深度学习--循环神经网络RNN
文章目录
- 前言
- 一、RNN介绍
- 1、传统神经网络存在的问题
- 2、RNN的核心思想
- 3、 RNN的局限性
- 二、RNN基本结构
- 1、RNN基本结构
- 2、推导
- 3、注意
- 4、循环的由来
- 5、再谈RNN的局限
- 总结
前言
循环神经网络(RNN)的起源可以追溯到1982年,由Saratha Sathasivam提出的霍普菲尔德网络(Hopfield network)。 然而,早期的RNN结构相对简单,且在实际应用中受到了一定的限制。 随着深度学习技术的不断发展,RNN模型在结构和性能上得到了显著的改进,成为处理序列数据的强大工具。
一、RNN介绍
RNN(Recurrent Neural Network,循环神经网络)是一种用于处理序列数据的神经网络架构。其在处理序列输入时具有记忆性,可以保留之前输入的信息并继续作为后续输入的一部分进行计算。
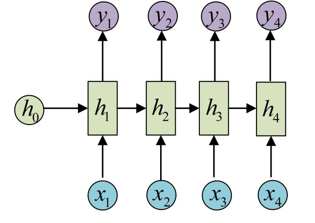
如上图所示,假如有一句话,“今天周六不上班”,将其分词成“今天”、“周六”、“不”、“上班”,第一个词的词向量表示x1,第二个单词的词向量表示为x2,依次表示所有x,然后首先第一个词向量x1传入h1,然后偏置项h0也同步传入,得到一个结果再传入h2,h2再得到传入的x2传入h3…,继续像上述流程一样,以此保存了所有的信息并得到最终结果。
1、传统神经网络存在的问题
- 无法训练出具有顺序的数据。模型搭建时没有考虑数据上下之间的关系。
2、RNN的核心思想
-
循环结构:RNN通过隐藏态h(Hidden State)在不同参数之间传递信息,使网络具备记忆能力。当前步骤的输入不仅包括当前数据,还包含上一步的隐藏状态,从而保留数据信息。
-
参数共享:所有参数共享相同的权重参数
3、 RNN的局限性
-
长距离依赖问题:长序列中早期信息难以传递到后续步骤,因梯度消失/爆炸导致训练困难。
-
梯度消失:反向传播时梯度随时间步指数衰减,参数无法更新。
-
梯度爆炸:梯度指数增长,导致数值溢出。
二、RNN基本结构
1、RNN基本结构
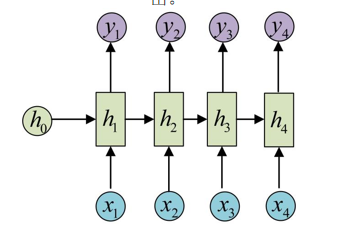
- 下方蓝色的是输入层,
- 中间的矩形是隐藏层,
- 上方紫色的是输出层
2、推导
如下图所示,隐状态h相当于一个函数,f为一个激活函数,其有中的参数U、W、b在每一步都是一样的。
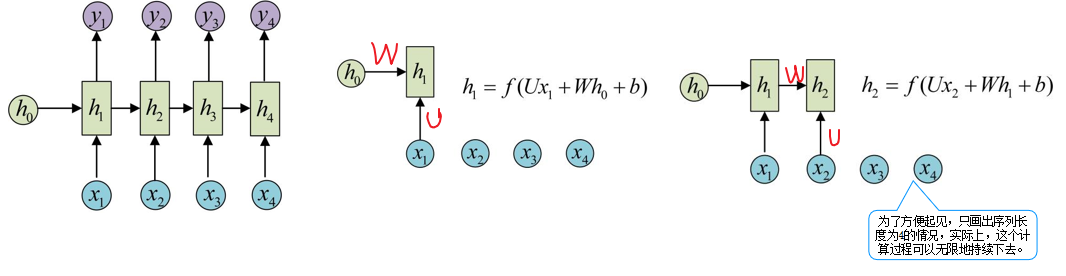
h0乘以一个参数矩阵W加上x1乘以一个参数矩阵U;
再加一个偏置项b,得到一个结果;
将这个结果传入激活函数f,进行特征提取;
h1.h2…hx如是,继续叠加。
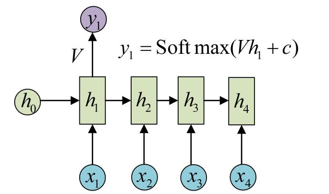
对于结果y也会乘以一个矩阵V,加上偏置c后传入一个Softmax交叉熵损失函数,一般情况下y1的用处不大,最重要的是最后一个,例如下图的y4,因为y4涵盖了前面所有的词的特征。
3、注意
- RNN结构中输入是x1, x2, …xn,输出为y1, y2, …yn,也就是说,输入和输出序列必须要是等长的。
- 每一次训练中计算用的u,v,w,b都是一样的 ,训练完反向传播会进行更新。
4、循环的由来
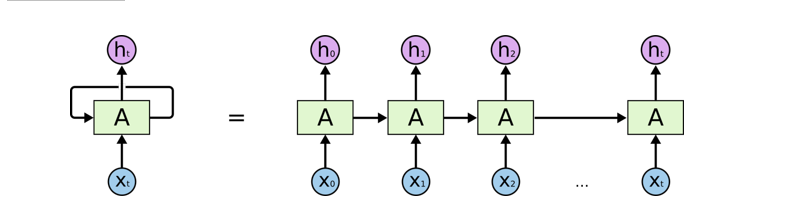
5、再谈RNN的局限
-
当出现“我的职业是程序员,…,我最擅长的是电脑”。需要预测最后的词“电脑”。
-
当前的信息建议下一个词可能是一种技能,但是如果我们需要弄清楚是什么技能,需要先前提到的离当前位置很远的“职业是程序员”的上下文。
-
这说明相关信息和当前预测位置之间的间隔就变得相当的大。
-
在理论上,RNN绝对可以处理这样的长期依赖问题。
-
人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN则没法太好的学习到这些知识。
-
这使得模型难以学习长距离依赖关系
原因是:梯度会随着时间的推移不断下降减少,而当梯度值变得非常小时,就不会继续学习。
总结
阅读本篇会发现RNN有很多问题, 改进方案:LSTM与GRU,之后会讲^^。