序应用训练和缩放策略进行分类的附加研究。我们使用浅绿色、紫色、黄色和粉色背景颜色分别表示数据增强、优化技术、感受野缩放和模型缩放。
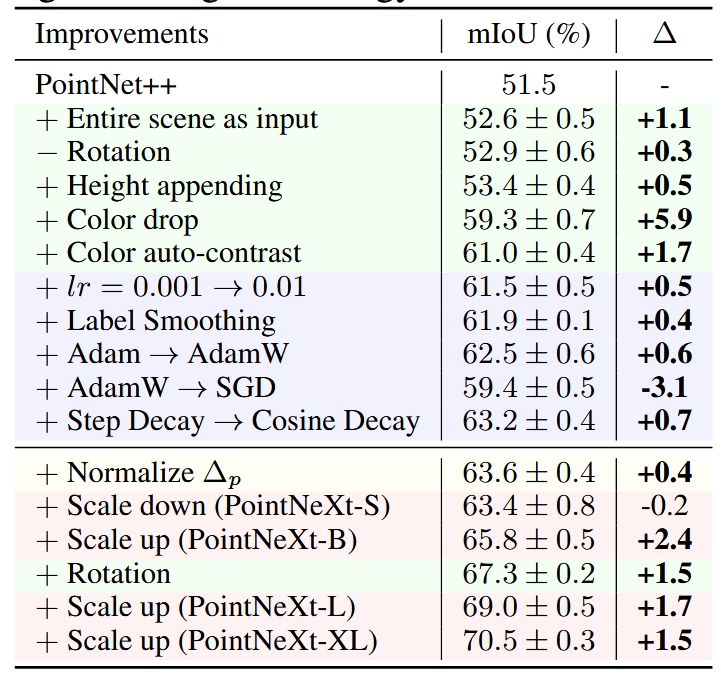
表在 S3DIS area 5 上顺序应用训练和缩放策略进行分割的附加研究。+/- 表示采用/删除策略。
PointNetXt架构
- 架构现代化(Architecture Modernization):
- 感受野扩展:通过调整查询邻域的半径和使用相对位置归一化(Relative Position Normalization),增加网络的感受野,使其能够更好地捕捉局部几何信息。
- 模型扩展:
- 倒置残差瓶颈(Inverted Residual Bottleneck):在原始PointNet++的“Set Abstraction”模块中引入了残差连接,解决梯度消失问题,允许更深的网络训练。并通过倒置残差设计,扩展MLP层的输出通道以丰富特征表示。
- 可分离MLP(Separable MLP):通过将原有MLP分离为处理邻域特征和点特征的单独层,减少计算量并提高模型的效率。
- 宏观架构调整:统一了分类和分割任务中的编码器设计,并加入了额外的MLP层来增强输入特征的表示能力。
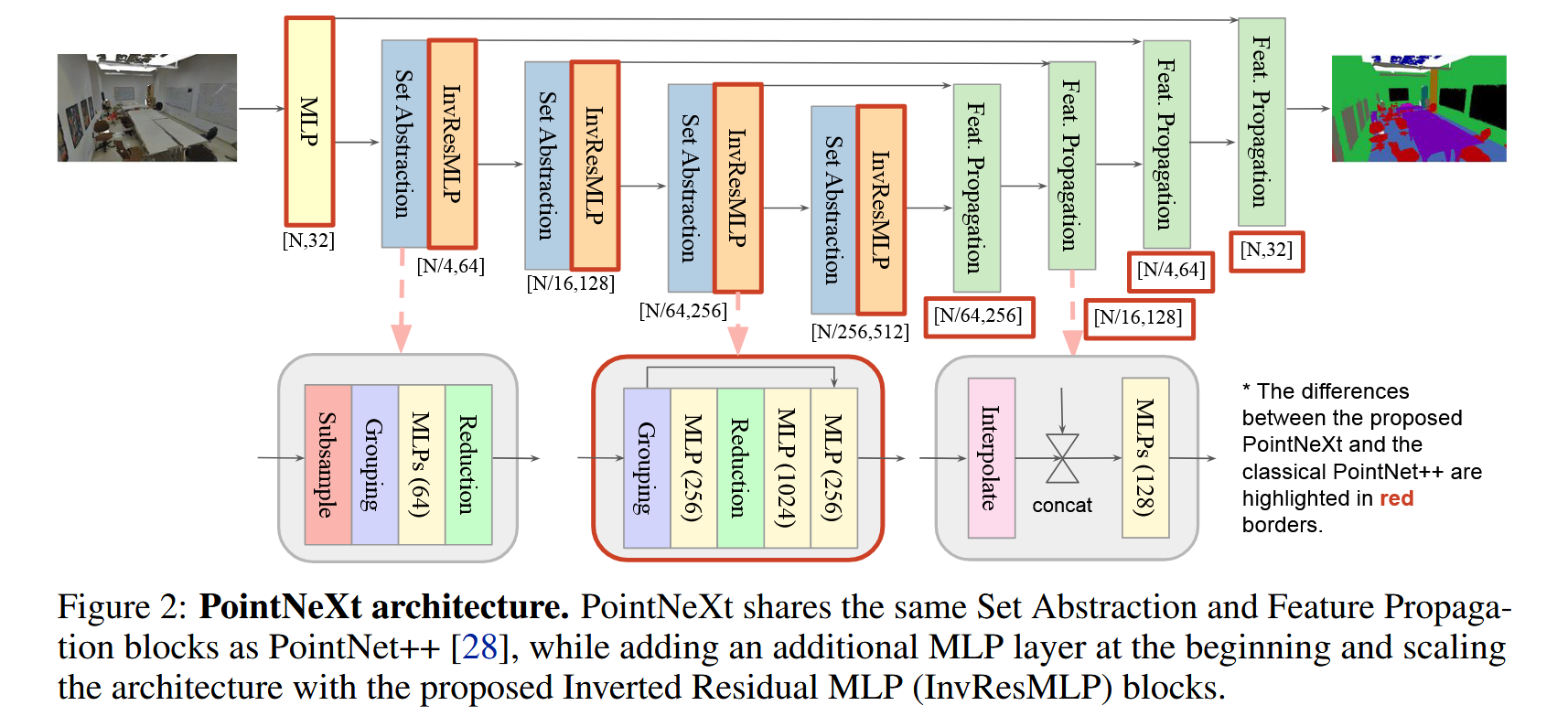
模型变体的设计
根据需求和任务的复杂度,PointNeXt设计了不同规模的变体,如PointNeXt-S、PointNeXt-B、PointNeXt-L等,通过调整模型的宽度(通道数)和深度(层数),实现灵活的扩展,适应不同的3D点云任务。
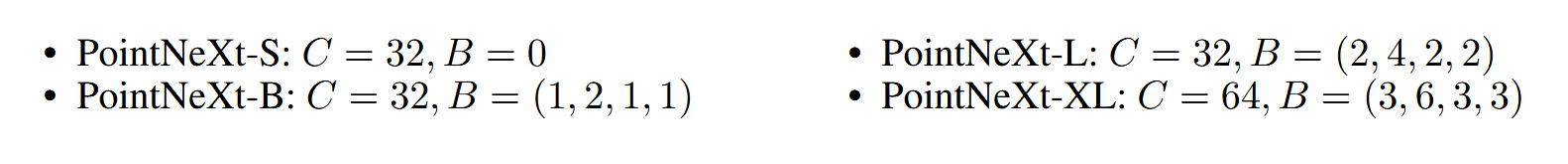
如何改进PointNet++
要利用PointNeXt的思想改进PointNet++,可以从以下几个方面入手,通过优化训练策略和模型架构来提升PointNet++的性能:
改进训练策略
训练策略的优化是PointNeXt提升性能的关键因素之一。通过以下几种方法可以显著提高PointNet++的表现:
数据增强使用更强大的数据增强方法来提升模型的泛化能力。具体策略包括:
- 点采样(Point Resampling):在训练期间随机采样点云中的点数,并在测试时使用均匀采样。这可以提高模型对不同点云分布的鲁棒性。
- 高度附加(Height Appending):为点云中的每个点增加一个高度维度,使模型能够感知点云的空间分布。
- 随机颜色丢弃(Color Drop):对点云中的颜色信息进行随机丢弃,迫使模型更加关注几何结构而非颜色,从而提高模型的泛化能力。
- 随机旋转、缩放、平移:对点云进行随机的旋转、缩放和平移,增加训练数据的多样性。
使用更先进的优化技术来提高模型的训练效果:
- 标签平滑(Label Smoothing):在训练过程中加入标签平滑技术,可以减少模型过拟合,并提高分类任务的表现。
- AdamW优化器:相比于传统的Adam优化器,AdamW可以更好地控制权重衰减,从而提升模型的泛化能力。
- Cosine Decay学习率调度器:使用Cosine Decay替代Step Decay,以更平滑地调整学习率,从而提高模型的收敛速度和性能。
架构优化
在模型架构方面,PointNeXt通过对PointNet++的扩展和改进,实现了更高的性能。可以参考以下几种方法来改进PointNet++的架构:
倒置残差瓶颈(Inverted Residual Bottleneck)
在PointNet++的每个Set Abstraction(SA)模块中引入倒置残差瓶颈设计:
- 残差连接(Residual Connections):通过加入残差连接,可以缓解梯度消失问题,允许网络变得更深而不会影响性能。
- 倒置残差设计:在MLP层中扩展特征维度,然后再进行降维处理,使得网络可以更有效地提取丰富的特征。
可分离MLP(Separable MLP)
在PointNet++的MLP层中引入可分离MLP设计,降低计算复杂度并提升特征提取的效率:
- 邻域特征与点特征分离:将MLP分为处理邻域特征的层和处理单点特征的层,从而降低计算成本,并提升模型对几何结构的处理能力。
感受野扩展
通过扩展感受野来提升PointNet++在捕捉局部几何结构时的表现:
- 查询邻域半径缩放:针对不同数据集的特点,调整查询邻域的半径大小,使模型能够更好地捕捉到有效的局部信息。
- 相对位置归一化(Relative Position Normalization):将相对坐标归一化处理,使模型的优化过程更加稳定。
宏观架构调整
可以对PointNet++的宏观架构进行一些调整,使其更具扩展性:
- 增加更多的层数:在分类任务中,PointNet++的编码器只有2个阶段,而分割任务中有4个阶段。可以在分类任务中增加更多的Set Abstraction层,以增强模型的表示能力。
- 对称的解码器:在解码器部分调整通道大小,使其与编码器保持一致,从而增强信息恢复的能力。
- 引入初始MLP层:在输入点云进入网络之前,添加一个额外的MLP层,将点云特征映射到更高维度,有助于提升后续层的特征提取效果。
模型扩展
根据任务的需求,PointNeXt提供了灵活的模型扩展方案。你可以通过调整以下两个方面来扩展PointNet++的模型规模:
- 深度扩展:增加更多的网络层(如增加SA层或倒置残差瓶颈层),让模型变得更深,以提取更复杂的特征。
- 宽度扩展:增加每层的通道数,使网络能够处理更多的特征信息。