python_BeautifulSoup提取html中的信息
目录
描述:
过程:
step one 下载html网页到本地
step two 提取html信息
list_con = soup.select('.list-con') [0]
li_list = list_con.find_all('li')
a = li.find('span').find('a')
title = a.get('title')
url = a.get('href')
span = li.find('span').find('span')
time_str = span.string
BeautifulSoup常用方法
视频
描述:
提取 同花顺|期货 期货滚动 的资讯列表信息,使用BeautifulSoup提取html信息
期货滚动_期货_同花顺财经
过程:
step one 下载html网页到本地
def temp_000():pre_dir =r'E:/temp006/'url = r'https://goodsfu.10jqka.com.cn/qhgd_list/index_1.shtml'header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'}response = requests.get(url,headers=header)if response.status_code == 200:with open(pre_dir + '1.html','w',encoding='utf-8') as fw:fw.write(response.text)pass
step two 提取html信息
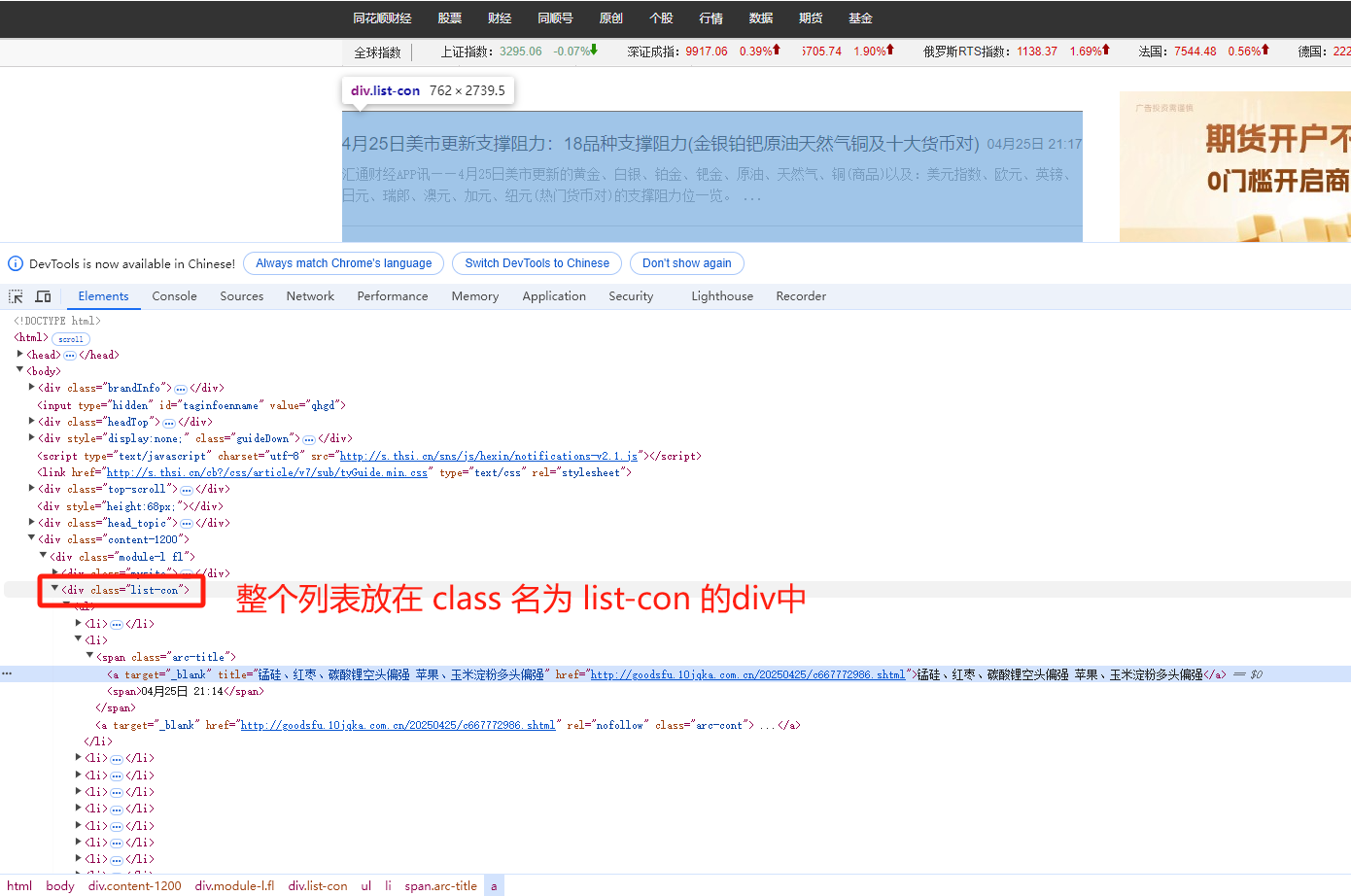
def temp_001():file_path = r'E:/temp006/1.html'with open(file_path,'r',encoding='utf-8') as fr:content = fr.read()soup = BeautifulSoup(content,'lxml')elements = soup.select('.list-con')list_con = elements[0]li_list = list_con.find_all('li')data_list = []for li in li_list:a = li.find('span').find('a')url = a.get('href')title = a.get('title')span = li.find('span').find('span')time_str = span.stringdata_list.append({'title':title,'url':url,'time_str':time_str})passprint(data_list)pass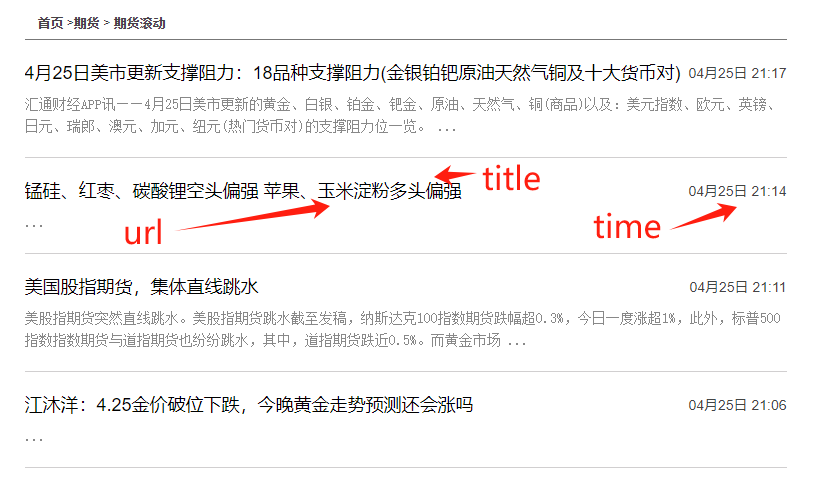
list_con = soup.select('.list-con') [0]
soup.select('.list-con') 获取class名为list-con的节点列表,返回结果是个列表,取返回列表的第一个,是要提取的目标列表
li_list = list_con.find_all('li')
获取 list_con 节点里的所有 li 节点
遍历 li 节点
a = li.find('span').find('a')

获取 li 节点里的第一个 span 节点,再在该 span 节点里寻找第一个 a 节点
title = a.get('title')
获取 a 节点里的 title 信息
以上面截图为例 title = '锰硅、红枣、碳酸锂空头偏强 苹果、玉米淀粉多头偏强'
url = a.get('href')
获取 a 节点里的 url 信息
以上面截图为例 url ="http://goodsfu.10jqka.com.cn/20250425/c667772986.shtml"
span = li.find('span').find('span')
获取 li 节点里的第一个 span 节点,再在该 span 节点里获取第一个 span 节点
time_str = span.string
获取 <span>xxxxxx</span> 之间的 xxxxxx 字符
以上面截图为里 time_str = "04月25日 21:14"
BeautifulSoup常用方法
soup.title # 获取整个title标签字段:<title>The Dormouse's story</title>
soup.title.name # 获取title标签名称 :title
soup.title.parent.name # 获取 title 的父级标签名称:head
soup.p # 获取第一个p标签字段:<p class="title"><b>The Dormouse's story</b></p>
soup.p['class'] # 获取第一个p中class属性值:title
soup.p.get('class') # 等价于上面
soup.a # 获取第一个a标签字段
soup.find_all('a') # 获取所有a标签字段
soup.find(id="link3") # 获取属性id值为link3的字段
soup.a['class'] = "newClass" # 可以对这些属性和内容等等进行修改
del bs.a['class'] # 还可以对这个属性进行删除
soup.find('a').get('id') # 获取class值为story的a标签中id属性的值
soup.title.string # 获取title标签的值 :The Dormouse's story
视频
python_BeautifulSoup提取html中的信息_哔哩哔哩_bilibili